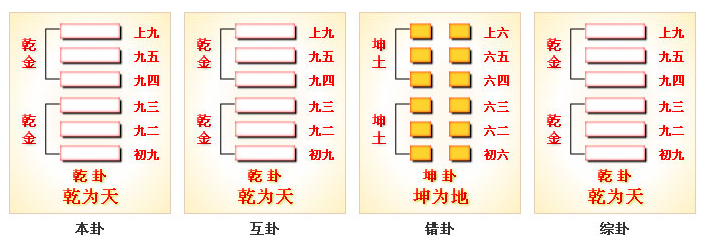
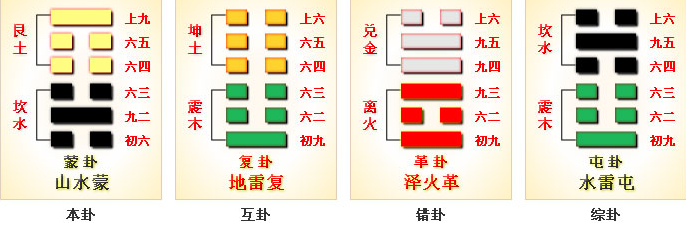
六十四卦之水雷屯
水雷屯
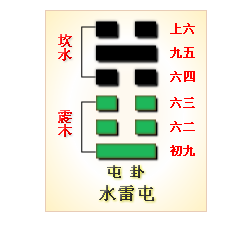
屯(zhun)卦,是 《周易》继乾、坤卦后首个揭示 事物初创阶段规律 得核心卦象。屯卦 下震上坎、震为雷为足为动、坎为水为云、内动外险,涉足入险,不可轻动 ,象征 万物萌芽(初生)、草昧未开、事业初创时的 艰难(勿用 为现实约束、阻力)与希望(元亨利贞为根本潜力)并存
元,亨,利,贞。勿用有攸往。利建侯。 |
屯,刚柔始交而难生。动乎险中,大亨贞。雷雨之动满盈。天造草昧,宜建侯而不宁。 |
象曰:云雷屯;君子以经纶。 |
- 建侯 : 侯,地基、基础、根基。建侯,打好根基,做事情之前先建立稳固得根据和团队。
- 刚柔始交而难生 : 刚柔始交,指乾(刚健)与坤(柔顺)的力量首次交汇,是 万物初创的起点(如天地初开、阴阳交汇生万物) ; 难生 指 刚柔交汇时尚未形成稳定平衡,故产生艰难(事物初生,根基不稳,环境有挑战)
- 动乎险中,大亨贞 : 震为雷为动,坎为水(云)为险,事物虽然刚刚萌生,力量尚弱,根基不稳,面临艰难(难),但只要依正道(驯致其道,建侯),结果必然不错(大亨贞)
- 雷雨之动满盈,天造草昧 : 天地初创(阴阳初交),雷雨交加,万物萌生却混沌未判。 雷雨之动 象征 初创时既有推动发展得力量、生机活力(雷),又有滋养生长的资源(环境,雨),但(雷雨)满盈,意味着 环境 充满变数、混乱无序(如同雷雨天气的 狂暴与不确定) 。 天地草昧 指 天地创造万物时一片蒙昧、尚未开化,象征 初创领域规则未立、格局未定
- 经纶 : 理丝曰经,编丝曰纶,经为纵丝,纶为横丝,通常还以经指战略、纶指战术。整理丝缕,喻筹划、布局、分条理于混乱之中,引申为 治理天下、筹划大业、规划全局。
元,亨,利,贞 为 卦之四德,乾为万物之父,四德齐备。坤卦为万物之母,顺承于乾,在四德上有了一定限制,如 利牝马之贞。除乾坤之外,四德齐备的卦还有 屯、随、无妄、革 四卦 。这四卦的四德与乾坤的四德取义又有不同,四德的大体是具备的,但在普遍性、永恒性方面要小一些、差一等。 元 不再是创始、创造,而是开始。亨,是运动的顺利,不再是永久、持久的亨通。利,只是对自身有利,不再是对万物普遍性的有益。贞,是守正,不再是永久的正确不变。
屯卦是万物刚刚开始出生,有了繁衍发展的基础,持续发展下去会欣欣向荣,故有 元,亨,利,贞的特点。
“有天地,然后万物生焉。盈天地之间者惟万物,故受之以屯。屯者,盈也。” 乾坤两卦后,接着是屯卦,“雷雨之动满盈”,震为雷,坎为雨,春雷发动,唤醒万物,春雨滋润,哺育万物,雷雨一动,万物齐出,盈满天地,象征屯之盈满。
“屯,难也。像草木之初生,屯然而难。” 万物初生,如草木发于地下,艰难破土,始生不易,故有艰难之意。始生还未伸展开,故有团聚之意。万物始生,从无到有,故有充盈之意。
初九
盘桓,利居贞,利建侯。 |
象曰:虽盘桓,志行正也。以贵下贱,大得民也。 |
- 盘桓 : 徘徊盘旋。有阻力、有困难,无法直线前进,只能回环前进。
- 利居贞,利建侯 : 居,停留、坚守。贞,正道、根本。初创之期,阻碍多、根基不稳、方向不明,此时不应急于行动(不妄动),应先打好基础、巩固根基、凝聚基层,以待时(利建侯)
- 志行正也 : 虽面临困难,但是坚守正道、不偏离根本(居贞),内在的志向与行动方向(万物始生,困难阻力多,但天地生生之德,合乎天地正道)是正确的,不是消极等待,而是为未来积极准备、蓄力(居贞、建侯)
- 以贵下贱,大得民也 : 贵,指初九阳爻;下,指初九阳爻(贵)居于下位(最小爻位)。核心力量(贵)主动放下姿态,贴近基层(下,贱),最终能广泛凝聚基层支持,为后续发展奠定根基
初九阳爻居阳为,位正,正应六四,守正而不偏,有利。
以贵下贱,大得民也。6t易经中,刚(阳)爻为贵,柔爻(阴爻)为贱,初九在三个柔爻之下,象征以尊贵身份居卑贱的阴爻之下,有谦恭敬人之美德
古人注解 :
王弼
磐桓者,难也。难而不进,居正以待,建侯以辅,故利也。程颐
屯之初难,宜磐桓以待时。虽不进,然志在正,不失其道。贵而能下贱,得众人之心。朱熹
屯难之始,宜磐桓以待,居贞则利。初九阳刚在下,以贵而下贱,能得民心,利于建侯也。
六二
屯如邅如,乘马班如。匪寇婚媾,女子贞不字,十年乃字。 |
象曰:六二之难,乘刚也;十年乃字,反常也。 |
- 屯如邅(zhan)如 : 屯,困难、艰难险阻、草木破土未伸、难行; 邅,阻滞不前、转、盘旋、徘徊不前。六二前临互卦艮,艮为阻为止,正应九五,九五在坎中,坎为险难,前进艰难险阻,困难重重,故为 屯如邅如
- 乘马班如 : 班,分瑞玉也(古代帝王将玉分割赐给诸侯,玉原本为整体,分割后则 分散归属),分割、分散、无序,也有说通 盘,盘桓、盘旋 。乘马班如,马匹无序排列,无法统一前进,象征行动不顺,力量不一。
- 匪寇婚媾 : 不是盗寇(象征危险、对立、危险),而是联姻(合作、机遇)。九五在坎中,坎为盗寇,六二正应九五,上下阴阳正应,婚姻匹配正合,故言 匪寇婚媾
- 女子贞不字,十年乃字 : 字,许嫁、出嫁成亲,另有怀孕、生育之说。女子,象征柔顺(阴),六二处中正之位,贞。 震是反生稼,稼是禾稼,反生是该生不生,不该生而生,该向上生而向下生,该向下生而向上生。六二在震里,反生,故不字 。六二在互卦坤中,坤数为十,故 十年不字
- 乘刚 : 乘刚 指 六二阴爻 乘坐 在初九阳爻之上(爻位上六二居初九之上),象征 柔顺的辅助者(六二,女子)试图承载或推动刚健的核心力量(初九),却因自身阴柔力量不足,无法匹配刚健力量的强度与节奏,反而被刚健力量的惯性拖入困境。
- 十年乃字,反常也 : 反常,指返回常道。
古人注解 :
王弼
屯难也。六二以阴居阴,得中而应于六五,然上承九三之刚,故屯如邅如。然上承九三之刚 ,指 屯卦第三爻,阴爻居阳位,爻性为阴(柔),爻位为阳(刚,第三爻爻位为阳、刚)
程颐
婚媾者,合也。虽似为难,非寇害也。女子守贞,不字于今,待久乃合。朱熹
乘马班如,进退无常。匪寇而婚,非害也。女子守贞,十年乃字,必待时也。
六三
既鹿无虞,惟入于林中,君子几不如舍,往吝。 |
象曰:既鹿无虞,以纵禽也。君子舍之,往吝穷也。 |
- 既鹿无虞 : 即鹿,追逐、寻找、猎取猎物;虞,古代执掌山林、兼作向导得官员
- 君子几不如舍 : 几,征兆、时机。即鹿无虞,惟入于林中,君子见到风险、危机征兆,应放弃,若 继续盲目前进,必然遭遇凶险。核心是 在风险显现前主动止损,而非在风险爆发后被动承受。
- 即鹿无虞,纵禽也 : 即鹿无虞,不但会导致猎物(机会)丢失,还会导致风险(入于林中)
- 君子舍之,往吝穷也 : 即鹿无虞,惟入于林中,君子如果还继续追逐,不但会导致机会丢失(纵禽),还会使自己深陷林中,使吝(凶险)升级为穷(绝境)
六三阴爻(爻性)居阳位(爻位),不当位,下乘六二(柔爻,辅助者,无足够资源、支撑),上承六四(柔爻,上层,无明确指导、方向),处于 上下无刚健支撑 的孤立状态,如同 捕猎者无虞,若妄动(凭感觉),易陷入危险(惟入于林中) 。六三处下卦震之极,上临坎险(林中),正是动而遇险的象。
事物初创之期,面对风险(基础环境不稳、资源不足、方向不定、风险不可控),应理性得主动舍弃机遇,不盲目前行(君子几不如舍),导致遭遇风险(扩大风险,往吝)。初创期得核心资源(资金、人力、信任)都及其宝贵,若因冒进而损失(沉没成本),则后续再遇机会,也无力把握,此时得 舍 是 保住根基,留待未来
古人注解 :
王弼
既鹿无虞,失道而进也。惟入林中,危而无获也。程颐
鹿者,利也。无虞而逐之,必失道而纵禽。君子知几,不如舍之,若往则吝穷。朱熹
逐利而无所导,则失道而纵禽。君子知几而舍之,不往则已,往则吝穷矣。
六四
乘马班如,求婚媾, 往吉,无不利。 |
象曰:求而往,明也。 |
- 求婚媾,往吉 : 求 为 主动寻求、积极对接。婚媾 ,应爻在初九,为正应,男女相悦,婚姻好合。
- 求而往,明也 : 六四爻无不利,求而往,明也,六四紧邻九五,不能上合九五,九五虽是阳爻,但是正应在六二,六四能舍九五从初九,为明智之选。
六四爻居上卦初爻,阴爻(爻性)居阴位(爻位),得正位,下(正)应初九,上承九五尊位(阳刚之主、核心刚健力量),形成 柔得正而应刚 的最佳格局。在屯卦 动乎险中 的大背景里,六四已脱离下卦震之 动,进入上卦坎之 险,但本身得位又得援(下应初九,上承九五,无不利),故能把 班如 的无序静止转为有利行动。
古人注解 :
王弼
班如,不进也。欲进而未得,若能求正应以相合,则无不利。程颐
六四以阴居阴,得其位,近于尊,不自进而求应于初九,犹婚媾也,故无不利。朱熹
乘马班如,犹豫不进之象。若能下求其应,则无不利。
九五
屯其膏,小贞吉,大贞凶。 |
象曰:屯其膏,施未光也。 |
- 屯其膏 : 屯,囤积、蓄积、累积、积累、聚集;膏,脂肪、油脂,引申为 恩泽、资源,象征 资源、财富、权力等。
- 小贞吉,大贞凶 : 九五和六二阴阳正应,应的范围小。九五不仅是上卦中位,还是全卦中位、尊位、天子之位,只与六二相应,有所私,恩泽不能广布,故 大贞凶 。占问小事吉祥,占问大事凶。
- 施未光也 : 施,施恩、分配(资源与权力)、给与;光,广泛、广大、普照。对应九五的 资源仅能支撑小范围行动,无法支撑大范围行动
九五阳爻居爻位,尊位居中且正,本是吉象,但处 屯难(刚柔始交而难生),坎(险)中 之时,聚而未伸展,环境艰难,九五虽居尊位,却 德泽未广施,占问小事吉祥,占问大事凶。。
古人注解 :
王弼
九五以阳居尊,宜大亨也。然屯难之时,恩泽未施,故屯其膏。小贞则吉,大贞则凶也。程颐
九五尊位,才德足以施惠,然当屯难,膏泽未光。小贞则守正待时吉,大贞则妄图大施,必凶。朱熹
屯膏,恩泽未施也。九五居尊,中正之德,当屯之时,不可大施;小贞则吉,大贞则凶。
上六
乘马班如,泣血涟如 |
泣血涟如,何可长也 |
上六阴爻居阴位,为 屯卦 最后一爻,为穷(困)极(尽)之位,既无正应(六三阴爻,敌而不应),又乘九五之刚,上下皆无出路,形成穷极之位。坎为水、为血,故泣泪至泣血(泣血涟如)。此爻在全周易中也属比较凶的,毫无出路,血泪涟涟也无用。
泣血涟如,何可长也 ,物极必反,此种状态必然迅速结束:或破局,或崩溃,或转向新的循环。所谓 困极则变,屯极则亨 。失去机会者要主动总结经验教训,反思失败(被动)的根源,让这些失败经验成为新开端的催化剂
古人注解 :
王弼
班如,迟疑也。屯难之极,忧苦涟如,故泣血也。然屯穷则变,故曰何可长也。程颐
上六以阴柔居屯之极,穷迫忧苦,故泣血涟如。然屯极则必变,故曰何可长也。朱熹
处屯之极,穷迫之甚,忧痛之深,故有泣血之象。然屯极则变,必不可以长久。