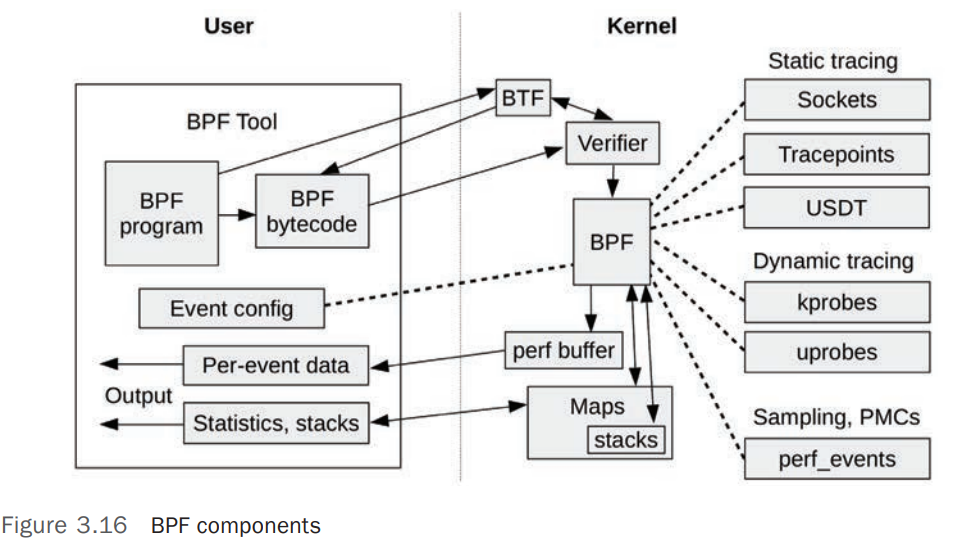
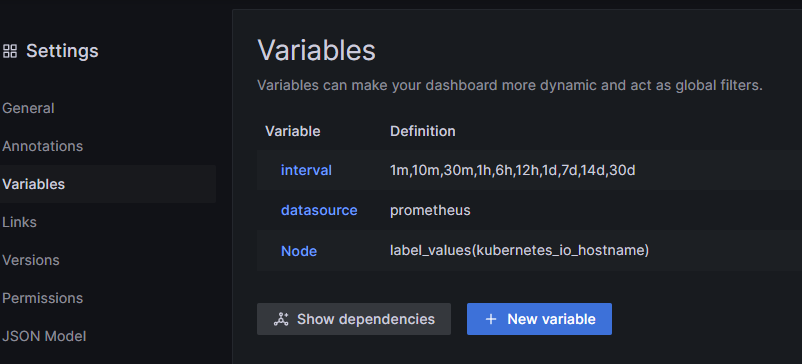
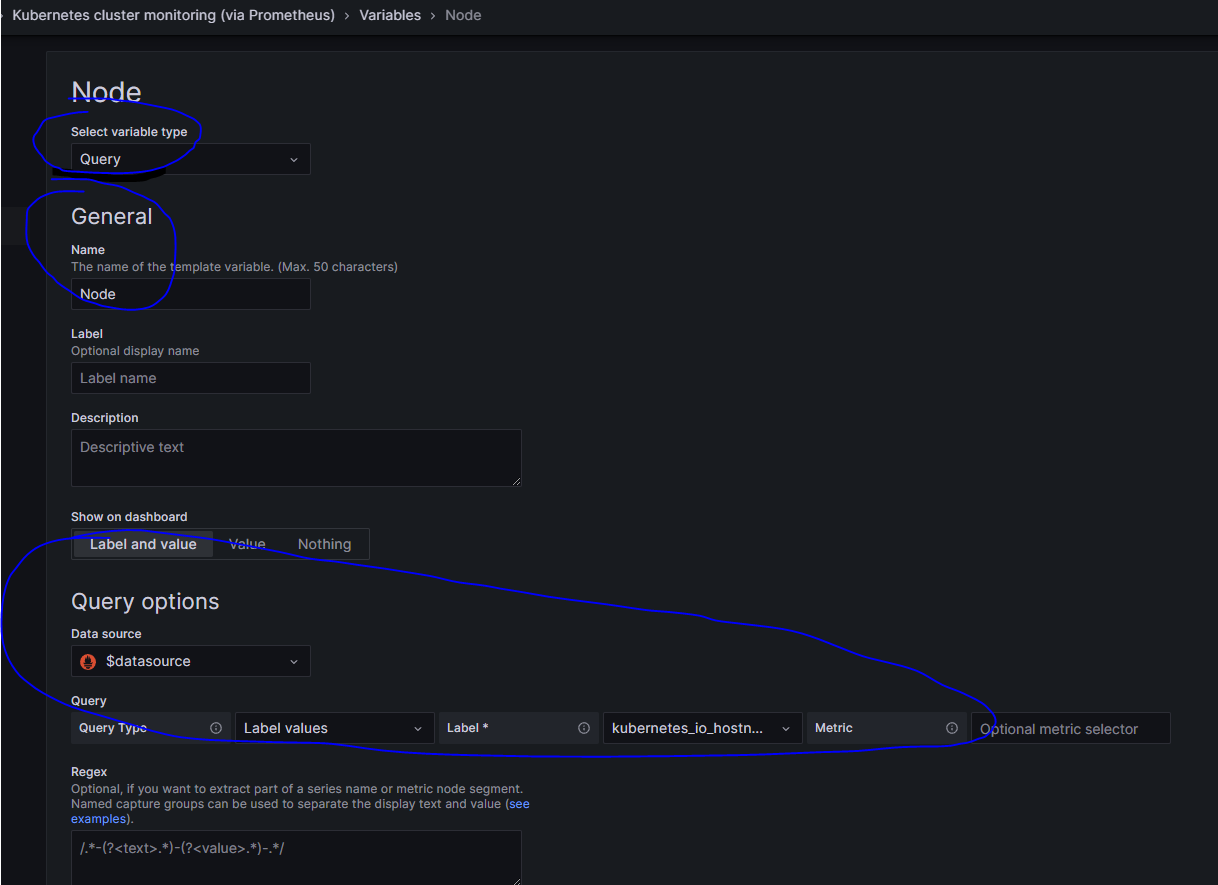
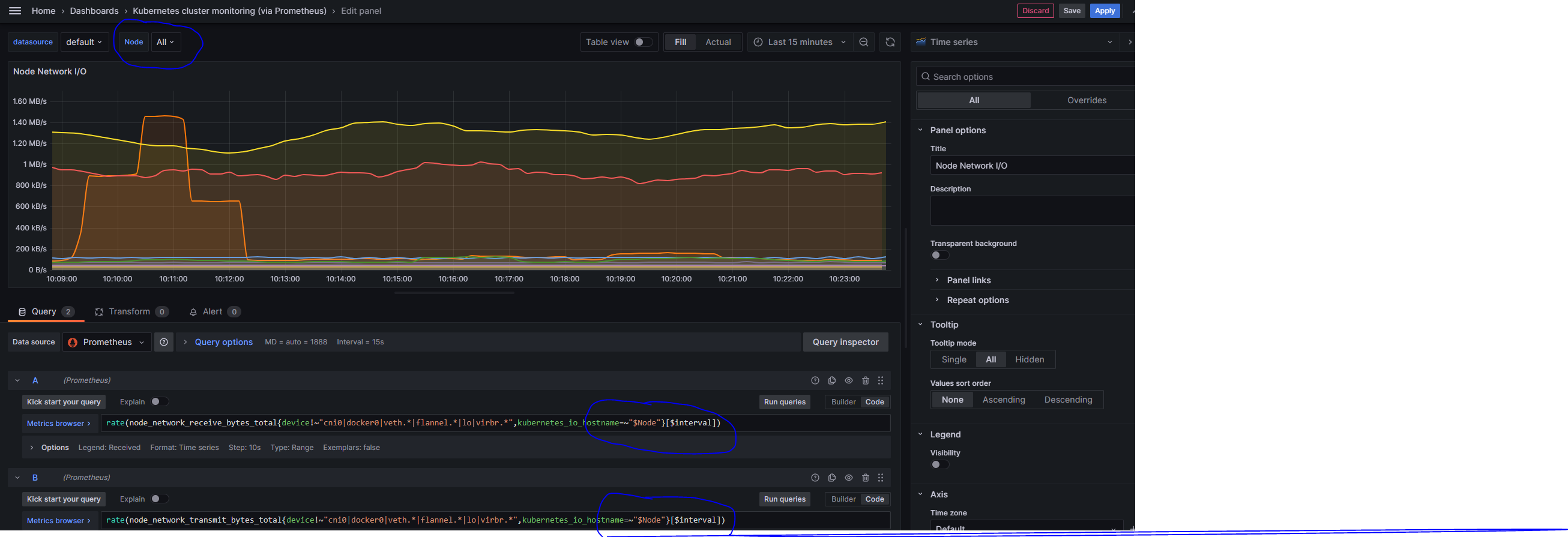
注意事项: Ansible 使用字典顺序加载配置文件,如果在不同的配置文件中配置了 parent groups 和 child groups,那么定义 child groups 的配置要先用定义 parent groups 的文件加载,否则 Ansible 加载配置会报错: Unable to parse /path/to/source_of_parent_groups as an inventory source[4]
DO $$ BEGIN IF NOT EXISTS (SELECT FROM pg_catalog.pg_roles WHERE rolname = 'zabbix') THEN CREATE ROLE zabbix LOGIN PASSWORD 'ReplaceMe_SuperStrong_Zabbix'; END IF; END $$;
initdb/02-create-timescaledb.sql
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;
initdb/03-create-db.sql
GRANT ALL PRIVILEGES ON DATABASE zabbix TO zabbix; ALTER DATABASE zabbix OWNER TO zabbix;
Postgresql 主配置 config/postgresql.conf
config/postgresql.conf
listen_addresses = '*' port = 5432 max_connections = 200
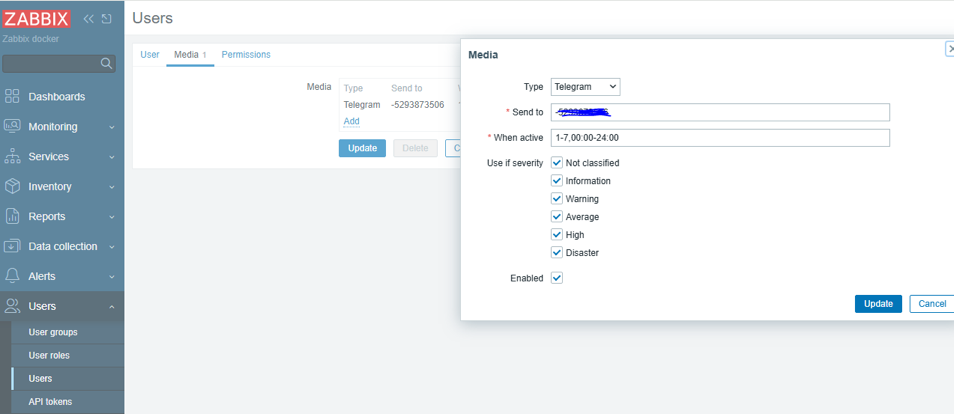
为了将不同的告警发送给不同的用户,首先需要为每个用户添加 Media,以 Admin 用户为例,为其添加 Media。定位到 Users -> Users: Admin -> Media -> Add ,以添加 Telegram 为例,在 Send to 中填入 群组 ID
配置 Medias 。定位到 Alerts -> Media types 。Zabbix Server 已经配置了非常多可用的告警 Medias,选择 Telegram,将 api_token 修改为你自己的 Telegram Bot API Token,确保配置中的 api_chat_id 的值为 {ALERT.SENDTO}
不要在这里硬编码 api_chat_id ,否则使用 Telegram 这个渠道只能将所有的消息发送到同一个群组,无法达到告警分流的作用,正确做法是将其配置为 {ALERT.SENDTO} ,当用户 Media 被调用时,会自动使用用户 Media 变量 Send to 的值达到告警分流到不通用户的 Media
# kubectl get nodes E0325 15:37:50.808781 3442105 memcache.go:265] "Unhandled Error" err="couldn't get current server API group list: the server could not find the requested resource" E0325 15:37:50.814831 3442105 memcache.go:265] "Unhandled Error" err="couldn't get current server API group list: the server could not find the requested resource"
K3S 依赖宿主机的 /etc/resolv.conf ,如果其中配置了 nameserver 127.0.0.53 会导致容器无法解析外部域名而不可用,需要修改为容器可以访问的 DNS 地址,如 8.8.8.8
WARN EACCES user “root” does not have permission to access the dev dir “/root/.node-gyp/11.15.0” ERR! stack Error: EACCES: permission denied, mkdir ‘node_modules/sqlite3/.node-gyp’
# docker compose exec -it elasticsearch bin/elasticsearch-setup-passwords interactive ****************************************************************************** Note: The 'elasticsearch-setup-passwords' tool has been deprecated. This command will be removed in a future release. ******************************************************************************
Initiating the setup of passwords for reserved users elastic,apm_system,kibana,kibana_system,logstash_system,beats_system,remote_monitoring_user. You will be prompted to enter passwords as the process progresses. Please confirm that you would like to continue [y/N]y
Enter password for [elastic]: Reenter password for [elastic]: Enter password for [apm_system]: Enter password for [apm_system]: Reenter password for [apm_system]: Enter password for [kibana_system]: Reenter password for [kibana_system]: ... Changed password for user [beats_system] Changed password for user [remote_monitoring_user] Changed password for user [elastic]
重置 elastic 用户密码
# docker compose exec elasticsearch bin/elasticsearch-reset-password -u elastic This tool will reset the password of the [elastic] user to an autogenerated value. The password will be printed in the console. Please confirm that you would like to continue [y/N]y
Password for the [elastic] user successfully reset. New value: GjJadE-ihZJ+Ddb5SvKs
# GET /_cat/nodes?v&h=name,ip,node.role,master name ip node.role master vp-elk-3 172.31.25.106 cdfhilmrstw - vp-elk-2 172.31.24.61 cdfhilmrstw * vp-elk-1 172.31.29.164 cdfhilmrstw -
mmaster
ddata
i **ingest
检查分片分布
# GET /_cat/shards?v index shard prirep state docs store dataset ip node .kibana_analytics_8.12.2_001 0 p STARTED 5 2.3mb 2.3mb 172.31.24.61 vp-elk-2 .kibana_analytics_8.12.2_001 0 r STARTED 5 2.3mb 2.3mb 172.31.29.164 vp-elk-1 .internal.alerts-observability.apm.alerts-default-000001 0 p STARTED 0 249b 249b 172.31.24.61 vp-elk-2 .internal.alerts-observability.apm.alerts-default-000001 0 r STARTED 0 249b 249b 172.31.29.164 vp-elk-1 .ds-.kibana-event-log-ds-2026.03.13-000001 0 p STARTED 1 6.3kb 6.3kb 172.31.25.106 vp-elk-3
检查索引状态
# GET /_cat/indices?v health status index uuid pri rep docs.count docs.deleted store.size pri.store.size dataset.size green open .internal.alerts-observability.logs.alerts-default-000001 QQ1ALFIwTS6Cr1IUjp384w 1 1 0 0 498b 249b 249b green open .internal.alerts-observability.threshold.alerts-default-000001 UzpYLZbzTMyK2yCYnmayKw 1 1 0 0 498b 249b 249b green open .kibana-observability-ai-assistant-kb-000001 yV9I-sIMQgyf0edNxw1kPA 1 1 0 0 498b 249b 249b green open .internal.alerts-observability.apm.alerts-default-000001 0HOJ4bCgT_2X4c29FryFCw 1 1 0 0 498b 249b 249b green open .internal.alerts-stack.alerts-default-000001 NJCmcGptQOWG6rd0I259Uw 1 1 0 0 498b 249b 249b green open .internal.alerts-observability.slo.alerts-default-000001 rSSFxAYfR0O9L9XXBIpZlA 1 1 0 0 498b 249b 249b green open .internal.alerts-ml.anomaly-detection.alerts-default-000001 fT9FJoirRiSMVXx1V3F7dQ 1 1 0 0 498b 249b 249b green open .internal.alerts-observability.metrics.alerts-default-000001 E9vjU7WETSebjg8Y_ddPHw 1 1 0 0 498b 249b 249b
检查 Master 选举
# GET /_cat/master?v id host ip node 5hG_mSEjRd6Ov-rClowAoQ 172.31.24.61 172.31.24.61 vp-elk-2
只有一个 Master 就正常
检查 JVM Heap
# GET /_cat/nodes?v&h=name,heap.percent name heap.percent vp-elk-3 20 vp-elk-2 48 vp-elk-1 57
# journalctl -f -u filebeat {"type":"illegal_argument_exception","reason":"Validation Failed: 1: this action would add [2] total shards, but this cluster currently has [6924]/[3000] maximum shards open;"}
错误消息 {"type":"illegal_argument_exception","reason":"Validation Failed: 1: this action would add [2] total shards, but this cluster currently has [6924]/[3000] maximum shards open;"} 显示当前集群已有 6924 个分片,超过了 3000 个的限制。
filebeat 启动后报错,elasticsearch 上未创建相应的索引,关键错误信息 Failed to connect to backoff(elasticsearch(http://1.57.115.214:9200)): Connection marked as failed because the onConnect callback failed: resource 'filebeat-7.5.2' exists, but it is not an alias
journalctl -f -u filebeat INFO [index-management] idxmgmt/std.go:269 ILM policy successfully loaded. ERROR pipeline/output.go:100 Failed to connect to backoff(elasticsearch(http://1.57.115.214:9200)): Connection marked as failed because the onConnect callback failed: resource 'filebeat-7.5.2' exists, but it is not an alias INFO pipeline/output.go:93 Attempting to reconnect to backoff(elasticsearch(http://1.57.115.214:9200)) with 3 reconnect attempt(s) INFO elasticsearch/client.go:753 Attempting to connect to Elasticsearch version 7.6.2 INFO [index-management] idxmgmt/std.go:256 Auto ILM enable success. INFO [index-management.ilm] ilm/std.go:138 do not generate ilm policy: exists=true, overwrite=false INFO [index-management] idxmgmt/std.go:269 ILM policy successfully loaded. ERROR pipeline/output.go:100 Failed to connect to backoff(elasticsearch(http://1.56.219.122:9200)): Connection marked as failed because the onConnect callback failed: resource 'filebeat-7.5.2' exists, but it is not an alias INFO pipeline/output.go:93 Attempting to reconnect to backoff(elasticsearch(http://1.56.219.122:9200)) with 3 reconnect attempt(s)