K8S 上安装 Prometheus 并监控 K8S 集群
版本信息
- Centos 7
- Kubernetes 1.24
- Prometheus 2.44.0
- AlertManager 0.24.0
Prometheus 部署步骤
为 Prometheus 创建专用的 Namespace,此处创建 prometheus
kubectl create namespace prometheus |
创建集群角色
Prometheus 使用 Kubernetes API 从 Nodes、Pods、Deployments 等等中读取所有可用的指标。因此,我们需要创建一个包含读取所需 API 组的 RBAC 策略,并将该策略绑定到新建的 prometheus 命名空间。[1]
- 创建一个名为
prometheusClusterRole.yaml的文件,并复制以下 RBAC 角色。在下面给出的角色中,可以看到,我们已经往
nodes,services endpoints,pods和ingresses中添加了get,list以及watch权限。角色绑定被绑定到监控命名空间。如果有任何要从其他对象中检索指标的用例,则需要将其添加到此集群角色中。apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/proxy
- nodes/metrics
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: default
namespace: prometheus - 使用下面的命令创建角色
kubectl apply -f prometheusClusterRole.yaml
创建 ConfigMap 以外部化 Prometheus 配置
Prometheus 的所有配置都是 prometheus.yaml 文件的一部分,而 Alertmanager 的所有警报规则都配置在 prometheus.rules
prometheus.yaml- 这是主要的 Prometheus 配置,包含所有抓取配置、服务发现详细信息、存储位置、数据保留配置等*.rules- 此文件包含所有 Prometheus 警报规则
通过将 Prometheus 配置外部化到 Kubernetes 的 ConfigMap,那么就无需当需要添加或删除配置时,再来构建 Prometheus 镜像。这里需要更新配置映射并重新启动 Prometheus Pod 以应用新配置。
使用以下内容创建 ConfigMap。开始学习时可以先使用 基础配置,熟悉之后逐步添加配置。
apiVersion: v1 |
prometheus.yaml 包含了用以发现动态运行在 Kubernetes 集群中的资源的配置。
部署 Prometheus Server
使用以下内容创建 Deployment,在此配置中,我们将 Prometheus 的 ConfigMap 作为文件安装在 /etc/prometheus 中,持久化存储使用 PV。
apiVersion: apps/v1 |
使用以下内容为 Prometheus Server 创建 Ingress
apiVersion: v1 |
部署完成后,使用 prometheus.example.com 访问
可以通过 url http://prometheus.example.com/config 查看当前的 prometheus 配置
部署 Grafana
如需部署 Grafana,可以使用以下配置,需要持久化数据目录
apiVersion: apps/v1 |
集群节点上部署 node-exporter 对集群节点进行监控
使用 DaemonSet 方式在每个 Node 上部署 node-exporter,本示例运行在 prometheus 的 Namespace 中。为了暴露 node-exporter 给 Prometheus Server ,可以使用以下方法。建议使用第 2 种方法。
Service 的 port type 配置为
NodePort。配置 Kubernetes API Server 允许 9100 端口配置为 NodePort 参考,如此可以直接通过节点 IP 访问node-exporter为了确保 Prometheus Server 请求查询指定节点的监控数据的流量都能被本节点上的
node-exporter处理,建议配置externalTrafficPolicy: Local、internalTrafficPolicy: Local---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: prometheus
labels:
k8s-app: node-exporter
spec:
selector:
matchLabels:
name: node-exporter
template:
metadata:
labels:
name: node-exporter
spec:
containers:
- name: node-exporter
image: prom/node-exporter
ports:
- containerPort: 9100
protocol: TCP
name: http
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: node-exporter
name: node-exporter
namespace: prometheus
spec:
ports:
- name: http
port: 9100
protocol: TCP
targetPort: 9100
nodePort: 39100
selector:
name: node-exporter
sessionAffinity: None
type: NodePort
externalTrafficPolicy: Local
internalTrafficPolicy: Local不使用 Service,直接配置 Pod 网络为
hostNetwork,如此 Pod 的 Network Namespace 是在节点的 Root Network Namespace,可以直接使用节点的网络资源。同时配置 Pod 使用节点的 PID、IPC 资源。挂载主机的/dev、/proc、/sys等目录到容器中,以使node-exporter可以监控到节点上的数据。否则,node-expoter 因为权限问题无法监控到节点的资源
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: prometheus
labels:
k8s-app: node-exporter
spec:
selector:
matchLabels:
name: node-exporter
template:
metadata:
labels:
name: node-exporter
spec:
hostPid: true
hostIPC: true
hostNetwork: true
containers:
- name: node-exporter
image: prom/node-exporter
securityContext:
privileged: true
args:
- --path.procfs
- /host/proc
- --path.sysfs
- /host/sys
- --collector.filesystem.ignored-mount-points
- '"^/(sys|proc|dev|host|etc)($|/)"'
volumeMounts:
- name: dev
mountPath: /host/dev
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: rootfs
mountPath: /rootfs
ports:
- containerPort: 9100
protocol: TCP
name: http
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /
部署之后通过 Grafana 导入 8919 Dashboard,可以通过 node exporter 实现采集 node 节点上的监控数据。
如果部署之后,Dashboard 显示无数据,需要排查 node-exporter 相关的 Service,EndPoint 是否正常。
kubectl get services -n prometheus |
配置 Prometheus 支持 Kubernetes 服务发现
在 Kubernetes 下,Promethues 通过与 Kubernetes API 集成目前主要支持5种服务发现模式,分别是: [3]
NodeServicePodEndpointsIngress
配置 Prometheus 支持 Kubernetes 节点自动发现并抓取监控指标
为了让 Prometheus 能够获取到当前集群中所有节点的信息,在 Promtheus 的配置文件中,添加如下 Job 配置:
- job_name: 'kubernetes-nodes' |
通过指定 kubernetes_sd_config 的模式为 node,Prometheus 会自动从 Kubernetes 中发现到所有的 node 节点并作为当前 Job 监控的 Target 实例。这里需要指定用于 访问 Kubernetes API 的 ca 以及 token 文件路径。
通过以上配置,Prometheus 可以自动从 Kubernetes API Server 中发现节点的信息,并将其作为当前 Job 的 Target 实例,此配置下默认只存在 2 个标签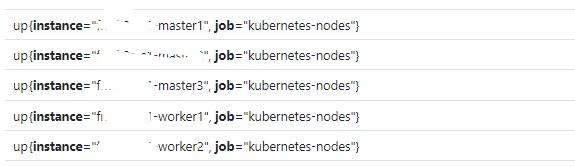
要将节点中的所有标签添加到 Prometheus 监控指标中,可以添加以下 labelmap 配置,意思为将正则表达式 __meta_kubernetes_node_label_(.+) 匹配的数据也添加到指标数据的 Lable 中去。
- job_name: 'kubernetes-nodes' |
以上配置生效后,重新查看节点的标签信息,可以看到节点的的标签已经添加到了 Prometheus 监控指标中。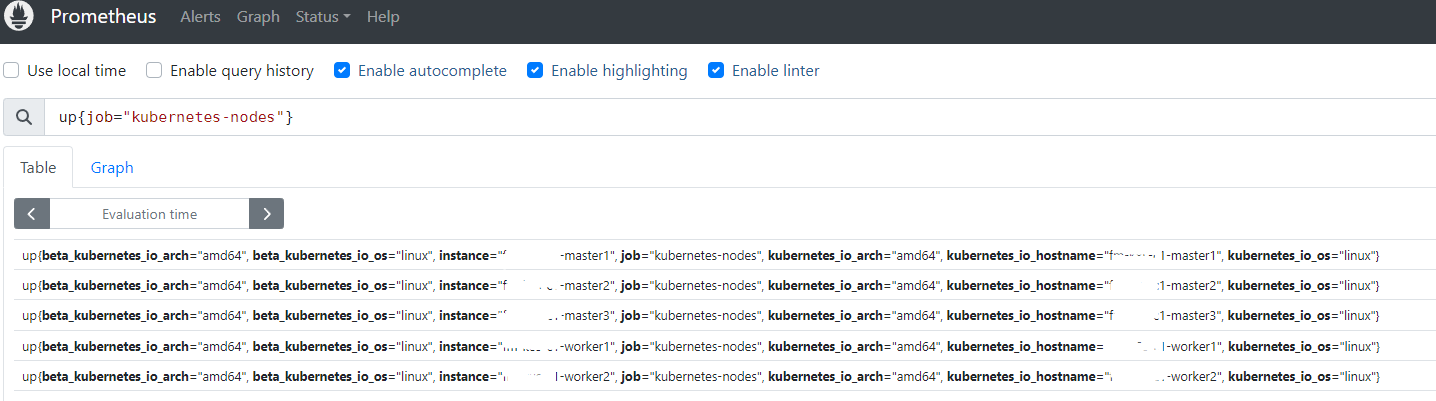
对于 kubernetes_sd_configs 下面可用的元信息标签如下:
__meta_kubernetes_node_name:节点对象的名称__meta_kubernetes_node_label:节点对象中的每个标签__meta_kubernetes_node_annotation:来自节点对象的每个注释__meta_kubernetes_node_address:每个节点地址类型的第一个地址(如果存在)
配置 Prometheus 自动发现 kube-apiserver 并读取监控指标
kube-apiserver 监听在节点的 6443 端口,通过以下配置可以使 Prometheus 读取 kube-apiserver 的指标数据
- job_name: "kubernetes-apiservers" |
配置 Prometheus 自动发现 kubelet 并读取监控指标
kubelet 监听在节点的 10250 端口,通过以下配置可以使 Prometheus 读取 kubelet 提供的监控数据。这里需要 配置好 ServiceAccount的权限,以使 Prometheus 有查询集群资源的权限。
global: |
以上配置生效后,查看 Prometheus 的 Targets,会看到多了 kubernetes-kubelet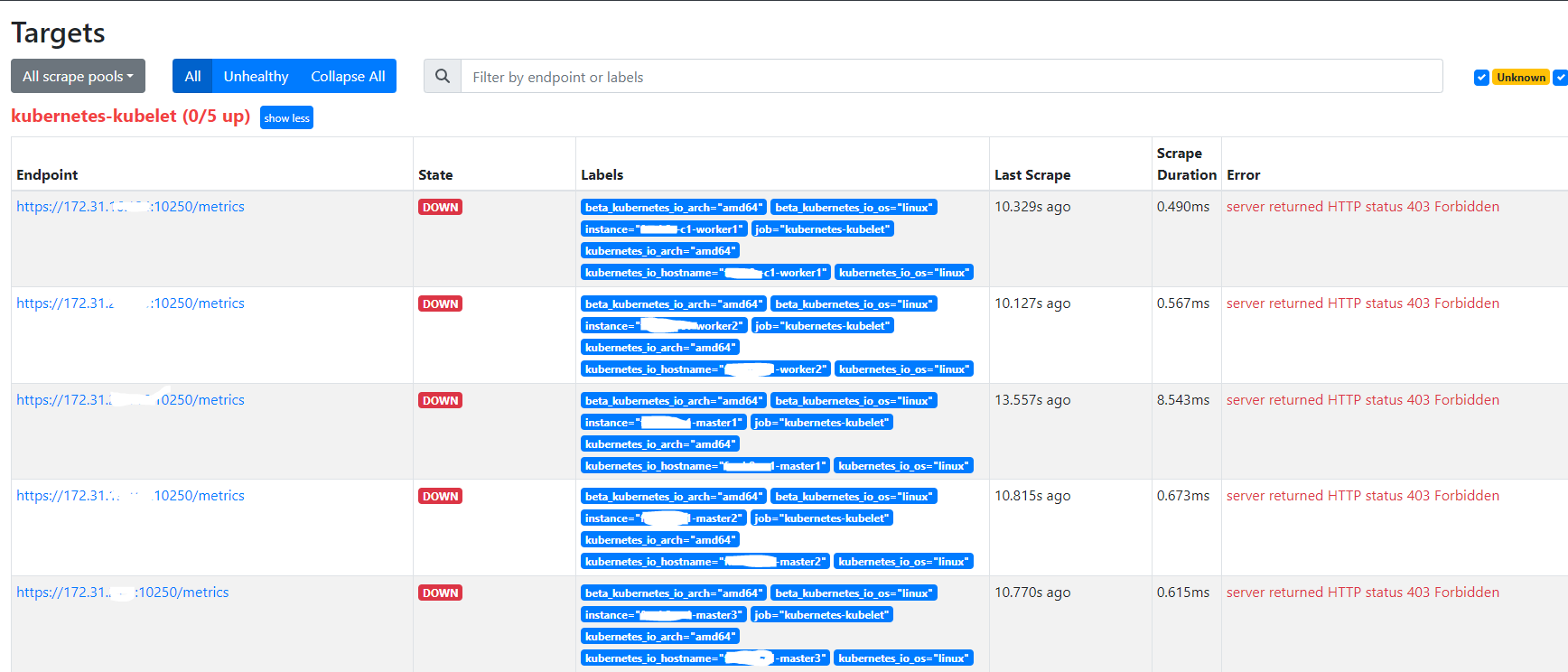
但是请求监控数据错误,返回:server returned HTTP status 403 Forbidden。根据日志提示,可能是因为权限原因被拒绝。
Prometheus 请求 Kubelet 使用的是 Token 鉴权 [5] 。基于 Kubernetes API Server 的 RBAC,大体流程为:
- Pod 使用启动时系统挂载的 Token (
/var/run/secrets/kubernetes.io/serviceaccount/token)向 kubelet 发起查询请求。 Prometheus 使用的 Token 路径是在配置文件中指定bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token - Kubelet 校验 Token 的权限
根据错误消息,可以猜测 Token 权限存在问题。以下步骤针对此猜测进行验证,其原理参考文档
- 登陆到 Prometheus 所在的 Pod,执行以下命令,模拟请求 Kubelet,从响应可以看到
Forbidden (user=system:serviceaccount:prometheus:default, verb=get, resource=nodes, subresource=metrics),说明 Pod 使用的user=system:serviceaccount:prometheus:defaultServiceAccount 账号没有权限,并且具体使用的权限为verb=get, resource=nodes, subresource=metricscurl -v -k -H "Authorization: Bearer `cat /var/run/secrets/kubernetes.io/serviceaccount/token`" https://172.31.19.164:10250/metrics
* Trying 172.31.19.164:10250...
* Connected to 172.31.19.164 (172.31.19.164) port 10250 (#0)
* using HTTP/2
* h2h3 [:method: GET]
* h2h3 [:path: /metrics]
* h2h3 [:scheme: https]
* h2h3 [:authority: 172.31.19.164:10250]
* h2h3 [user-agent: curl/8.0.1]
* h2h3 [accept: */*]
* h2h3 [authorization: Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6Ik51eFpuNU9MUlp2QkxmWjlxRVpVMjRYYVRpV3RSQk1HanJsRnBjbjJBSzQifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNzE2OTcwODc5LCJpYXQiOjE2ODU0MzQ4NzksImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlc]
* Using Stream ID: 1 (easy handle 0x7f1038310af0)
GET /metrics HTTP/2
Host: 172.31.19.164:10250
user-agent: curl/8.0.1
accept: */*
authorization: Bearer eyJhbGciOiJSUzI1NiIsImtpZCI6Ik51eFpuNU9MUlp2QkxmWjlxRVpVMjRYYVRpV3RSQk1HanJsRnBjbjJBSzQifQ.eyJhdWQiOlsiaHR0cHM6Ly9rdWJlcm5ldGVzLmRlZmF1bHQuc3ZjLmNsdXN0ZXIubG9jYWwiXSwiZXhwIjoxNzE2OTcwODc5LCJpYXQiOjE2ODU0MzQ4NzksImlzcyI6Imh0dHBzOi8va3ViZXJuZXRlc]
* TLSv1.3 (IN), TLS handshake, Newsession Ticket (4):
< HTTP/2 403
< content-type: text/plain; charset=utf-8
< content-length: 104
< date: Tue, 30 May 2023 08:22:34 GMT
<
* Connection #0 to host 172.31.19.164 left intact
Forbidden (user=system:serviceaccount:prometheus:default, verb=get, resource=nodes, subresource=metrics) - 检查 Prometheus Namespace 中的默认的 ServiceAccount 绑定的权限,其绑定到了名为
prometheus的 ClusterRolekubectl edit clusterrolebinding prometheus
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: default
namespace: prometheus - 检查名为
prometheus的 ClusterRole 的权限信息,可以看到其中没有对verb=get, resource=nodes, subresource=metrics的授权,将其添加到授权中,重新查看 Prometheus 的 Targets 中kubernetes-kubelet的状态,请求正常。kubectl edit clusterrole prometheus
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- nodes/proxy
- nodes/metrics
- services
- endpoints
- pods
verbs:
- get
- list
- watch
- apiGroups:
- extensions
resources:
- ingresses
verbs:
- get
- list
- watch
- nonResourceURLs:
- /metrics
verbs:
- get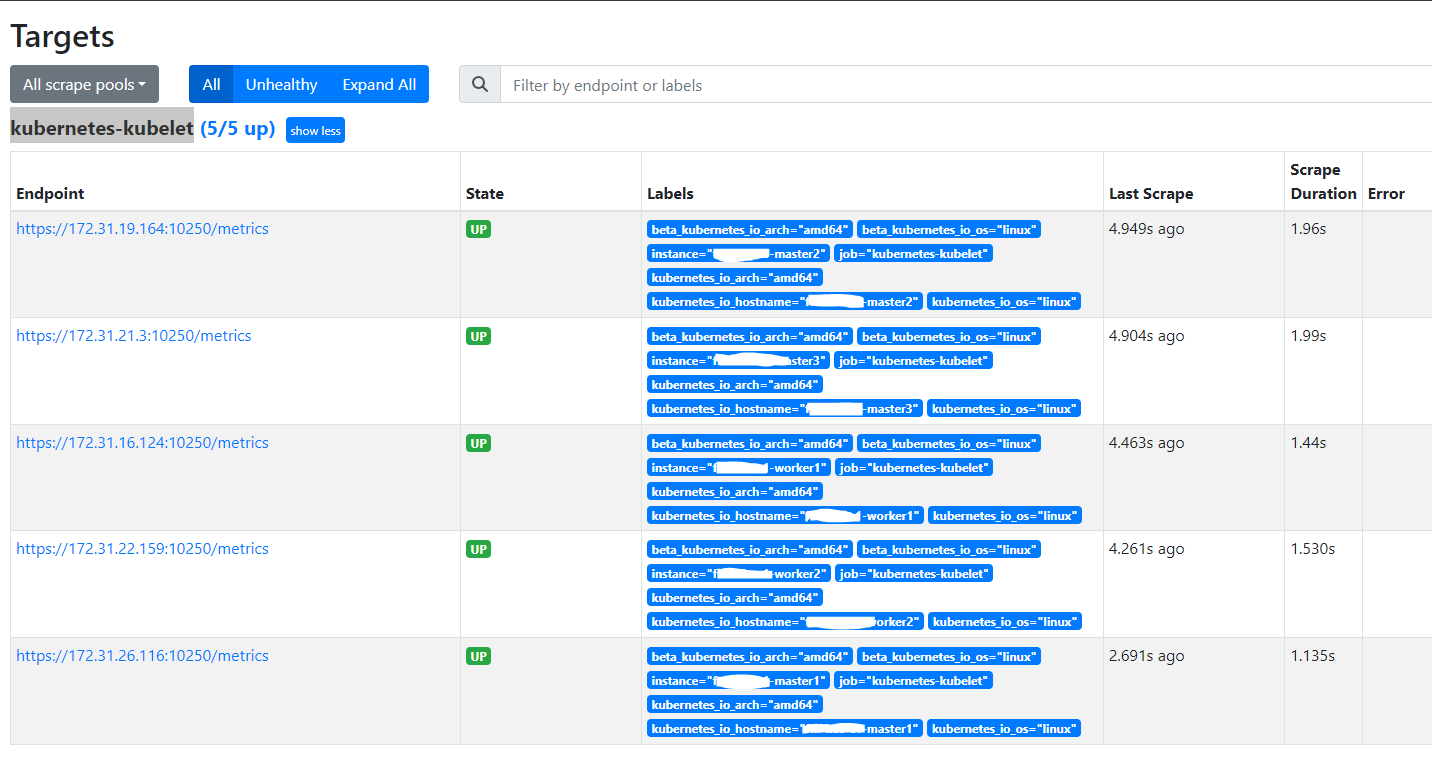
配置 Prometheus 从 cAdvisor 读取监控数据
各节点的 kubelet 组件中除了包含自身的监控指标信息以外,kubelet 组件还内置了对 cAdvisor 的支持。cAdvisor 能够获取当前节点上运行的所有容器的资源使用情况,通过访问 kubelet 的 /metrics/cadvisor 地址可以获取到 cadvisor 的监控指标,因此和获取 kubelet 监控指标类似,这里同样通过 node 模式自动发现所有的 kubelet 信息,并通过适当的 relabel 过程,修改监控采集任务的配置
global: |
以上配置生效后,查看 Prometheus 的 Targets 信息,正常会看到 cAdvisor 的 Target
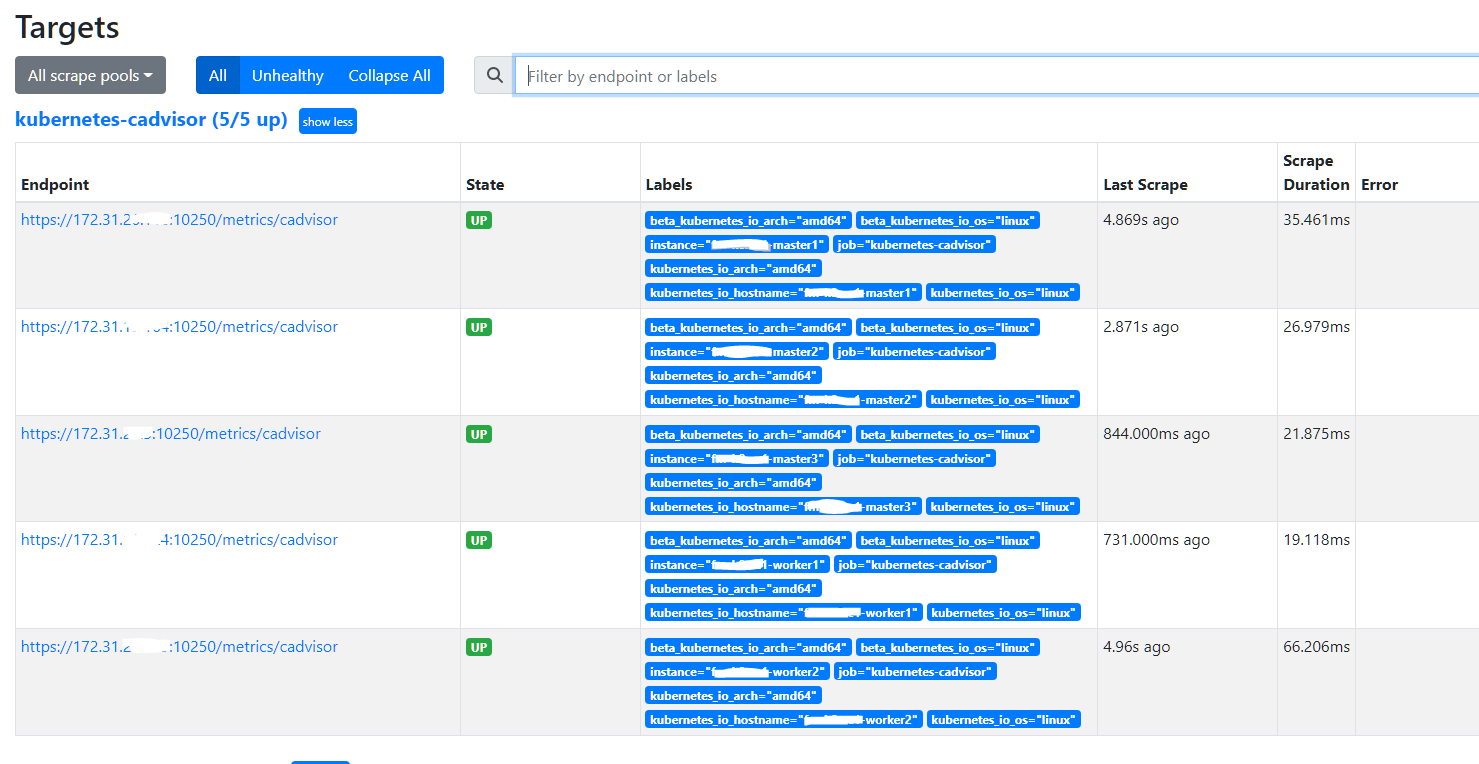
配置 Prometheus 抓取 Kubernetes 集群资源状态指标
要监控 Kubernetes 集群资源状态的相关指标,需要在 Kubernetes 中 部署 kube-state-metrics 组件。
在 Prometheus 配置文件中,添加一个新的监控目标以获取 kube-state-metrics 抓取的指标
global: |
要查看 kube-state-metrics 抓取的指标,可以在集群内访问 kube-state-metrics.kube-system.svc.cluster.local:8080/metrics 查看
etcd 组件监控
修改
etcd配置Kubernetes 集群的
etcd默认是开启暴露metrics数据的。查看etcd的 Pod 中容器的启动参数。其中--listen-metrics-urls=http://127.0.0.1:2381参数配置了 Metrics 接口运行在http://127.0.0.1:2381。这里默认使用了127.0.0.1监听,需要修改(所有节点)etcd的(静态 Pod)的配置文件/etc/kubernetes/manifests/etcd.yaml,将- --listen-metrics-urls=http://127.0.0.1:2381修改为 Prometheus 可请求的 IPkubectl get pods -n kube-system etcd -o yaml
spec:
containers:
- command:
- etcd
- --advertise-client-urls=https://172.31.26.116:2379
- --cert-file=/etc/kubernetes/pki/etcd/server.crt
- --client-cert-auth=true
- --data-dir=/var/lib/etcd
- --experimental-initial-corrupt-check=true
- --initial-advertise-peer-urls=https://172.31.26.116:2380
- --initial-cluster=fm-k8s-c1-master1=https://172.31.26.116:2380
- --key-file=/etc/kubernetes/pki/etcd/server.key
- --listen-client-urls=https://127.0.0.1:2379,https://172.31.26.116:2379
- --listen-metrics-urls=http://127.0.0.1:2381
- --listen-peer-urls=https://172.31.26.116:2380
- --name=k8s-master1
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-client-cert-auth=true
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --snapshot-count=10000
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
image: k8s.gcr.io/etcd:3.5.3-0为
etcd的 Pod 创建service在 堆叠(Stacked)
etcd拓扑 的高可用控制平面的架构下,etcd通常会运行在每个 master 控制节点上(多实例)。为了方便 Prometheus 监控,可以为etcdPod 创建 Headless ServiceapiVersion: v1
kind: Service
metadata:
name: k8s-etcd
namespace: kube-system
spec:
type: ClusterIP
clusterIP: None #设置为None,不分配Service IP
ports:
- port: 2381
targetPort: 2381
name: etcd-metrics-port
selector:
component: etcd创建成功后,可以检查以下 Service、Endpoints 信息是否正确。Service 没问题后,即可在 Prometheus 中通过 FQDN
k8s-etcd.kube-system.svc:2381/metrics抓取到etcd的指标。kubectl get pods -A -l component=etcd
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system etcd-ops-k8s-master1 1/1 Running 1 (17m ago) 20m
kube-system etcd-ops-k8s-master2 1/1 Running 0 15m
kube-system etcd-ops-k8s-master3 1/1 Running 0 15m
kubectl get services -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
k8s-etcd ClusterIP None <none> 2381/TCP 15s
kubectl get endpoints -n kube-system
NAME ENDPOINTS AGE
k8s-etcd 172.31.19.164:2381,172.31.21.3:2381,172.31.26.116:2381 33s
kubectl get pods -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
etcd-ops-k8s-master1 1/1 Running 1 (27m ago) 30m 172.31.26.116 ops-k8s-master1 <none> <none>
etcd-ops-k8s-master2 1/1 Running 0 25m 172.31.19.164 ops-k8s-master2 <none> <none>
etcd-ops-k8s-master3 1/1 Running 0 25m 172.31.21.3 ops-k8s-master3 <none> <none>
curl -v k8s-etcd.kube-system.svc:2381/metrics
* Trying 172.31.26.116:2381...
* Connected to k8s-etcd.kube-system.svc (172.31.26.116) port 2381 (#0)
GET /metrics HTTP/1.1
Host: k8s-etcd.kube-system.svc:2381
User-Agent: curl/7.80.0
Accept: */*
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Content-Type: text/plain; version=0.0.4; charset=utf-8
< Date: Wed, 04 Oct 2023 02:15:01 GMT
< Transfer-Encoding: chunked
<
HELP etcd_cluster_version Which version is running. 1 for 'cluster_version' label with current cluster version
TYPE etcd_cluster_version gauge
etcd_cluster_version{cluster_version="3.5"} 1
HELP etcd_debugging_auth_revision The current revision of auth store.
TYPE etcd_debugging_auth_revision gauge
etcd_debugging_auth_revision 1
HELP etcd_debugging_disk_backend_commit_rebalance_duration_seconds The latency distributions of commit.rebalance called by bboltdb backend.
TYPE etcd_debugging_disk_backend_commit_rebalance_duration_seconds histogram
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="0.001"} 5155
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="0.002"} 5155
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="0.004"} 5155
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="0.008"} 5155
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="0.016"} 5155Prometheus 中添加抓取
etcd指标的配置- job_name: 'kube-etcd'
metrics_path: /metrics
scheme: http
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_name]
regex: k8s-etcd
action: keep
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)Prometheus 中检查是否抓取到了
etcd指标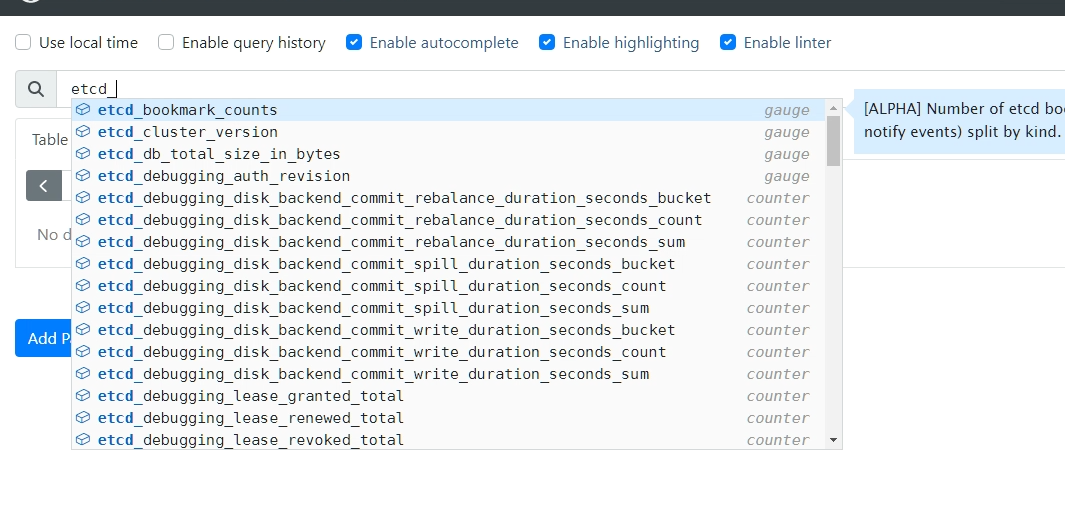
Scheduler 组件监控
修改 Scheduler 监听 IP 地址
Scheduler 组件默认监听在
127.0.0.1:10259(hostNetwork: true类型的网络,监听在主机 network Namespace)netstat -anutp | grep -v -E "TIME_WAIT|ESTABLISHED" | grep schedule
tcp 0 0 127.0.0.1:10259 0.0.0.0:* LISTEN 24770/kube-schedule修改 所有 Master 节点 上的
kube-scheduler配置/etc/kubernetes/manifests/kube-scheduler.yaml,将监听地址修改为- --bind-address=0.0.0.0/etc/kubernetes/manifests/kube-scheduler.yaml spec:
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=0.0.0.0
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
image: k8s.gcr.io/kube-scheduler:v1.24.8修改后,
kube-scheduler的 Pod 会自动重启(静态 Pod),重启后kube-scheduler会监听所有 IP 地址netstat -anutp | grep -v -E "TIME_WAIT|ESTABLISHED" | grep schedule
tcp6 0 0 :::10259 :::* LISTEN 27244/kube-schedule为
kube-scheduler的 Pod 创建service参考以下配置,为
kube-scheduler的 Pod 创建serviceapiVersion: v1
kind: Service
metadata:
name: k8s-scheduler
namespace: kube-system
spec:
type: ClusterIP
clusterIP: None #设置为None,不分配Service IP
ports:
- port: 10259
targetPort: 10259
name: k8s-scheduler-metrics-port
selector:
component: kube-schedulerPrometheus 中添加抓取
kube-scheduler指标的配置- job_name: 'kube-scheduler'
metrics_path: metrics
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_name]
regex: k8s-scheduler
action: keep
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
Controller Manager 组件监控
Controller Manager 组件默认监听 127.0.0.1:10257,修改 kube-controller-manager 配置 /etc/kubernetes/manifests/kube-controller-manager.yaml,将监听地址修改为 - --bind-address=0.0.0.0
netstat -anutp | grep -v -E "TIME_WAIT|ESTABLISHED" |grep contr |
为 kube-controller-manager 创建 service
apiVersion: v1 |
Prometheus 中添加抓取 kube-controller-manager 指标的配置
- job_name: 'kube-controller-manager' |
kube-proxy 组件监控
kube-proxy 的 Metrics 默认监听在 127.0.0.1:10249,执行命令 kubectl edit configmap kube-proxy -n kube-system 修改其监听地址
metricsBindAddress: "0.0.0.0:10249" |
修改配置后,重启 kube-proxy,检查监听地址,确定为 :::10249
kubectl get pods -n kube-system |
为 kube-proxy 创建 service
apiVersion: v1 |
Prometheus 中添加抓取 kube-proxy 指标的配置
- job_name: 'kube-proxy' |
CoreDNS 组件监控
CoreDNS 组件默认就开启了 Metrics 接口,Endpoint 为 kube-dns.kube-system.svc:9153/metrics
kubectl get services -n kube-system |
因此监控 CoreDNS 只需要使用 Prometheus 的服务发现添加抓取 CoreDNS 的相关配置即可。
- job_name: 'kube-dns' |
配置 Prometheus 抓取 Ingress-Nginx 指标
参考
ingress-nginx官方提供的 Prometheus 自动发现ingress-nginx的配置 [9]global:
scrape_interval: 10s
scrape_configs:
- job_name: 'ingress-nginx-endpoints'
kubernetes_sd_configs:
- role: pod
namespaces:
names:
- ingress-nginx
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- source_labels: [__meta_kubernetes_service_name]
regex: prometheus-server
action: drop配置
ingress-nginx的 Deployment,添加端口配置,本示例中 Ingress-Nginx 端口类型为hostNetwork: true。如果 Ingress-Nginx 使用了 Service,需要配置 Service 暴露相关端口。- containerPort: 10254
hostPort: 10254
name: prometheus
protocol: TCP配置
ingress-nginx的 Deployment,添加 Pod 针对 Prometheus 监控的注释
spec:
template:
metadata:
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "10254"
部署后,在 Prometheus UI 中检查 nginx_ingress.* 相关指标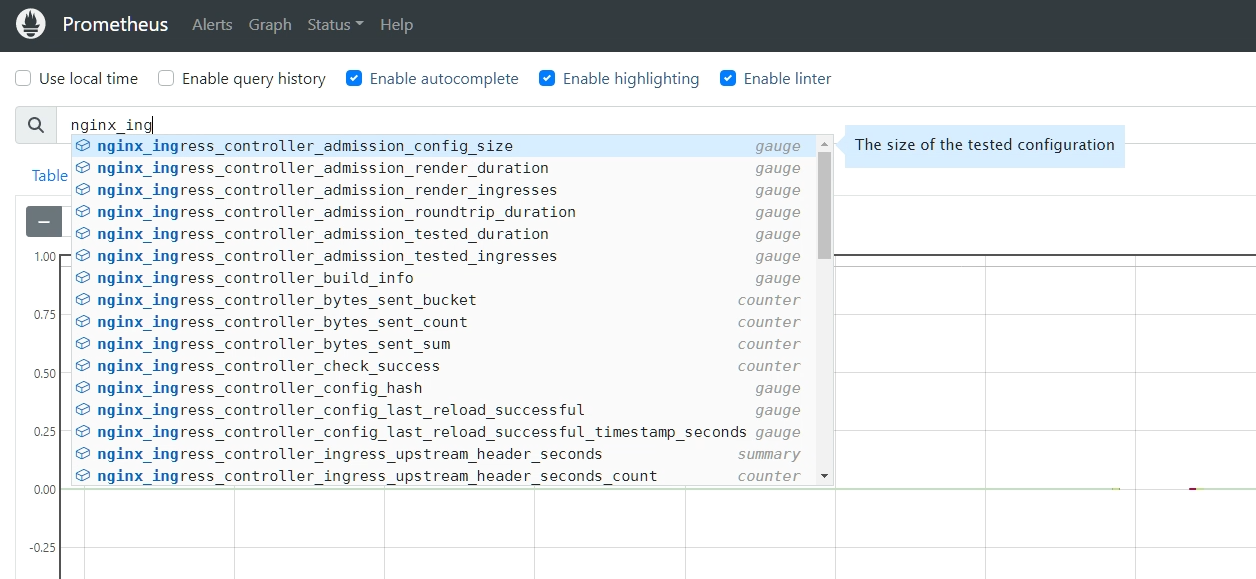
常见错误
failed to list *v1.Pod: pods is forbidden: User "system:serviceaccount:prometheus:default" cannot list resource "pods" in API group "" at the cluster scope”
部署 Prometheus 后,无法访问,检查 Pod 日志,显示错误: failed to list *v1.Pod: pods is forbidden: User \"system:serviceaccount:prometheus:default\" cannot list resource \"pods\" in API group \"\" at the cluster scope" [2]
根据输出,应该是因为 Namespace prometheus 中的 ServiceAccount 账号 default 无相关权限导致,此权限是于 此处配置,检查相关账号权限。
kubectl describe clusterrole prometheus |
正常配置的 RBAC 账号输出如上,如果权限显示异常,需要重新检查 此处配置 是否正常,如文件格式是否正确。本示例中是因为 yaml 文件格式导致 clusterrolebinding 绑定异常,输出结果如下
kubectl describe clusterrolebinding prometheus |
更正文件格式后,重新 kubectl apply ,Prometheus Server 部署正常。
server returned HTTP status 400 Bad Request
Prometheus 配置服务自动发现监控 Kubernetes 的 Node 后,Node 状态显示为 DOWN,Error 为 server returned HTTP status 400 Bad Request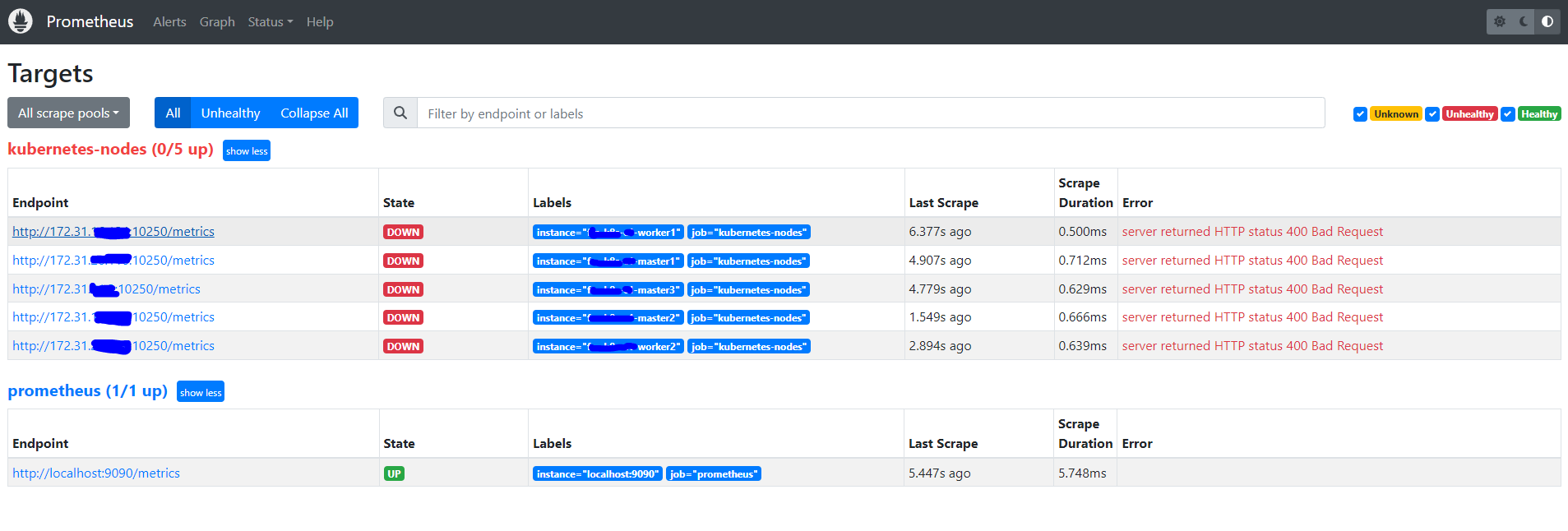
这个是因为 prometheus 去发现 Node 模式的服务的时候,访问的端口默认是10250。而默认是需要认证的 https 协议才有权访问的,但实际上我们并不是希望让去访问 10250 端口的 /metrics 接口,而是 node-exporter 绑定到节点的 9100 端口,所以我们应该将这里的 10250 替换成 9100。 [4]
opening storage failed: lock DB directory: resource temporarily unavailable
Prometheus Server 无法启动,查看 Pod 日志,显示以下错误
kubectl logs prometheus-deployment-6967df46c6-znj2k -n prometheus |
解决方法 : 删除 Prometheus Server 数据目录下的 lock 文件,重新启动
ls |
cAdvisor 获取 Pod 指标元数据异常
环境信息
- Centos 7
- Kubernetes 1.24
- Prometheus 2.44.0
- Docker Engine - Community 20.10.9
- containerd containerd.io 1.6.9
在 Prometheus UI 中查询指标 container_network_transmit_bytes_total,输出中没有 container、name、pod 等指标,甚至未输出 Pod 的网卡流量的指标。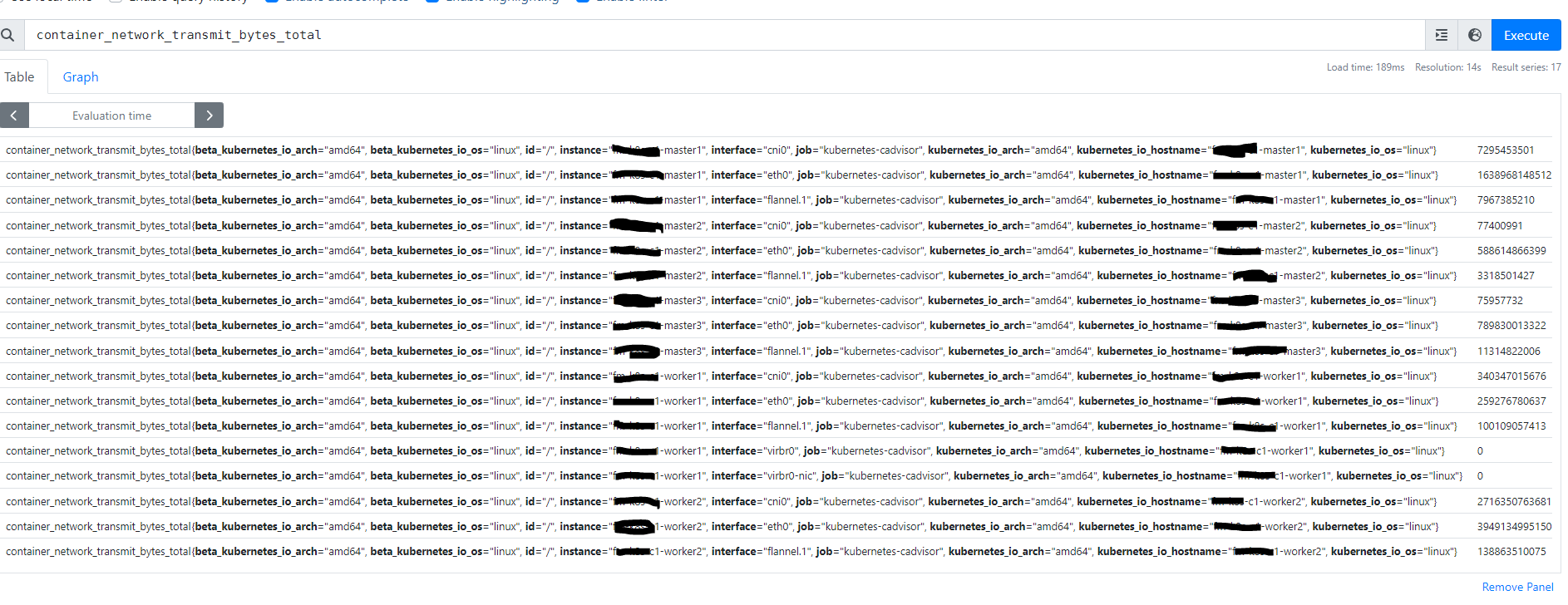
container_network_transmit_bytes_total 指标是 Kubelet 从 cAdvisor 中读取到的,为了排查问题出现的地方,尝试直接访问 Kubelet 获取此指标的数据
curl -k -H "Authorization: Bearer `cat /var/run/secrets/kubernetes.io/serviceaccount/token`" https://172.31.26.116 |
从结果可以看到,Kubelet 就未获取到相关指标及标签。Kubelet 是从 cAdvisor 获取到的容器的 Lables。如果是 Docker,主要是读取容器的 Inspect 信息获取标签(Config.Labels),检查容器的 Inspect 信息,发现是存在完整的 Lables 信息 [8]
docker inspect 6b2b9d1b3a62 |
从以上分析可以确定,问题应该是出在 cAdvisor 未获取到 Docker 容器中的 Labels 信息。
问题原因一直未找到,尝试 将 Kubelet 使用的 CRI 由 Docker 更改为 Containerd,更改后,再次在 Prometheus UI 中查看 container_network_transmit_bytes_total,发现改 Containerd 作为 CRI 的 Kubelet 节点采集的指标标签中已经包含了 Pod、namespace、image 等标签
参考文档
使用 Prometheus 监控 Kubernetes 集群节点