Django+uwsgi+nginx 配置示例
环境信息
- centos 7
- Python 3.10
- Django 4.0
- uwsgi 2.0.20
- nginx 1.20.1
- venv
示例中虚拟环境位于
/opt/vb/, Django工程目录位于/opt/vb/vb/, 工程名称为vb
uwsgi 配置文件 (uwsgi.ini) 配置示例
[uwsgi] |
示例中虚拟环境位于
/opt/vb/, Django工程目录位于/opt/vb/vb/, 工程名称为vb
[uwsgi] |
Outline 是由附属于 Google 的 Jigsaw 开发的开源的 VPN 软件。它的设计目标是为了实现 VPN 的简单部署和管理以及安全。Outline 提供了强加密、用户管理工具、并支持多平台,包括 Windows, macOS, Linux, iOS, 和 Android。
Outline 主要由 2 部分组成:
Outline Manager : 用来部署 VPN 服务器,以及管理用户、限速等Outline Client : 连接 VPN 的客户端,支持多平台本文示例基本环境信息 :
Outline Manager 部署非常的简单,只需要下载可执行文件,添加可执行权限并启动即可
wget https://s3.amazonaws.com/outline-releases/manager/linux/stable/Outline-Manager.AppImage |
为安全起见,Outline Manager 不支持以
root用户执行,请以普通用户身份执行Outline Manager 依赖于
fuse,执行命令sudo apt install fuse安装Outline VPN Server 依赖于 Docker 和
curl,请提前安装
Outline Manager 运行后会启动 UI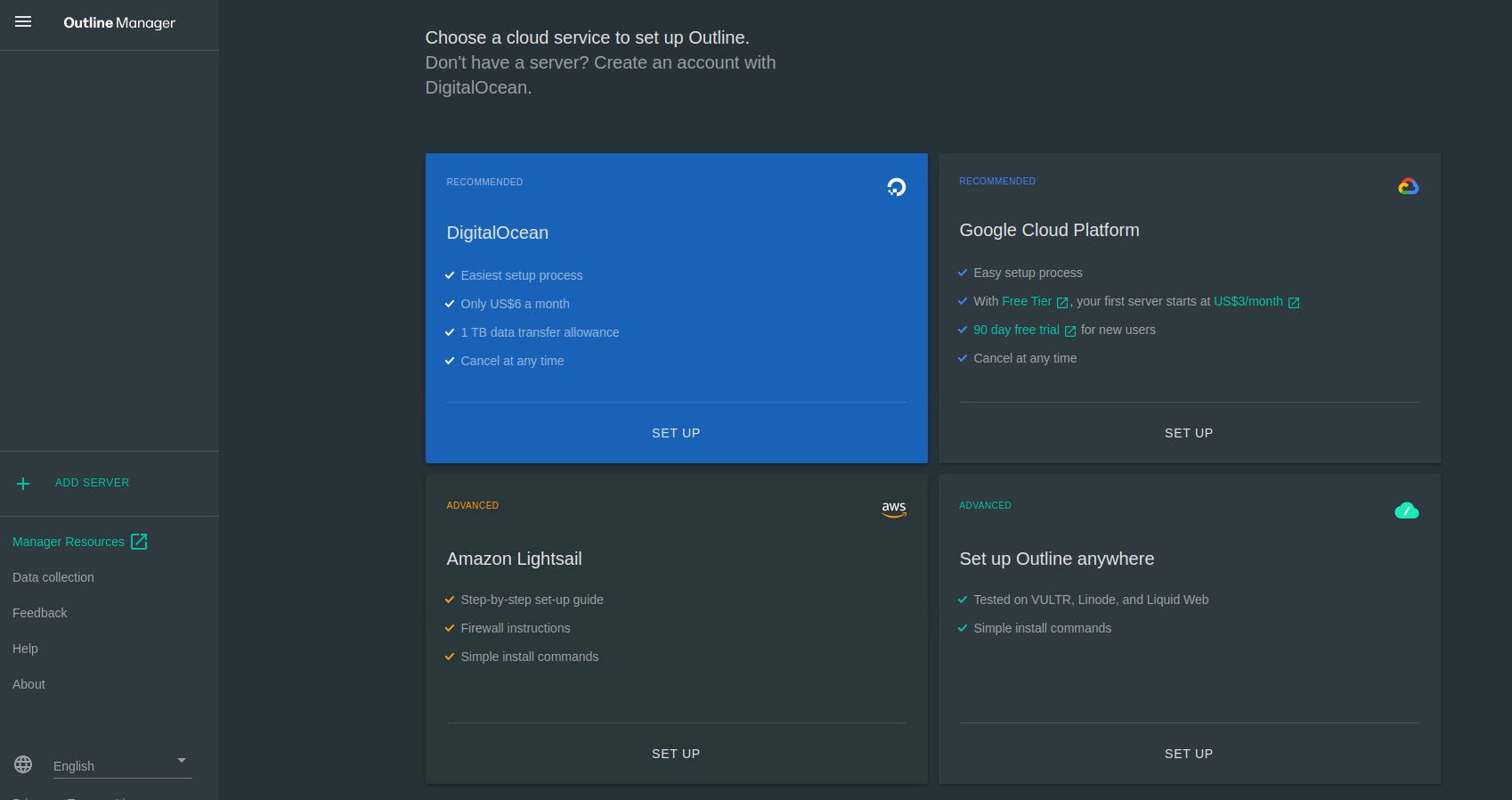
Outline 环境中,VPN Server 负责具体的 VPN 节点实现。要部署 VPN Server,选择合适的服务器环境,比如使用自己的本地服务器则选择 Set up Outline anywhere,然后根据提示在具体的 VPN Server 上部署程序即可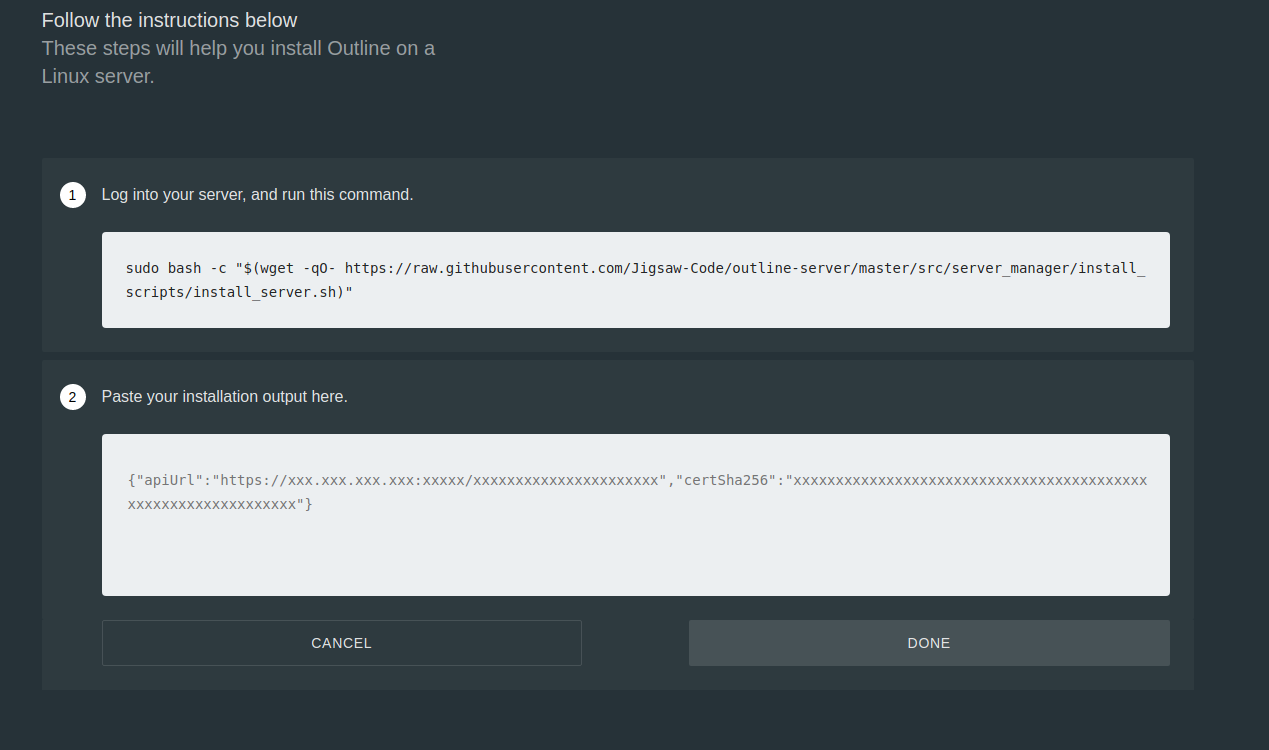
根据提示,执行以下命令,部署 VPN Server 环境程序
sudo bash -c "$(wget -qO- https://raw.githubusercontent.com/Jigsaw-Code/outline-server/master/src/server_manager/install_scripts/install_server.sh)" |
根据提示 Management port 50472, for TCP、Access key port 13279, for TCP and UDP,防火墙放通对应的端口
默认情况下,
Management port和Access key port使用随机端口,要使用自定义的固定端口,使用以下命令配置 VPN Server 环境
如果在同一台主机上重复执行
install_server.sh,请删除持久化数据目录,默认为/opt/outline/,否则可能出现重复部署后某些配置依然是旧的。
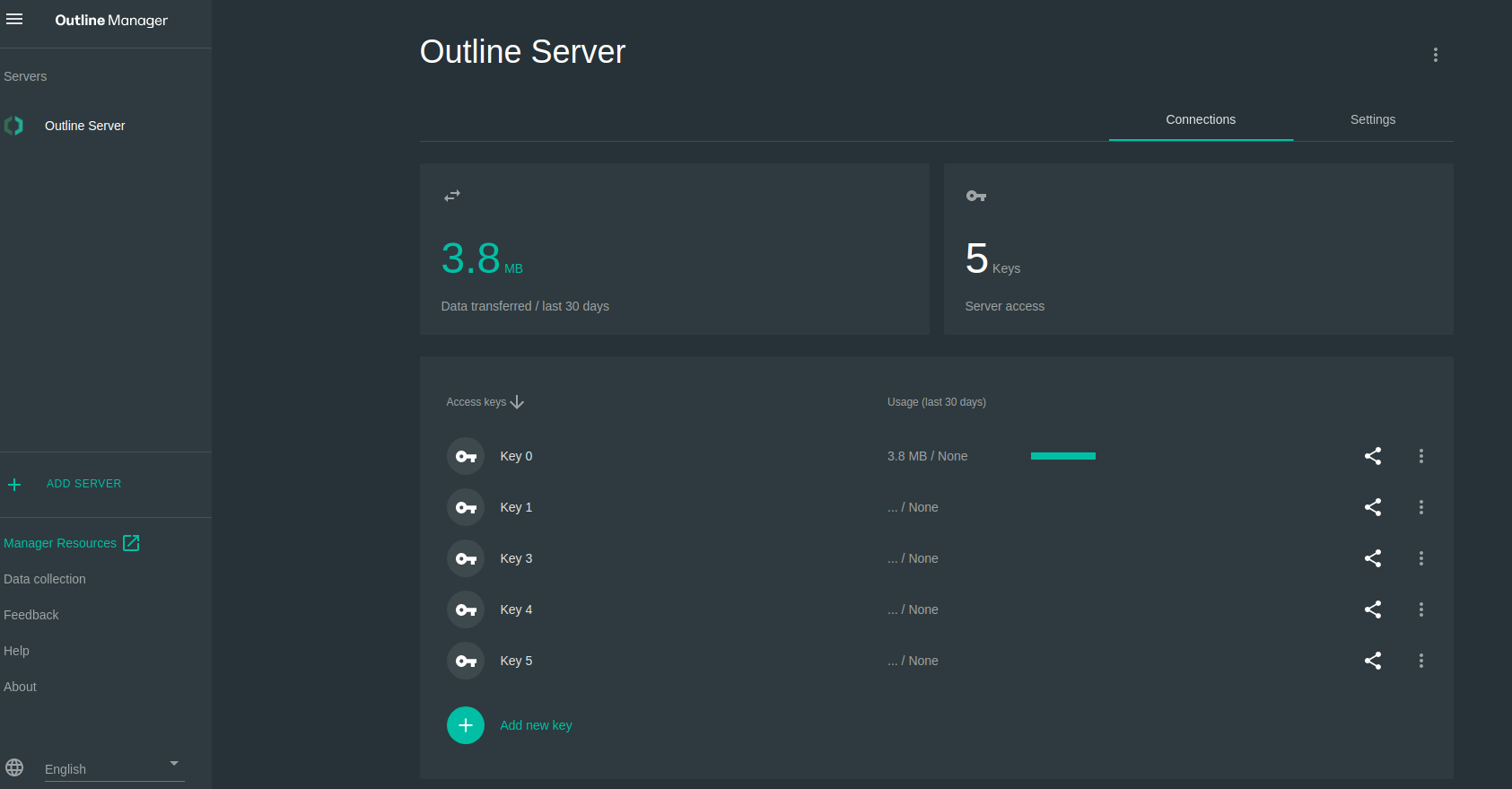
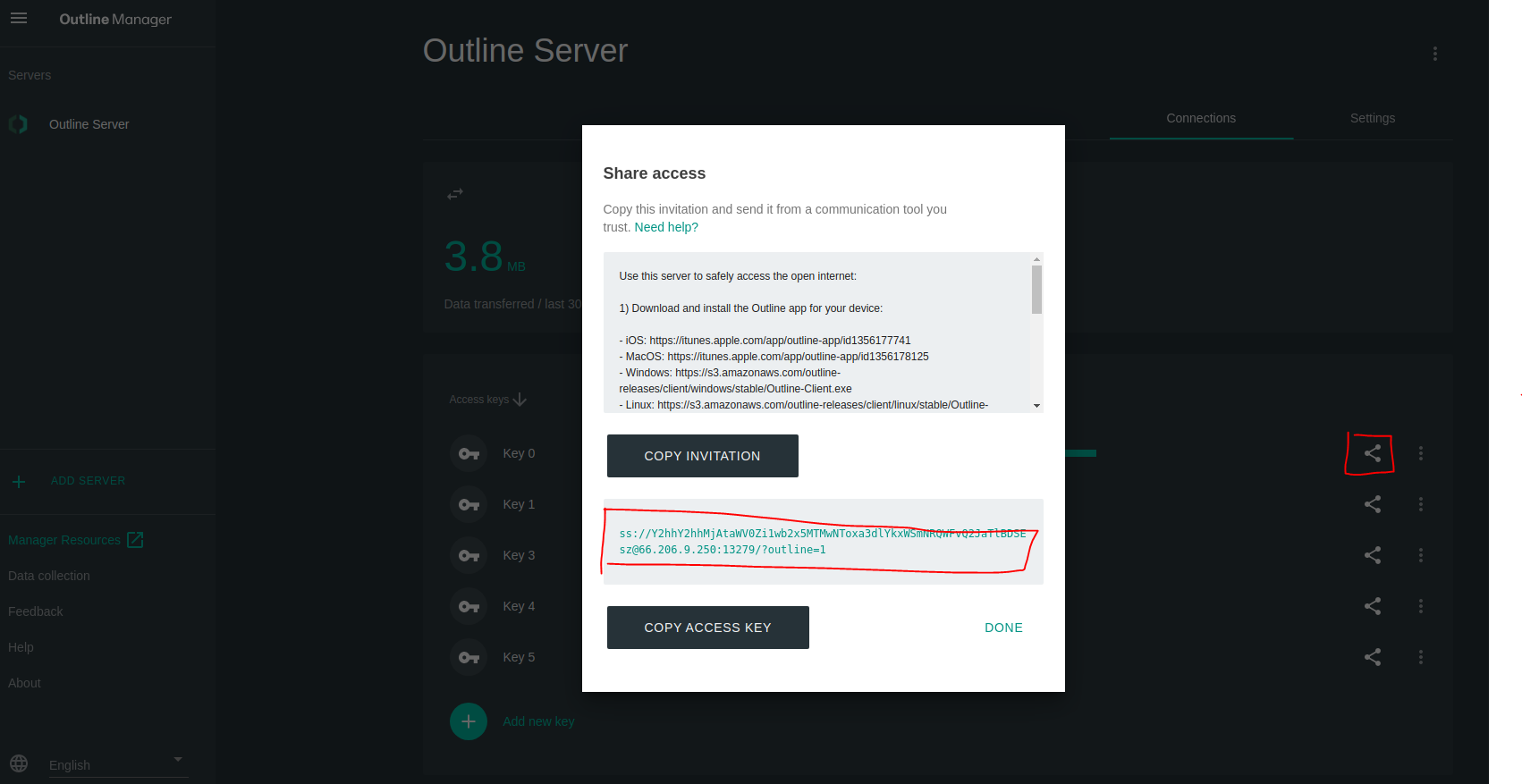
下载客户端程序,COPY ACCESS KEY 到客户端测试连接。
Certbot 是 Let’s Encrypt SSL 官方推荐的 ACME 协议客户端,它是一个 Python 程序,且包含模块化插件支持。Let’s Encrypt 的根证书浏览器支持广泛,且支持泛域名。但单个证书的有效期为 90 天,以防止滥用。
以下步骤演示在 Python3 环境中安装 Certbot 及其相关依赖
certbot pip install certbot |
certbot-dns-cloudflare 插件实现自动验证,参考以下命令安装 certbot-dns-cloudflare,此模块需要 cloudflare 模块的支持 pip install cloudflare |
cloudflare 版本需要最低为 2.3.1 [1] pip list |
certbot 申请域名证书,并支持 Cloudflare DNS 的自动验证。参考步骤安装 certbot 及 Cloudflare DNS 插件后 即可使用 certbot 自动请求 Cloudflare DNS 创建申请证书时需要的 DNS 记录自动完成域名归属权的验证过程。
certbot 支持的 Cloudflare 相关的参数如下
| 参数 | 说明 | 示例 |
|---|---|---|
--dns-cloudflare |
使用 Cloudflare 的 DNS 插件自动验证域名归属权 | |
--dns-cloudflare-credentials |
请求 Cloudflare 的授权配置文件 | |
--dns-cloudflare-propagation-seconds |
请求 Cloudflare DNS 添加相关 DNS 记录后,让 ACME 服务等待多少秒再验证 DNS 记录。主要用来防止 DNS 记录添加后,缓存 DNS 服务器未来得及更新最新记录。 默认为 10 |
假设有 Cloudflare 账号的 Global API Key,则 Credentials 配置文件内容参考如下
Cloudflare API credentials used by Certbot |
申请证书的具体命令如下,如果是第一次申请,需要根据提示填写自己的邮箱信息并同意许可协议,邮箱用于接受之后系统发送的错误或者域名证书过期等信息
certbot certonly \ |
如果是非交互式环境,可以使用参数
--email [email protected]和--agree-tos自动绑定邮箱并同意许可
执行以下命令之一安装 Shadowsocks (Python3 版本)
pip3 install git+https://github.com/shadowsocks/shadowsocks.git@master |
创建一个配置文件,比如放在 /etc/shadowsocks/config.json 目录下。配置文件的内容如下:
{ |
配置选项说明 :
server : 服务器监听的 IP 地址,0.0.0.0 表示监听所有接口。server_port : 服务器监听的端口,客户端连接到这个端口。password : 用于加密流量的密码,请设置一个强密码。method : 加密方法。其他加密算法请参考官网timeout : 超时时间(秒)。fast_open : 如果启用 TCP Fast Open,请将其设置为 true,但需要内核支持。使用以下命令启动 Shadowsocks 服务,该命令会以后台进程的方式启动 Shadowsocks:
ssserver -c /etc/shadowsocks/config.json -d start |
常用选项 :
| 选项 | 说明 | 示例 |
|---|---|---|
-h, --help |
打印帮助信息 | |
-d [start / stop / restart ] |
以 Daemon 方式(后台)运行 | |
--pid-file |
Daemon 模式启动时的 PID 文件路径 | |
--log-file |
Daemon 模式启动时日志文件路径 | |
--user |
运行服务的用户 | |
-v, -vv |
verbose 模式 |
|
-q, -qq |
quite 模式 |
|
-c |
配置文件路径 | ssserver -c /etc/shadowsocks/config.json -d start |
-s |
指定服务端监听地址,默认为 0.0.0.0 。等同于配置文件中的 server |
|
-p |
指定服务端监听端口,默认为 8388 。等同于配置文件中的 server_port |
|
-k |
指定密码 。等同于配置文件中的 password |
|
-m |
加密方法,默认为 aes-256-cfb 。 等同于配置文件中的 method |
|
-t |
超时时间(单位为 秒),默认 300s 。 等同于配置文件中的 timeout |
|
--fast-open |
启用 TCP_FASTOPEN,需要 Linux 3.7+ |
|
--workers |
workers 数量,Linux/Unix 可用 |
|
--forbidden-ip |
, 分割的 IP 列表,在此列表中的 IP 禁止连接,即黑名单 |
|
--manager-address |
服务端 UDP 管理地址 |
参考以下内容,为 Shadowsocks 配置 systemd services 文件
[Unit] |
启用并启动 Shadowsocks 服务
sudo systemctl enable shadowsocks |
在客户端(如 Windows、macOS、iOS 或 Android)上,使用 Shadowsocks 客户端进行连接。
客户端配置:
服务器地址 : 填写你服务器的公网 IP。服务器端口 :填写 config.json 中的 server_port,如 8388。密码 : 填写配置文件中的 password。加密方法 : 选择 method 中配置的加密方法,如 aes-256-cfb。如果需要调试或查看运行日志,可以通过以下命令查看 Shadowsocks 的日志:
journalctl -u shadowsocks |
ss 命令是一个查看 Linux 系统 socket 统计信息的工具,类似于 netstat,但是能显示更多的 TCP 和状态信息。
常用选项 ,可查看 man ss
| 选项 | 说明 | 示例 |
|---|---|---|
-h, --help |
输出选项的简要说明 | |
-V, --version |
打印版本信息 | |
-H, --no-header |
不打印首行(Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port Process) |
|
-n, --numeric |
不对服务名进行解析,直接输出端口(数值类型) | |
-r, --resolve |
尝试解析 IP 和 端口 为对应的名称,默认行为 | |
-a, --all |
列出正在监听的端口以及已经建立连接的端口 | |
-l, --listening |
仅列出正在监听的端口,默认不列出。 | |
-m, --memory |
显示 socket 的 内存 使用情况 |
|
-p, --processes |
显示使用此 socket 的进程 |
|
-s, --summary |
显示简略的统计信息 | |
-4, --ipv4 |
只显示 IPv4 相关的 socket |
|
-6, --ipv6 |
只显示 IPv6 相关的 socket |
|
-t, --tcp |
只显示 TCP 相关 socket |
|
-u, --udp |
只显示 UDP 相关 socket |
环境信息
有以下配置:
ip daddr 127.0.0.11 jump DOCKER_OUTPUT counter; |
加载配置时报错: Error: Statement after terminal statement has no effect
错误原因 : nftables 规则中在 终止语句(terminal statement)(如 jump 或 dnat)后添加的语句(如 counter)没有作用,因为 jump 或 dnat 语句已经处理了数据包,不会再执行后续的语句。
在
nftables中,终止语句(terminal statement) 是那些一旦执行后就结束了该数据包的处理,例如jump、accept、drop、dnat、snat等。因为这些语句会决定数据包的最终去向,所以在这些语句后面再添加如counter这样的语句是无效的。
解决方法 : 要正确配置计数器,你需要 将 counter 放在终止语句 之前,这样在执行 jump 或 dnat 之前,数据包会先经过计数器。
ip daddr 127.0.0.11 counter jump DOCKER_OUTPUT; |
假如要在一个规则中同时放通 HTTP 和 HTTPS (80 和 443 端口),以下是错误语句
nft insert inet filter input handle 11 tcp dport 80,443 counter accept comment \"for nginx\" |
在 nftables 中,多个端口 在指定时不能直接用逗号分隔。对于多个端口,应该使用集合({})的语法来指定。以下为正确语法
nft insert rule inet filter input handle 11 tcp dport { 80,443 } counter accept comment \"for nginx\" |
注意: 使用 集合 (
{})语法时要注意其中的空格,{ 80,443 }是正确格式,如果写成{80,443}则是错误格式
使用以下语句添加规则报错:
nft insert rule inet filter input handle 11 tcp dport { 80,443 } counter accept comment "for nginx" |
正确格式如下:
nft insert rule inet filter input handle 11 tcp dport { 80,443 } counter accept comment \"for nginx\" |
注意: 在 cmd 中交互式操作时,注释中使用的 双引号(
"") 要使用 转义(\)
bridge 模式是 docker 的默认网络模式,不使用 --network 参数,就是 bridge 模式。
当 Docker 进程启动时,会在主机上创建一个名为 docker0 的虚拟网桥,默认主机上启动的 Docker 容器会连接到这个虚拟网桥上。
容器启动时,docker 会从 docker0 网桥的子网中分配一个 IP 地址给容器中的网卡。大体流程为在主机上创建一个 `veth pair`,Docker 将 veth pair 的一端放在容器中,命名为 eth0 并配置 IP,网关,路由等信息,将 veth pair 的另一端加入 docker0 网桥。
通过这种方式,主机可以跟容器通信,容器之间也可以相互通信。
如果启动容器的时候使用 host 模式,那么这个容器将不会获得一个独立的 Network Namespace,而是和宿主机一样在 Root Network Namespace,容器中看到的网络方面的信息和宿主机一样,容器使用的网络资源在整个 Root Network Namespace 不能出现冲突。容器将不会虚拟出自己的网卡,配置自己的 IP 等,而是使用宿主机的 IP 和端口,主机名也是使用宿主机的。但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。
host 模式下的容器可以看到宿主机上的所有网卡信息,可以直接使用宿主机 IP 或主机名与外界通信,无需额外的 NAT,也无需通过 Linux bridge 进行转发或者数据包的封装,可以访问主机上的其他任一容器。
使用如下命令参数启动 host 网络模式的容器
docker run --network host --name test1 -p 80:80 -d -it centos:centos7.9.2009 |
host 模式的容器,没有自己的 network namespace,在 root network namespace 中。进入测试容器 test1,查看网卡、 IP 信息及端口、主机名信息,会看到和宿主机一样的信息。
ip link |
host 模式的缺点
network namespace ,网络和宿主机或其他使用 host 模式的容器未隔离,容易出现资源冲突,比如同一个宿主机上,使用 host 模式的容器中启动的端口不能相同。使用 none 模式,Docker 容器拥有自己的 Network Namespace,但是,系统并不为 Docker 容器进行任何网络配置。也就是说,这个 Docker 容器没有网卡(lo 回环网卡除外)、IP、路由等信息。需要我们自己为 Docker 容器添加网卡、配置 IP 等。
参考以下命令创建 none 模式的容器
docker run --network none --name test-none -p 82:80 -d -it centos7:my |
容器创建后,进入容器中,查看网卡和 IP 等信息,容器中默认只存在 lo 网卡,不存在其他网卡
ip add |
以下操作演示手动为容器配置网络
创建 veth pair
ip link add veth0 type veth peer name veth0_p |
将 veth pair 的一端 veth0 放入 docker 默认的网桥 docker0,另一端 veth0_p 放入容器中
首先使用命令 docker inspect test-none | grep "Pid" 找到容器对应的 PID,此处为 84040,根据此 PID 将 veth 的一端放入容器的 network namespace 中
ip link set dev veth0 master docker0 |
在宿主机上面检查 veth0,确定其已经加入网桥 docker0,并且 veth0_p 已不在 root network namespace 中
ip link |
重新进入容器,检查网卡信息,可以看到容器中已经有了网卡 veth0_p,状态为 DOWN
ip -d link |
为容器中的网卡配置 IP 及网关等信息
为了能在宿主机对容器的 network namespace 进行操作,首先需要将容器的 network namespace 暴露出来,之后可以在宿主机通过 network namespace 名称(此处为 84040,可以自定义)操作 network namespace 。Linux network namespace 参考
ln -s /proc/84040/ns/net /var/run/netns/84040 |
通过 network namespace 名称(此处为 84040)配置容器中网卡的 IP 地址信息
ip netns exec 84040 ip link set dev veth0_p name eth0 |
进入容器检查网络信息
ip add |
进入容器测试网络连接
ping 8.8.8.8 |
iptables 的底层实现是 netfilter,netfilter 的架构是在整个网络流程(TCP/IP 协议栈)的若干位置放置一些钩子,并在每个钩子上挂载一些处理函数进行处理。
IP 层的 5 个钩子点的位置,对应就是 iptables 的 5 条内置链,分别是
PREROUTINGFORWARDINPUTOUTPUTPOSTROUTING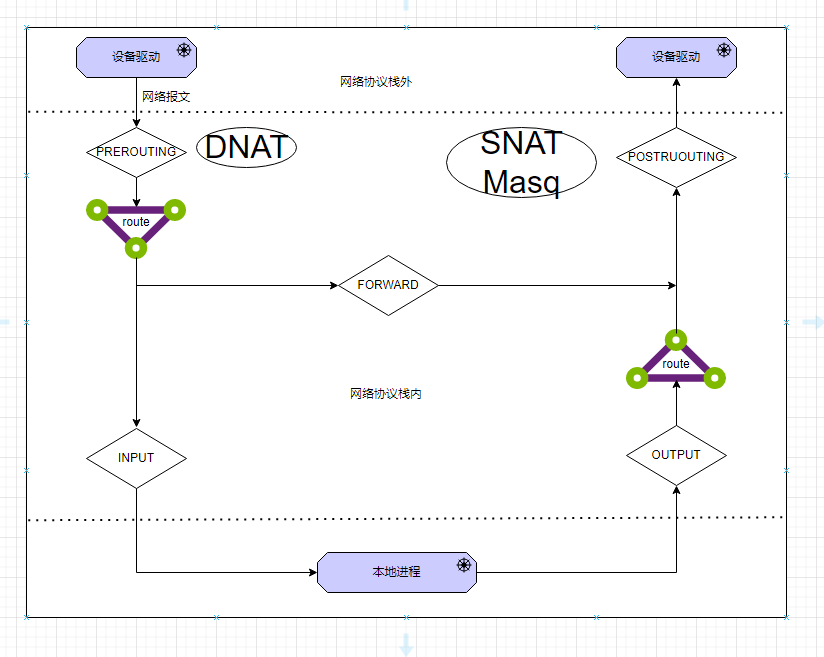
当网卡收到一个网络报文送达协议栈时,最先经过的 netfilter 钩子是 PREROUTING,此处常见的钩子函数是 目的地址转换 (DNAT)。无论 PREROUTING 是否存在钩子处理网络数据包,下一步内核都会通过 查询本地路由表 决定这个数据包的流向
INPUT 链传给本地进程network namespace),则经过 netfilter 的 FORWARD 钩子传送出去,相当于将本地机器当作路由器所有马上要发送到网络协议栈之外的数据包,都会经过 POSTROUTING 钩子,这里常见的处理函数是 源地址转换(SNAT) 或者 源地址伪装(Masquerade, 简称 Masq)
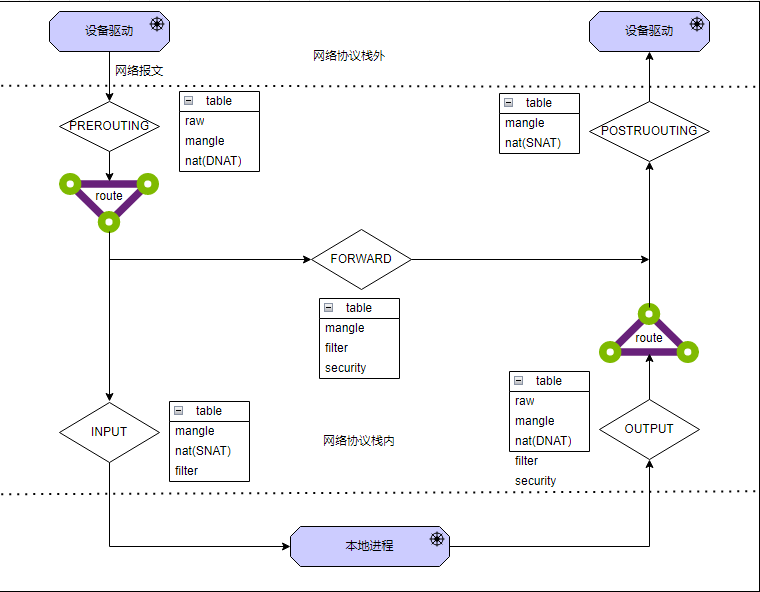
除了 5 条内置的链,iptables 还有 5 张表,这 5 张表主要是用来给 iptables 中的规则(rule)分类,系统中所有的 iptables 规则都被划分到不同的表集合中。5 张表分别为
raw - iptables 是有状态的,即 iptables 对数据包有连接追踪 (connection trackong) 机制,而 raw 可以用来去除这种追踪机制mangle - 用于修改数据包的 IP 头信息nat - 用于修改数据包的源或者目的地址filter - 用于控制到达某条链上面的数据包是继续放行、直接丢弃(drop)、或拒绝(reject)security - 用于在数据包上面应用 SELinux表是有优先级的,5 张表的优先级从高到低是: raw、mangle、nat、filter、security,iptables 不支持自定义表。不是每个链上都能挂表,iptables 表与链的对应关系如下图
| - | PREROUTING | FORWARD | INPUT | OUTPUT | POSTROUTING |
|---|---|---|---|---|---|
raw |
Y | N | N | Y | N |
mangle |
Y | Y | Y | Y | Y |
nat (SNAT) |
N | N | Y | N | Y |
nat (DNAT) |
Y | N | N | Y | N |
filter |
N | Y | Y | Y | N |
security |
N | Y | Y | Y | N |
iptables 表和链的工作流程图如下
常用选项说明
| 选项 | 说明 | 示例 |
|---|---|---|
-F ,--flush |
清除所有规则,默认规则除外 | |
-P ,--policy |
设置默认规则 | |
-t ,--table |
指定要操作的表,默认为 filter 表 |
iptables -t nat -P INPUT ACCEPT |
--list ,-L [chain [rulenum]] |
列出(指定的链或所有链)的规则 | iptables -t nat -L -v -n --line-numbers |
--verbose ,-v |
verbose mode | |
--numeric ,-n |
不解析协议和端口号,以数字的形式显示 | |
--line-numbers |
显示规则的行号,可以根据行号对具体的规则进行操作 | |
--jump ,-j |
匹配的规则的处理 target | iptables -A INPUT -j LOG |
--append ,-A chain |
像指定的链中追加规则 | -A INPUT -i lo -j ACCEPT |
--insert ,-I chain [rulenum] |
向指定的链中指定的位置插入规则 | iptables -I INPUT 10 -p tcp --dport 80 -j ACCEPT |
--delete ,-D chain rulenum |
删除指定链中的指定位置的规则 | iptables -D INPUT 10 |
--replace ,-R chain rulenum |
更新指定链中的指定位置的规则 | |
-S, --list-rules [chain] |
按照类似 iptables-save 的输出打印规则 |
logrotate 程序是一个日志文件管理工具。用于分割日志文件,压缩转存、删除旧的日志文件,并创建新的日志文件
logrotate 是基于 crond 来运行的,其脚本是 /etc/cron.daily/logrotate,日志轮转是系统自动完成的。
实际运行时,logrotate 会调用配置文件 /etc/logrotate.conf。/etc/cron.daily/logrotate 文件内容如下:
!/bin/sh |
可以执行以下命令手动执行日志切割:
logrotate -f /etc/logrotate.conf |
以下命令可以检测配置文件是否正确:
logrotate -d /etc/logrotate.conf |
报错信息如下:
ssl.SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1007) |
问题原因 : 本地 CA 证书不存在
解决方法
>> import ssl |
openssl 位于 /usr/local/openssl/,CA 证书路径为 /usr/local/openssl/ssl/cert.pem,检查 CA 证书路径,发现 CA 证书不存在 cd /usr/local/openssl/ssl/ |
wget http://curl.haxx.se/ca/cacert.pem --no-check-certificate |
在 Docker 中运行 python 后,使用 pip 报错 RuntimeError: can't start new thread
pip install --upgrade pip |
问题原因 Docker 版本太低,升级版本到 18.06 以上。参考说明
报错信息如下:
ssl.SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1007) |
问题原因 : 本地 CA 证书不存在
解决方法
>> import ssl |
openssl 位于 /usr/local/openssl/,CA 证书路径为 /usr/local/openssl/ssl/cert.pem,检查 CA 证书路径,发现 CA 证书不存在 cd /usr/local/openssl/ssl/ |
wget http://curl.haxx.se/ca/cacert.pem --no-check-certificate |
在 Docker 中运行 python 后,使用 pip 报错 RuntimeError: can't start new thread
pip install --upgrade pip |
问题原因 Docker 版本太低,升级版本到 18.06 以上。参考说明
在 Ubuntu 上安装软件包主要通过使用 apt 命令来完成。apt 是高级包装工具(Advanced Package Tool)的缩写,提供了一个易用的命令行界面,用于处理软件包的安装、更新和删除等操作。
查看系统已安装的软件包
apt list --installed |
apt list列出系统上所有可用的软件包,包括已安装的软件包和可供安装的软件包
列出特定的软件包
apt list <package-name> |
搜索特定软件包是否已安装
apt list --installed <package-name> |
查看软件包的依赖关系
apt depends <package_name> |
apt download <package_name> |
更新软件包列表。在安装新软件包之前,最好先更新本地软件包列表,以确保你安装的是最新版本的软件包。
sudo apt update |
此命令会从配置的源中检索新的软件包列表。
安装软件包。安装软件包的基本命令格式为:
sudo apt install <package_name> |
安装特定版本的软件包
如果你需要安装软件包的特定版本,可以通过指定版本号来完成安装。首先,使用 apt policy 命令查找可用版本
apt policy <package_name> |
然后,安装特定版本的软件包
sudo apt install <package_name>=<version> |
安装推荐的软件包。
当安装某些软件包时,APT 可能会建议安装一些推荐的软件包以增强功能。默认情况下,apt install 命令会安装推荐的软件包。 如果你不想安装推荐的软件包,可以使用 --no-install-recommends 选项
sudo apt install --no-install-recommends <package_name> |
卸载软件包但保留配置文件
sudo apt remove <package_name> |
卸载软件包并删除配置文件。如果相关目录不为空,将不会删除,会输出提示
sudo apt purge <package_name> |
或者
sudo apt remove --purge <package_name> |
清理未使用的依赖包
当你卸载一个软件包时,它可能会留下一些不再需要的依赖软件包。为了清理这些不再使用的依赖,可以执行:
sudo apt autoremove |
这个命令会检查并自动删除那些被安装为其他软件包依赖但现在不再被任何已安装软件包需要的软件包。
列出系统上已安装的软件包
dpkg -l |
查找文件所属的软件包
dpkg -S /path/to/file |
APT 通过读取配置文件(主要是 /etc/apt/sources.list 和 /etc/apt/sources.list.d/*.list)来获取软件包仓库(repository)的信息。
APT 的软件源配置文件是 /etc/apt/sources.list ,此外还可以包含 /etc/apt/sources.list.d/ 目录下的 .list 文件。这些文件定义了 APT 从哪里下载软件包和更新信息。
一个典型的 sources.list 条目格式如下:
deb [options] url distribution component1 component2 component3 |
deb:表示这是一个二进制软件包的仓库,对应的 deb-src 表示源代码仓库。options:可选项,例如可以指定架构。url:仓库的 URL。distribution:发行版的代号,如 focal、buster 等。component :仓库中的组成部分,如 main、restricted 等。在 APT 的上下文中,软件包仓库是网络或本地的存储位置,它们存储了软件包及其元数据。主要有以下几种类型的仓库:
Main:官方支持的免费软件。Universe:社区维护的免费软件。Restricted:官方支持的非自由软件。Multiverse:非自由软件,不包括官方支持。要添加新的软件源,你可以直接编辑 sources.list 文件或在 sources.list.d/ 目录下创建一个新的 .list 文件。例如,添加一个新的 PPA(Personal Package Archive):
sudo add-apt-repository ppa:<repository_name> |
这个命令不仅会添加软件源,还会自动导入仓库的公钥,确保软件包的安全性。
要删除软件源,可以直接编辑 sources.list 文件或删除 sources.list.d/ 目录下相应的 .list 文件。之后,运行 sudo apt update 来更新软件包列表。
早期的 Linux 桌面都是基于来自 X.Org Foundation(http://www.x.org) 的 X Window System 的接口。一个 X.Org 的替代者是 Wayland (http://wayland.freedesktop.org)。
X Window System(简称 X)在 Linux 之前就存在,甚至早于 Microsoft Windows,它是一个轻量的、基于网络的桌面框架。
X Window System 是一种 Client/Server 模型。X Server 运行于本地操作系统中,为屏幕(Screen)、鼠标(Mouse)、键盘(Keyboard)提供对外的接口,X Client 可以在本地或者任何基于网络的远端系统上面运行。
X Server 本身只提供了一个简单的灰色背景和一个 X 型鼠标光标,没有菜单、面板、图标等,如果只是单纯的启动 X Client 展示 X Server 的内容,它展示的内容中不会包含 可以移动的边框、最大化、最小化按钮以及关闭窗口的按钮等 ,这些特性是由 Window Manager 提供的。
Window Manager 添加了可以操作程序的很多特性,如菜单、边框、常用按钮等。
Linux 中常见的桌面环境包括:
Gnome 3 提供了很多可用的插件来满足不同的需求,并提供了工具 Gnome Tweaks 用于调整 Gnome 的配置
Gnome Shell Extensions 可以控制 Gnome 桌面的外形和行为方式。GNOME Shell Extensions site (http://extensions.gnome.org)
打开 “设置”:
点击屏幕左下角的 “显示应用程序” 按钮(或按 Super 键,也就是通常的 Windows 键)。
输入 Settings 或 设置,然后点击出现的应用图标。
查看 “关于” 信息:
在左侧面板中,向下滚动并选择 “关于”(About)。
在“关于”页面中,你会看到 GNOME 版本信息以及其他系统详细信息。
你也可以通过终端命令查看 GNOME 版本:
打开终端:
按 Ctrl + Alt + T 打开终端。
使用以下命令
gnome-shell --version |
版本信息:
参考以下步骤:
gnome-shell-extension-manager sudo apt-get install gnome-shell-extension-manager |

Browse,搜索 hidetopbar 这个插件并安装(注意选择 Downloads!!,要不然搜不到插件)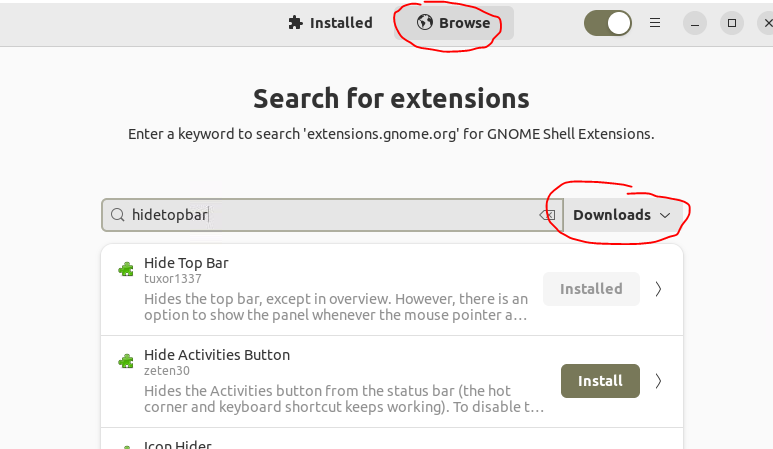
安装好了 hidetopbar 这个插件之后,上方的任务栏/状态栏 在窗口全屏时就会自动隐藏。按 Super 键或者窗口非全屏时会重新显示
pip install requests |
get 请求及响应中常用的属性
r = requests.get('https://0920811.xyz') |
要在 get 请求中携带请求参数,可以使用以下方法
help(requests.get) |
get 方法本质上是通过创建了一个 requests.Request 对象,因此 **kwargs 可用的值可以通过查看 requests.Request 的帮助信息。
help(requests.Request) |
Selenium 是一个用于自动化 Web 浏览器操作的工具,可以用于模拟用户与网站的交互。
使用 pip 安装 Selenium 库
pip install selenium |
Selenium 需要一个 WebDriver 来控制不同的浏览器。可以根据要使用的浏览器下载相应的 WebDriver。以下是一些常见的浏览器和对应的WebDriver下载链接:
下载 WebDriver 并确保它在系统路径中可用。WebDriver 和浏览器具有版本对应关系,要确保版本匹配
本示例中以 Chrome 浏览器为例。
创建一个浏览器实例,并请求指定的页面
from selenium import webdriver |
关闭当前浏览器窗口
driver.close() |
最大化浏览器窗口
driver.maximize_window() |
后退
driver.back() |
前进
driver.forward() |
刷新页面
driver.refresh() |
关闭浏览器
driver.quit() |
2Captcha 是一个验证码自动识别服务商。
验证码可以是含有必填扭曲文字的图片,也可以由不同图片组成,用户需从中选出符合特定条件的图片。这些操作是为了证明用户不是机器人。
参考官网安装文档 安装 Python3 模块
pip3 install 2captcha-python |
调用 2captcha 需要注册并使用 2captcha 提供的 API 密钥。
以下代码示例返回滑块类型的验证结果:
|
按照以上代码示例,针对相同的图片,每次请求返回的结果都不一样。2Captcha 针对滑块验证成功率太低,基本不可用。
Captcha solved: {'captchaId': '77043576230', 'code': 'coordinates:x=286,y=41'} |
要缓解此问题,可以使用 2Captcha 提供的 100% 识别服务,原理是通过将验证码发送给多个员工进行匹配,满足配置的条件才返回结果(根据官方回复,100% 识别服务只能针对 normal captchas 完全生效,对滑块类型的验证基本不可能得到相同的结果,相关链接)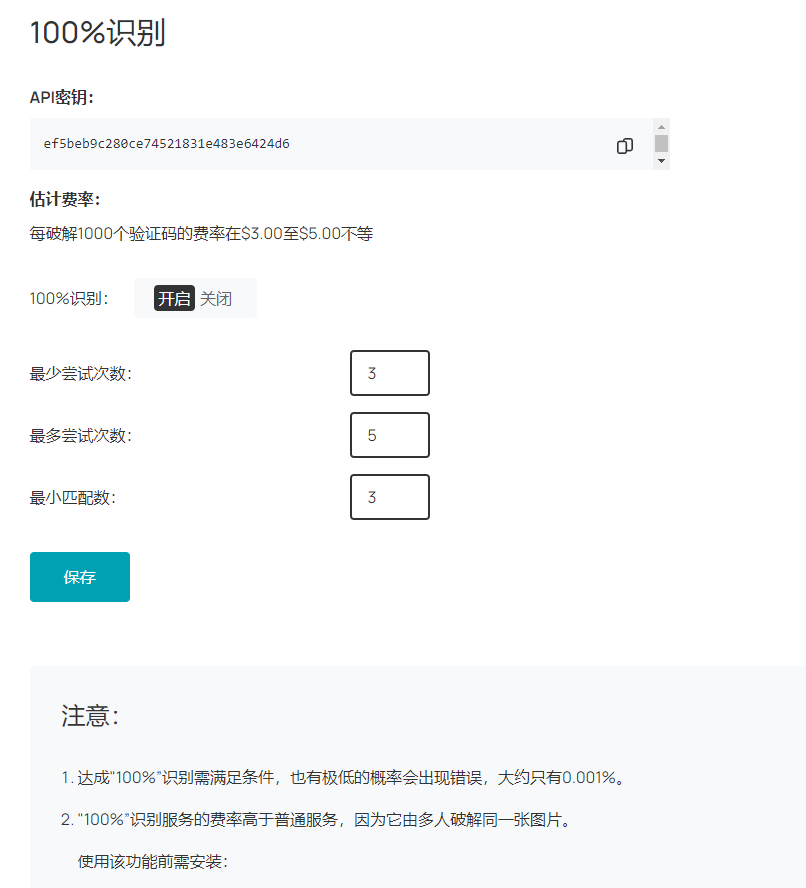
内存管理相关的系统关键进程
| Name | Path | Info | Demonstrate |
|---|---|---|---|
[kswapd0] |
由内核启动 | Linux 内核中的一个内存管理守护进程,负责内存交换(swap).当系统内存不足时,触发内存回收机制,释放不常用的内存页。内存回收使用 Page Replacement 算法(新版本使用) |
kswapd |
使用 lsmod 命令列出所有已加载的内核模块,输出中包含: 模块名称(Name)、大小(Size) 和 何处被使用(Used by)
lsmod |
要查看已加载的内核模块的详细信息,可以使用 modinfo 命令,不是所有的模块都有详细的描述信息,如果没有,则无任何返回
modinfo -d ena |
modinfo 命令常用选项:
| 选项 | 说明 | 示例 |
|---|---|---|
-a, --author |
打印模块的作者 | |
-d, --description |
打印模块的描述信息 | |
-p, --parameters |
打印模块的 ‘parm’ | |
-n, --filename |
Print only ‘filename’ |
使用 insmod 命令加载内核模块. 模块需要完整后缀(如果有)
insmod simple.ko |
使用 modprobe 命令加载内核模块. 模块不需要完整后缀(如果有) 。临时加载,重启后会消失。
modprobe parport |
使用 rmmod 命令卸载内核模块。无需后缀,只需要给定模块名
rmmod simple |
也可以使用命令 modprobe -r 移除模块,它不仅会移除指定的模块,还会移除未被继续使用的依赖的模块
| 文件路径 | 说明 | 示例 |
|---|---|---|
| /etc/motd | 登录成功后的欢迎信息,ssh 登录和 console 登录成功后都会显示 | |
| /etc/issue | 在登录系统输入用户名之前显示的信息,远程 ssh 连接的时候并不会显示此信息 | 说明示例 |
| /etc/services | 记录网络服务名和它们对应使用的端口号及协议 | |
| /etc/protocols | 该文件是网络协议定义文件,里面记录了 TCP/IP 协议族的所有协议类型。文件中的每一行对应一个协议类型,它有3个字段,分别表示 协议名称、协议号 和 协议别名 |
|
| /etc/vimrc ~/.vimrc |
vim 启动时会读取 /etc/vimrc(全局配置) 和 ~/.vimrc (用户配置) |
vim |
| /etc/passwd /etc/shadow /etc/group |
用户数据库,其中记录了 用户名,id,用户家目录,shell 等用户密码文件 组信息 |
|
| /etc/fstab | 系统启动时需要自动挂载的文件系统列表 | |
| /etc/mtab | 当前系统已挂载的文件系统,并由 mount 命令自动更新。当需要当前挂载的文件系统的列表时使用(例如df命令) |
|
| /etc/shells | 系统可使用的 shell |
|
| /etc/filesystems | 系统可使用的 文件系统 |
|
| /etc/hostname | 存放这主机名 | |
| /etc/hosts | 主机名查询静态表,域名和 ip 本地静态表 | |
| /etc/nsswitch.conf | 它规定通过哪些途径以及按照什么顺序以及通过这些途径来查找特定类型的信息,还可以指定某个方法奏效或失效时系统将采取什么动作 | hosts: files dns myhostname此配置设定:在查找域名解析的时候,先查找本地 /etc/hosts,再发送给 DNS 服务器查询 |
| /etc/rsyslog.conf | rsyslog 服务的配置文件,用来托管其他服务的日志 |
linux rsyslog 服务 |
| /etc/logrotate.conf | linux 日志切割工具 | linux logrotate 服务 |
| /etc/rsyncd.conf | rsync 服务的配置文件 |
rsyncd 服务 |
| /etc/sysctl.conf /etc/sysctl.d/ |
内核的运行参数配置文件,sysctl 命令对内核参数的修改仅在当前生效,重启系统后参数丢失,如果希望参数永久生效可以修改此配置文件 |
Linux 常用内核参数说明 |