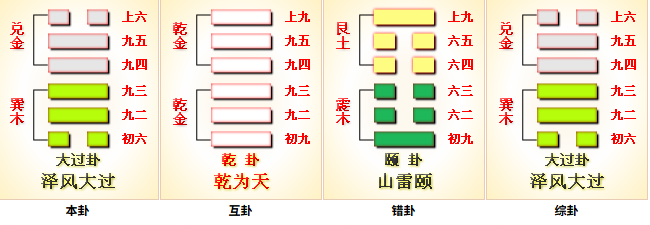
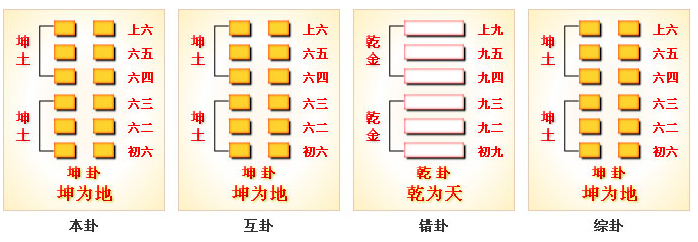
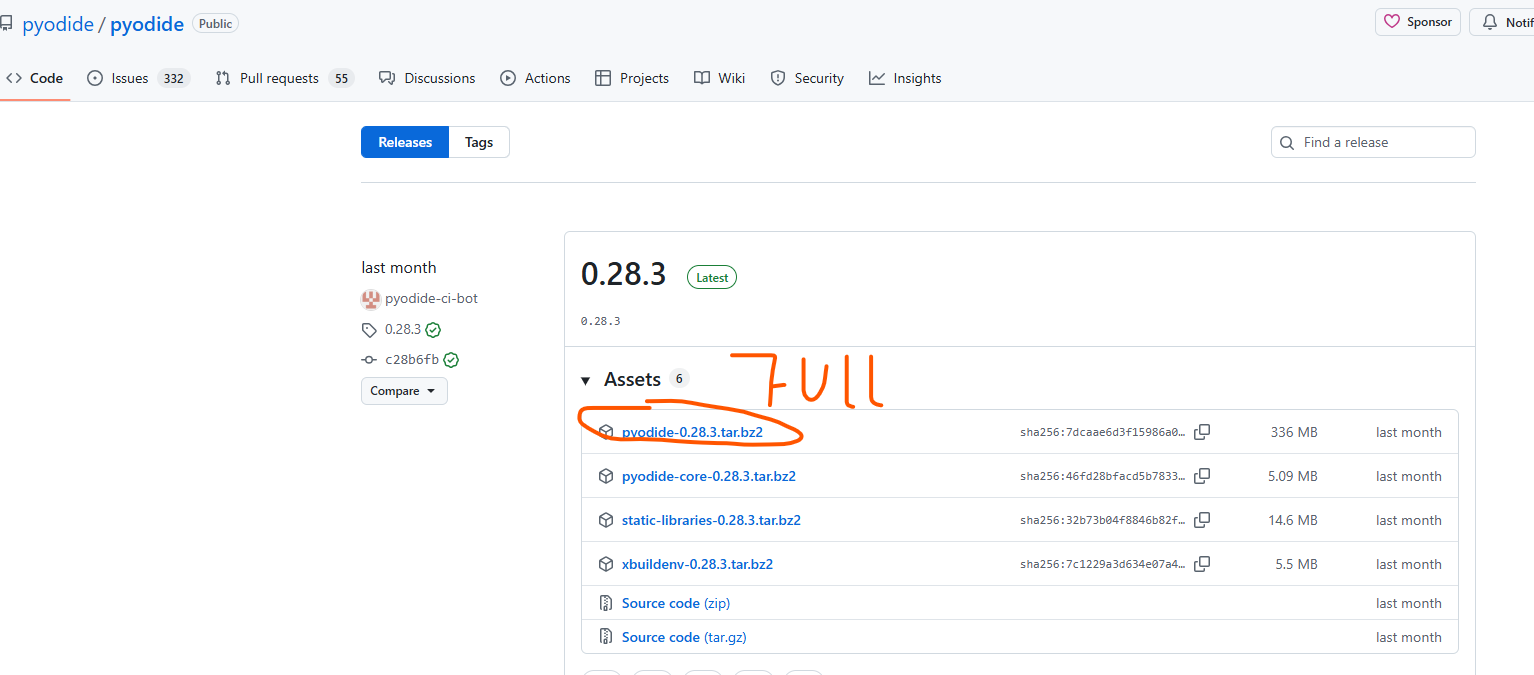
坤为地
坤 是《周易》第二卦,纯阴之卦,是与 乾(刚健主动) 纯阳相对的 柔顺承正 之卦,象征 地的包容承载、阴的柔顺和辅助
易 坤。元,亨,利牝马之贞。君子有攸往,先迷后得主。利西南得朋,东北丧朋。安贞,吉。
彖 彖曰: 至哉坤元,万物资生,乃顺承天。坤厚载物,德合无疆。含弘光大,品物咸亨。牝马地类,行地无疆,柔顺利贞。君子攸行,先迷失道,后顺得常。西南得朋,乃于类行;东北丧朋,乃终有庆。安贞之吉,应地无疆。
象
元,亨 : 和 乾卦的 元,亨 相同 ,坤 也具备 元亨 之德,但 乾 是主动(刚健)开创,坤 是主动承载顺从(承正)乾道牝马之贞 : 母马。牝马性柔而健,行地无疆,又能顺随牡马(指公马,象征 乾道)而不自为主;用此象来指示 阴之正 ,即 柔顺利贞 之德。 阴爻宜固守柔顺,则吉(贞、正)。 攸往 : 攸,虚词,本义是 所、之所,表示 地方、处所、行为的对象。往,去、行动。攸往,通常表示 有所行(动)、有所作为、追求目标 先迷后得主 : 主动为先则迷,顺道为后则得主(乾为主,坤为从)。言 阴之道 宜后不宜先 。 坤的 行动价值,在于 让正道的力量通过自身的承顺得以落地,而非主导先行 利西南得朋,东北丧朋 : 朋,朋友、同伴、同类、志同道合者。 后天八卦中,坤主西南,为阴,象征和自己同属性(类)得朋;艮主东北,为阳,象征和自己不同属性(类)得朋 。往西南,会和志同道合者(朋,顺同类)共同协作,有利;往东北,不会有同伴(丧朋),但是会得主(得君者,臣之庆;得亲者,子之庆;得夫者,妇之庆。庆者,未有不离其朋而得者也),也是非常吉利。安贞 : 安于正道(柔顺承载、辅助)、守正(柔顺之正)地势坤 : 象征 地 之厚重、无边无际、高下相承、承载包容万物
乾坤如车之两轮、鸟之双翼,缺一则无法成事 :
乾为创始,坤为成终 ,没有坤的 承载,乾的 开创 将毫无意义;没有乾的 引领,坤的 承载 将毫无方向,二者 相生相济,共同构成 生生不息的宇宙与人事规律乾主知,坤主行 乾为天,坤为地。乾坤并建,宇宙始备 有乾无坤,则躁进而难久;有坤无乾,则寡断而失机。
古人注解 :
初六 易 象
履霜 : 履,踩、踏、接触。霜,薄寒之征,象征 阴柔力量的初始形态 ,可指代 不利因素、负面趋势、潜在风险 坚冰至 : 君子见微知著,履霜而知坚冰将至,象征 对初始微小的不利趋势(征兆)要 主动关注,警觉、不轻视,如此才能防微杜渐;初始微小的不利征兆,若不阻断,必然发展为重大危机 阴始凝也 : 不利因素、消极趋势刚开始聚集。 阴始凝,是履霜、将至坚冰的因 。象征 负面力量从无到有,且开始主动聚集 驯致其道,至坚冰也 : 驯,顺从、遵循、顺而渐(循序渐进)。 坚冰至 不是 突然发生的意外,而是负面因素遵循 渐进积累的发展 规律,逐步发展的必然结果。揭示了 微小隐患→渐进积累→重大危机 的规律,如 千丈之堤,以蝼蚁之穴溃
初六为坤卦最下(初爻、下位),阴爻居阳位(不得位),一阴始生,位(下位)卑且弱,却正是阴气发动之端(初爻为 起点,对应事物发展的初始阶段,微小却关键),阴爻位不当,暗示 微而不正(阴的特质 柔缓、隐蔽、不张扬,易被忽视) 的萌芽最易被忽视 。需要警觉
初爻的 始,决定了此时 问题干预成本最低(阴始凝),若任由不利因素继续发展(驯致其道),必将造成重大危机(至坚冰),再去解决就需要付出更大代价 ,初六的预警,本质是 在成本最低的阶段,解决最根本的问题
古人注解 :
六二 易 象
直,方,大 : 直,正直、内质刚正、柔顺承道的本真无妄。方,方正、守规矩、不偏倚(有准则、有边界)、坚守原则。大,无局限、能承载、包容无界的格局(有容乃大),承坤卦 大 德不习无不利 : 习,本意为 学习、练习、修习,这里引申为刻意造作、违背本质的修饰。 不习无不利 指 无需刻意修饰、顺应坤德本真,包容承载万物,自然无往不利 地道光也 : 地道,指 坤的根本规律(包容承载、柔顺承正) ;光,彰显光大、广大而明。
六二爻,阴爻居阴位,得中得正,位在 内卦 之中,为坤之正主,是坤卦中最契合 地道本真(包容承载、柔顺承正) 的爻位,象征 柔顺力量达到 中正纯粹、自然天成 的境界 ,故其德圆满, 不习无不利 (契合地道本真,无需刻意修饰,自然彰显价值光辉)
直,方,大也是地得特性,古人认为天圆地方,地是方得,是直得,是广大得。
六爻卦(重卦、六十四卦)中每个卦都有最主要得一爻,称为 卦主(一卦之主),也称作 主爻 。每卦包含 天(上、五爻)、地(初、二爻)、人(三、四爻),称为三才 。乾卦是天,九五为天位,是乾本位,是主爻(卦主)。坤卦是地,六二是地位,是坤本位,是主爻(卦主),最能代表地得特性。
古人注解 :
王弼
直者,不枉曲;方者,不偏倚;大者,无所不包也。不习而利者,性自然也。
程颐
六二中正,以阴居阴,尽地之道,直方广大,不待勉强而然,故无不利。
朱熹
六二之德,直以方,大而无私,不待习而成,乃地道之光也。
六三 易 象
含章 : 章,文采、才美、美德、才能; 含,包容、内含、藏而不露。 拥有才华却不刻意显露,如同美玉藏于石中,不轻易示人 可贞 : 贞,守正、坚守正道、坚守原则。 坚守正道不违背原则、不放弃底线 无成有终 : 无成,不是没有成就,而是 若从(以辅助者、实行者的角色,非主导者)王事,事成而不居功(不将成就归于自身)、不自傲,必能有好结果。知光大也 : 知,智慧、学识。
六三爻处 下卦终位,上接六四的临界位置 ,已离田而尚未登天(未至四、五),阴爻居阳位,位不当,故 含而不敢先 ;然紧邻外卦,才美已具(才华待显、辅助上位)。才美已盛而位未正,宜 隐藏锋芒而守正(含章可贞),待时而出,若从(顺应、跟随而非主导)王事,要以辅助者的角色行事,不居功(无成有终)
或从王事,无成有终 的关键在于 从和无成 ,要认清自己的位置和角色,以辅助者、实行者的角色,非主导者的角色辅助君主,彰显 坤 的特性。 无成 并非 否定个人价值,而是认清辅助者的定位,不居功、不自傲,这是 六三爻 在位不当的环境下 善终的关键
含章可贞,以时发也 ,含章并非 无所作为、消极避世,而是要在合适的时机(以时发,因势而发)显露才华(或从王事)。 含章可贞 是 以时发也 的前提和准备,以时发 是 含章可贞的 目的 。 时 指位势适配的时机,如 王事 需要辅助、自身位势安全时
或从王事,知光大也 ,到了合适的时机,可以从王事,其智慧才学(章)光大的表现。
古人注解 :
王弼
章之为德,明也。含章者,不显其明也。以阴居阳,处不当位,宜含光以守正也。
程颐
六三以阴居阳,非正之地,若逞其章,则失其贞。惟含章守正,俟时而发,乃吉。
朱熹
含章,谓有文明之德而不显。以阴处阳,不当位,故宜含蓄而守正。
六四 易 象
括囊 : 括,扎紧、束缚、系紧、封闭; 囊,袋子、口袋。扎紧口袋,引申为 谨慎收敛自身的言行、才华、欲望,不轻易显露、不随意行动、不妄言、不妄动
六四爻,阴爻居阴位(得位),处于 上卦初位、临近九五君位的敏感地带 ,上接乾卦核心(九五阳爻,象征君权、刚健主导者),下承下卦辅助(六三阴爻,象征基层力量),是上(君)传下(臣)达的 权力缓冲带 与 矛盾焦点区。在高危环境中,唯有收敛言行、不妄动不张扬(慎),才能 无咎(避祸),哪怕牺牲 荣誉(无誉)
古人注解 :
王弼
括囊者,闭藏也。处阴柔之地,不可以自进,宜守闭藏,则无咎也。
程颐
以阴居阴,近尊位,若有所施,则必害也。唯括囊而不施,谨慎自守,故无咎而已。
朱熹
括囊,闭藏也。六四以阴居阴,近乎六五,若妄动则害,守闭藏则无咎,然无誉也。
六五 易 象
黄裳 : 黄,中央正色、五行居中属土,象 中和;裳,下裙、下装,古人 上衣下裳 ,衣 象征 在上的尊贵者(如君王穿的冕服),裳 象征 在下的辅助者(如臣子穿的下裳);象 谦下承上、承顺、不越权文 : 坤的柔顺文德(柔顺、包容、协调、承正),与 武(刚健、武力、开创) 相对。
六五爻 阴爻居阳位,位尊得中不得正,在坤卦,阴居君位(天子、元首),正是 以柔居尊 之典型,既中(居中守正,不偏不倚)且下(谦下承上,不居高位),五虽居 尊位,却仍是 坤卦的柔顺角色(辅助者),而非 乾卦的刚健主导者(决策者),承顺正道,故大吉。坤之六五与乾之九五同为 君位 ,而一刚一柔
柔顺力量(阴)处于 尊位而不骄、承正而不越 的理想状态,以居中守下的文德,承顺刚健正道,最终实现 元吉
文德在中 ,能以 坤之文德(柔顺、包容、协调、承正)居中守正,元吉。
古人注解 :
王弼
黄,中色也。裳,下服也。处尊位而能中正谦下,故元吉也。
程颐
居尊位而能下服,以中正之德自处,柔顺不失其正,故大吉。
朱熹
黄,中之色;裳,下之服。居尊位而能中正谦下,柔顺以治,元吉。
上六 易 象
龙战于野 : 龙,指 乾之龙(刚健力量) 与 坤之龙(过度发展的阴柔力量) 的对立,象征 阴阳两气 相互争斗。野 是 不受约束的开阔之地,象征 冲突脱离 有序框架(如朝堂、规矩),进入 无规则的混乱状态其血玄黄 : 玄,天色;黄,地色。天地(阴阳、乾坤)交战,其血玄黄,象征两败俱伤,同归于尽。其道穷也 : 阴柔之道(坤之道,柔顺承正(乾的刚健正道))至此而极尽,要么毁灭要么转化(为阳),象征物极必反,阴极阳生。
上六是坤卦最上(最后)一爻,阴爻居阴位,已到极处。象征 柔顺力量(坤)过度积累,突破 承顺正道 的边界,与刚健力量(乾)正面冲突 的凶险状态。任何力量过度发展而失度,终将突破平衡(中),引发毁灭性冲突。
坤卦六爻皆阴,到了上六爻,阴气至极(上无可上,阴盛无制),已失坤之道(承顺正道),阴盛而与阳斗。与 乾卦 上九 亢龙有悔 一刚一柔,都说明 过犹不及,盛极必衰 的道理。
古人注解 :