网宿云 cdn 预热脚本
将源站的内容主动预取到 CDN 节点,用户首次访问可直接命中缓存,即提升首次访问速度,又能有效缓解源站压力。
- 数据格式:请求和响应都支持 json/xml,xml 的参数与 json 的参数基本一致,json 的参数是驼峰分隔,xml 的参数是“-”分隔,详见示例。
- 限制说明:每个账号的预取并发是 10,调高并发会增加回源的压力,请联系技术支持人员评估。
将源站的内容主动预取到 CDN 节点,用户首次访问可直接命中缓存,即提升首次访问速度,又能有效缓解源站压力。
Acunetix Web Vulnerability Scanner(简称AWVS)是一款知名的网络漏洞扫描工具,它通过网络爬虫测试你的网站安全,检测流行安全漏洞。
HCL AppScan(原名IBM Security AppScan)是原IBM的Rational软件部门的一组网络安全测试和监控工具,2019年被HCL技术公司收购。AppScan旨在在开发过程中对Web应用程序的安全漏洞进行测试。
Helm 定位为 Kubernetes 包管理器 或者 Kubernetes App Store ,就如 RHEL 中的 yum/dnf 。主要组件如下:
helm : 纯客户端工具,负责模板渲染、插件执行和 OCI 交互。kstatus 标准,替代了以前简单的 wait 逻辑。它能更精准地判断资源(如 Deployment, StatefulSet )是否真正“就绪”。slog ,方便集成到现代化的可观测性平台。核心概念 :
https://artifacthub.io/packages/search?kind=0Helm 4 支持将复杂的配置拆分到多个 YAML 文档中,或者在一次命令中传入多个文件
helm install my-release ./my-chart -f values-base.yaml -f values-override.yaml |
Helm 4 能够直接运行 Helm 3 的 Chart,无需修改代码。
下载 需要的版本
wget https://get.helm.sh/helm-v3.10.0-linux-amd64.tar.gz |
解压
tar -xf helm-v3.10.0-linux-amd64.tar.gz |
在解压目中找到 helm 程序,移动到需要的目录中
cp linux-amd64/helm /usr/local/bin/ |
验证
$ helm version |
首先要添加仓库,告诉 Helm 去哪里下载软件包(Chart)。最常用的是 Bitnami 仓库 或者 Artifact Hub
helm repo add bitnami https://charts.bitnami.com/bitnami |
搜索/查看 Repo 中可用的 Charts
helm search repo hashicorp/vault |
安装 Chart,安装时可以为 Release 起个名字(如 vault),也可以不指定名字,让 Helm 自动生成 helm install bitnami/mysql --generate-name
要在安装 Chart 之前自定义配置,可以通过 YAML 配置自定义选项。 要想知道有哪些配置可用,可以使用命令 helm show values 查看
helm install vault hashicorp/vault --version 0.25.0 |
查看 Chart 支持的自定义配置选项
# 先查看已安装的 Repo |
查看已经安装的 Release 使用了哪些自定义参数,可以使用命令 helm get values <release-name>
helm ls -A |
helm list -A |
helm ls -A |
helm upgrade my-web bitnami/nginx -f my-values.yaml |
回滚使用命令 helm rollback [RELEASE] [REVISION] ,可以通过命令 helm history [RELEASE]
每次 install, upgrade, rollback 都会更新 REVISOION
helm list -A |
要在更新(upgrade)或者回滚(rollback)后强制重建 Pod,可以使用选项 --recreate-pods
helm repo ls |
查看已安装的 Repo 中可用的 Charts
helm search repo hashicorp/vault -l |
helm search hub 可以搜索 Artifact Hub 中公开可用的 Charts
helm search hub wordpress |
不指定名称搜索 helm search hub 将会列出 Artifact Hub 上所有可用的 Charts 链接(不是具体的 Helm Reop),要展示 Helm Repo 可以使用选项 helm search hub --list-repo-url
helm list -A |
使用命令 helm show chart 或则 helm show all 查看 Chart 详细信息,里面包含了关于 Chart 配置的详细信息和结构。
helm show chart prometheus-community/prometheus |
当你想要自己写 Chart 时,你会看到这样的文件夹结构(使用 helm create my-chart 生成):
my-chart/ |
在进入具体的网络配置前,必须理解 AWS 的地理隔离:
区域 (Region) :地理上的独立区域(如新加坡、弗吉尼亚)。区域之间完全隔离。
可用区 (Availability Zone, AZ) :一个区域内由多个物理机房组成。AZ 之间通过高速、低延迟光纤连接。高可用架构必须跨 AZ 部署。跨 AZ 之间的流量需要付费。
VPC 是你在 AWS 云中的逻辑隔离网络。你可以完全控制其 IP 地址范围、子网、路由表和网络网关。
核心组件:
CIDR 范围 :你为 VPC 定义的私有 IP 地址块(如 10.0.0.0/16 )。
子网 (Subnets) :将 VPC 划分为更小的网段。子网必须位于特定的可用区内。
公有子网 (Public Subnet) :路由指向互联网网关 (IGW),实例可以有公网 IP。
私有子网 (Private Subnet) :没有指向 IGW 的直接路由,通常通过 NAT 网关 访问外网 。
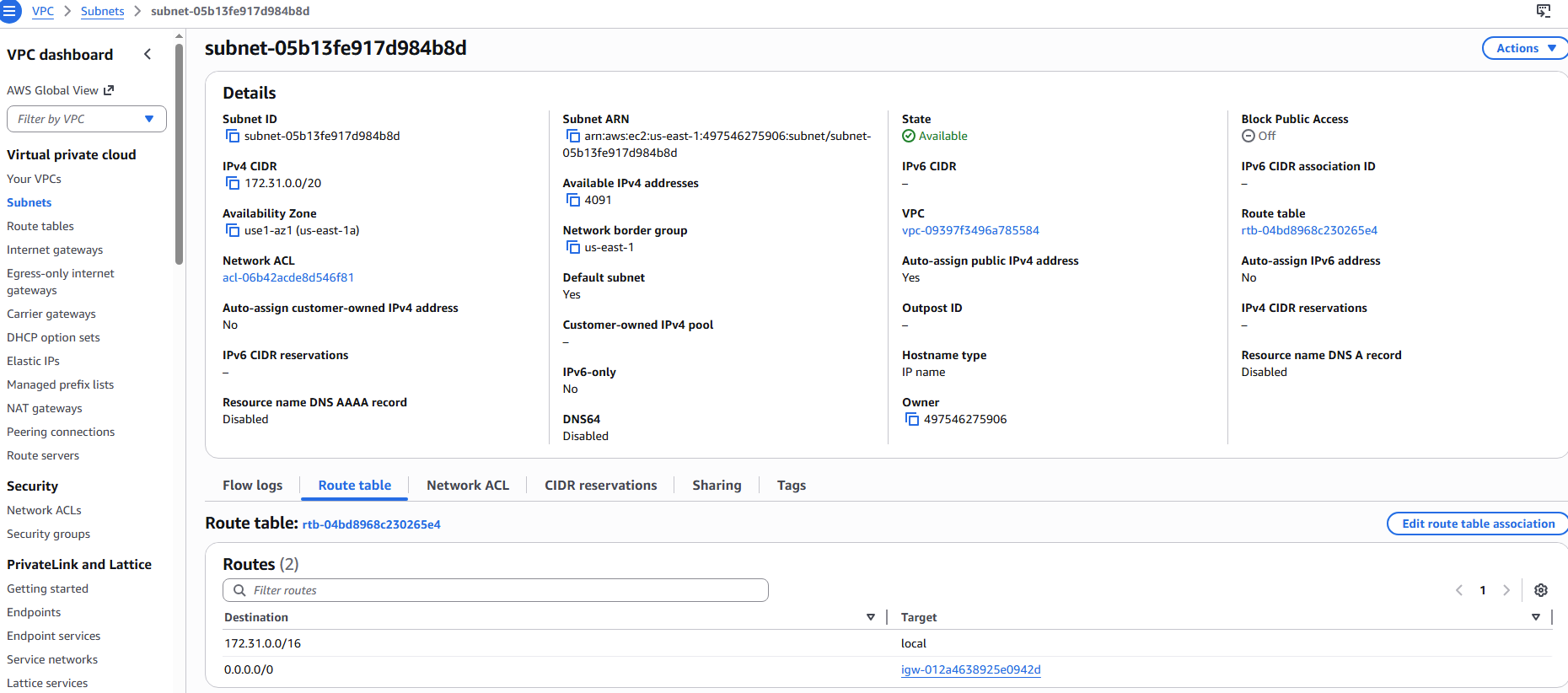
公有子网 和 私有子网 在配置上几乎一摸一样,唯一区别在于: 该子网关联的路由表(Route Table)中默认路由(0.0.0.0/0)是如何配置的。
- 公有子网 (Public Subnet) 其路由表中默认路由(0.0.0.0/0)指向 互联网网关 (Internet Gateway, ID 格式通常为 igw-xxxxxx) 。由于它直接连接到互联网大门,且子网内的实例拥有公网 IP,因此外部用户可以主动访问它,它也可以直接访问外部。
- 私有子网 (Private Subnet) 其路由表中默认路由(0.0.0.0/0)指向 NAT 网关 (NAT Gateway, ID 格式通常为 nat-xxxxxx),或者干脆没有任何去往外网的路由 。它没有直通互联网的大门。它通过 NAT 网关(单向出口)实现“能出不能进”的效果。
下图所示子网为 公有子网
流量如何进出
VPC 与外界互联网通信可以使用以下方式:
| 组件 | 作用 | 流量方向 | 用法说明| |
|---|---|---|---|
| Internet Gateway (IGW,互联网网关) | 允许 VPC 连接互联网。 | 双向 (In/Out) | 实例必须分配公网 IP 或弹性 IP (EIP) |
| NAT Gateway (NAT 网关) | 允许私有实例上外网,但防止外部主动连接。 | 单向 (Outbound only) | 仅需私有 IP |
| VPC Peering (对等连接) | 连接两个不同的 VPC,使其像在一个网络内通信。 | 跨 VPC | |
| Transit Gateway | 充当“中央枢纽”,连接数千个 VPC 和本地网络。 | 复杂网络拓扑 | |
| Virtual Private Gateway | 用于建立 VPN 连接。 | 混合云 |
通过 NAT Gateway 可以实现子网中的实例的对外互联网出口 IP 都是 NAT Gateway 绑定的 EIP,子网中的实例对互联网不可见。NAT Gateway 典型使用场景:
以下为创建 NAT Gateway 并关联子网的相关步骤:
VPC |
关键点:
确认 Public Subnet 存在
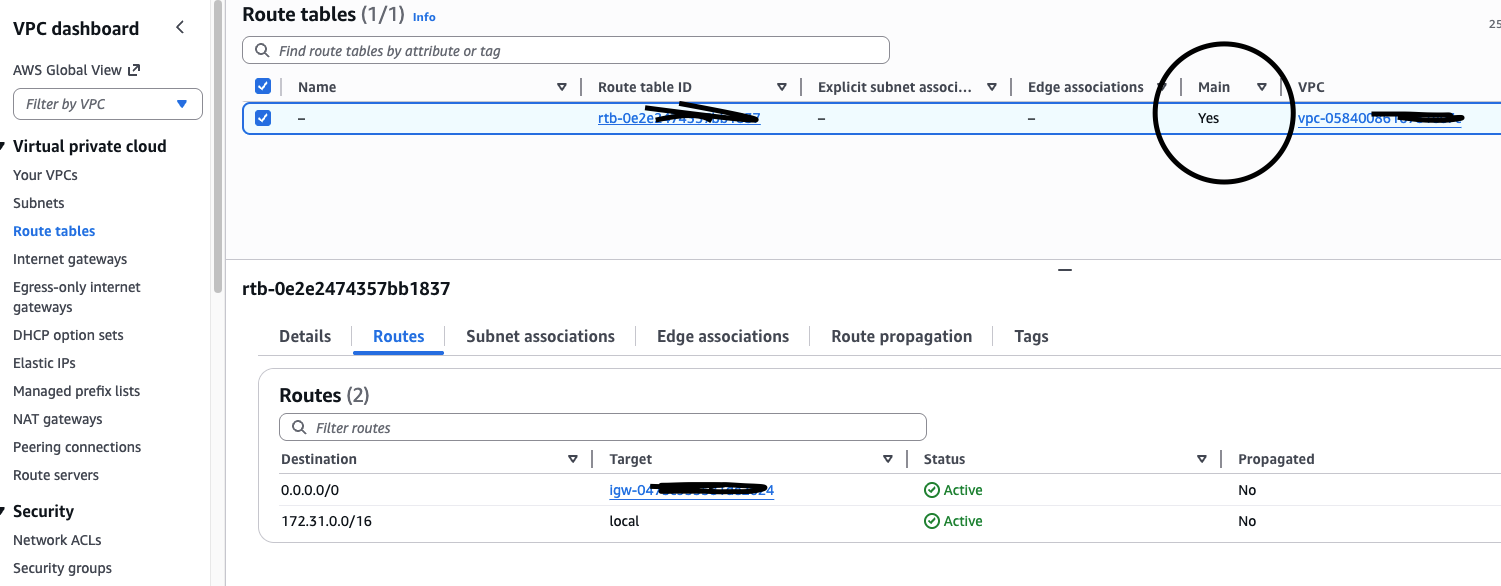
VPC 默认的 Main Route Table 已经满足这个条件,其默认网关为 Internet Gateway
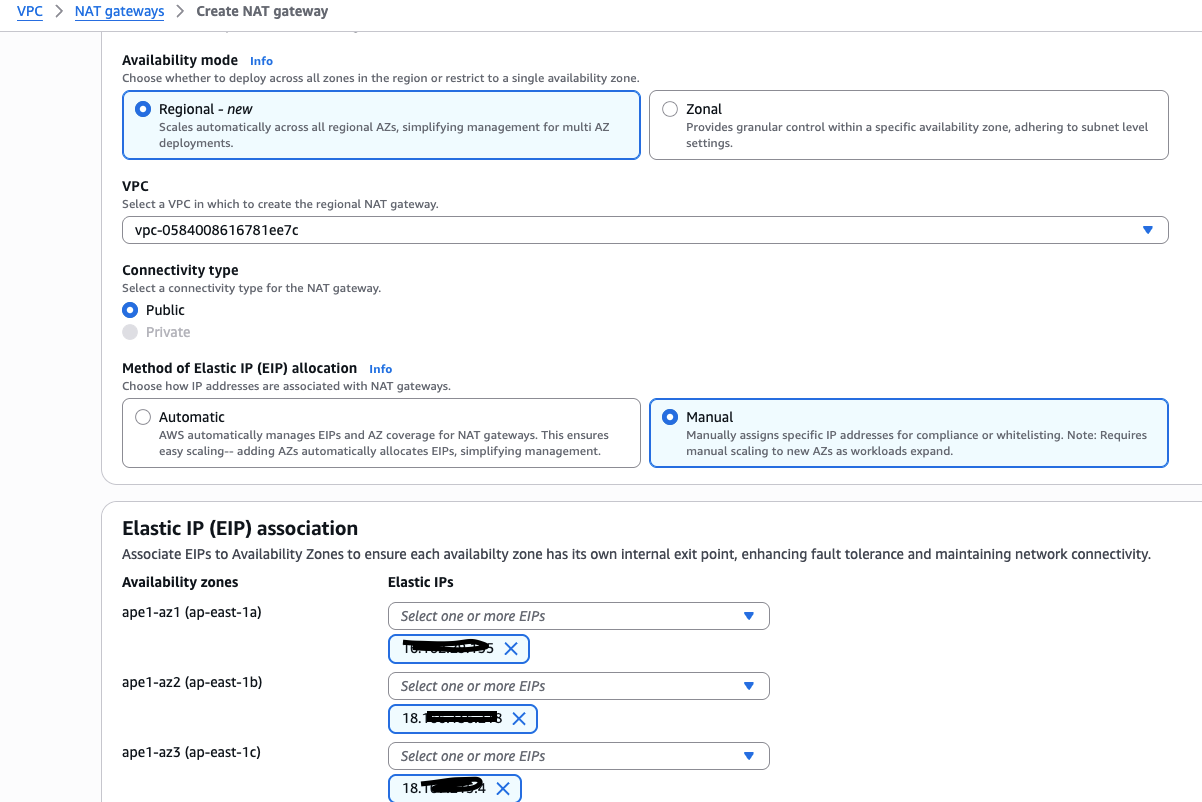
创建 NAT Gateway
在 NAT gateways 标签页面中,点击 Create NAT gateway , Connectivity type 选择 Public , Elastic IP (EIP) association 选择 手动分配 EIP(Manual)
创建完成后,状态应为 Available 。在路由表(Route Tables)中,这时会多一个路由表,其 Edge associations(边缘关联) 关联到了刚刚创建的 NAT Gateway
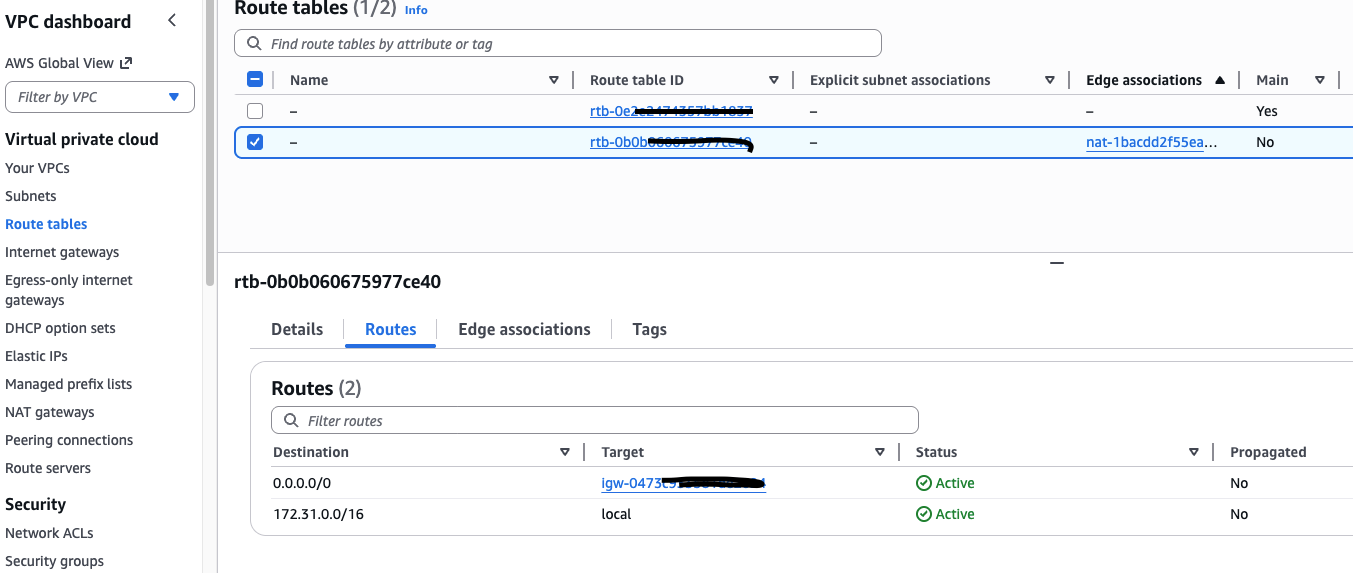
创建一个新的子网(私有、Private Subnet)
在 VPC → Subnets → Create subnet 标签页面中创建新的子网, 不要勾选 Auto-assign public IPv4 ,如此处于此子网中的实例,不会为其分配公网地址
创建 Private Route Table
在 VPC → Route tables → Create route table 标签页面中创建新的路由表,本示例名为 private-rt
配置路由规则
选择刚刚创建的新路由表 private-rt,在 Routes 中 编辑路由(Edit Routes) ,添加一条路由规则:
| Destination | Target | |

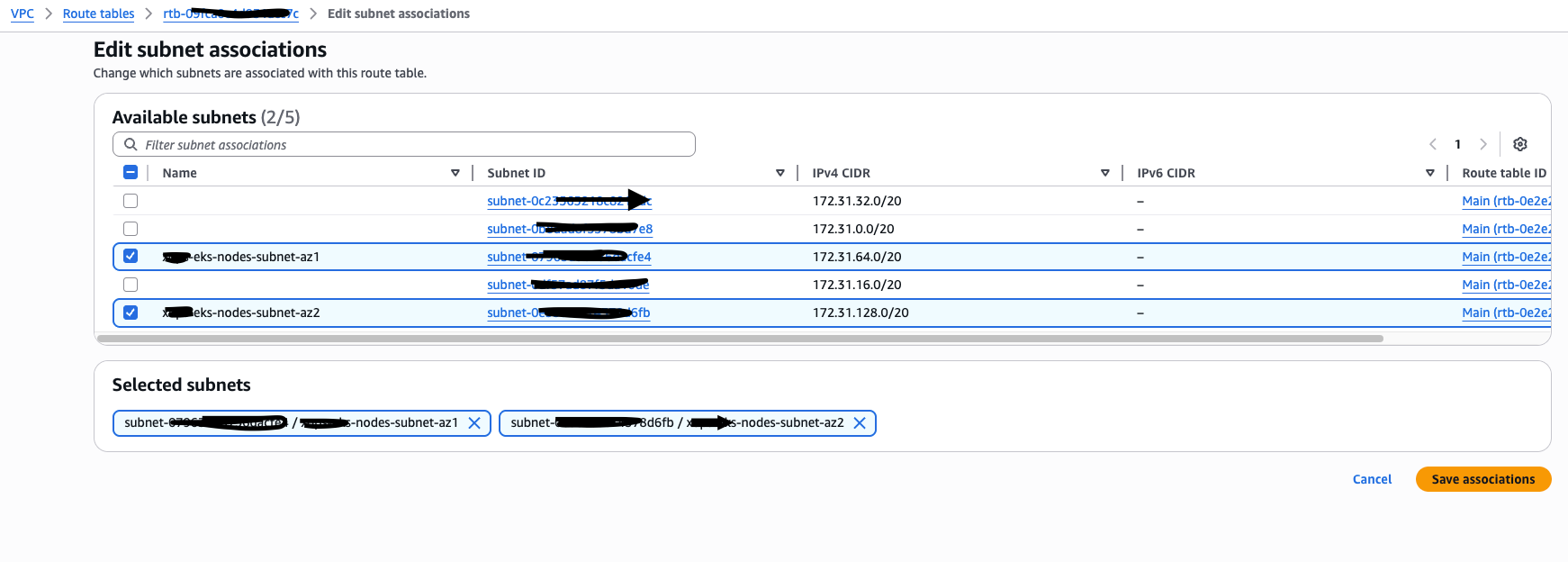
关联 Private Subnet
选择刚刚创建的新路由表 private-rt,在 Subnet associations(子网关联) 中 Edit subnet associations(编辑子网关联) ,选择目标子网进行关联
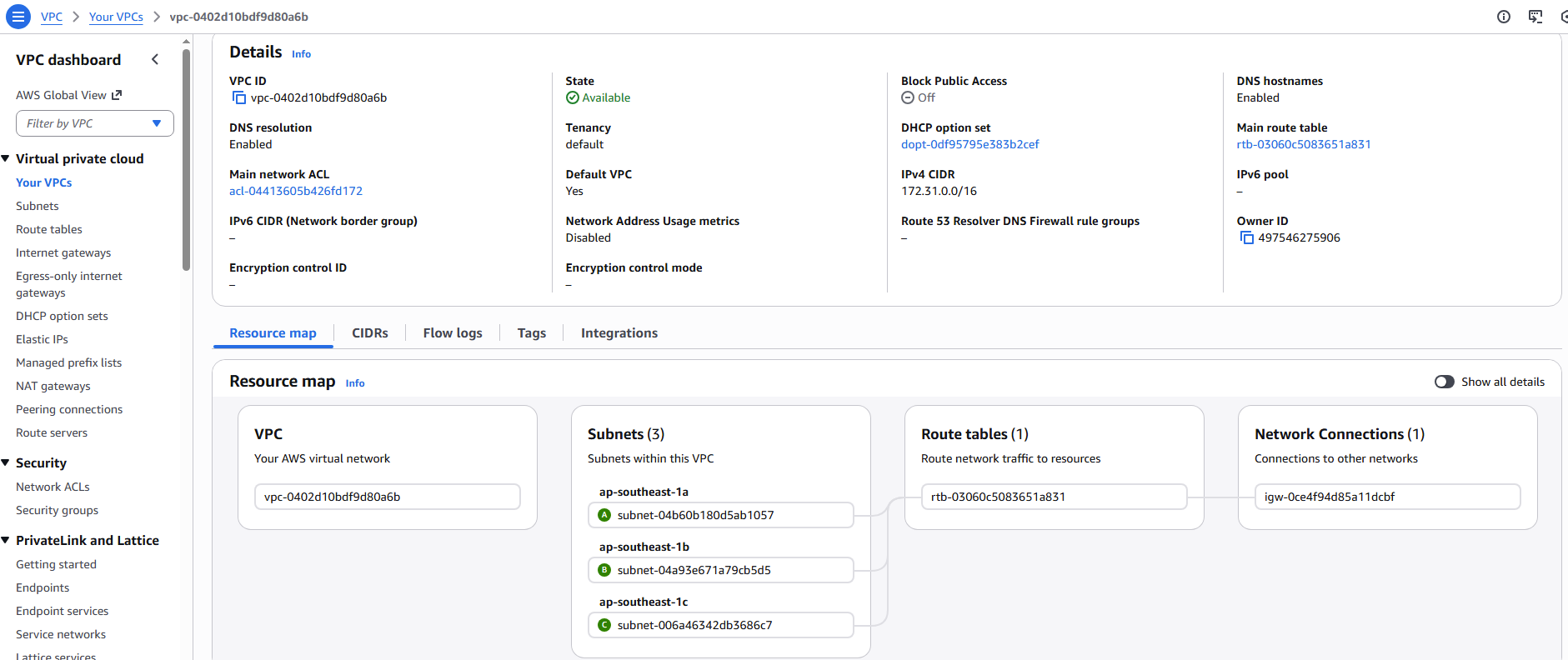
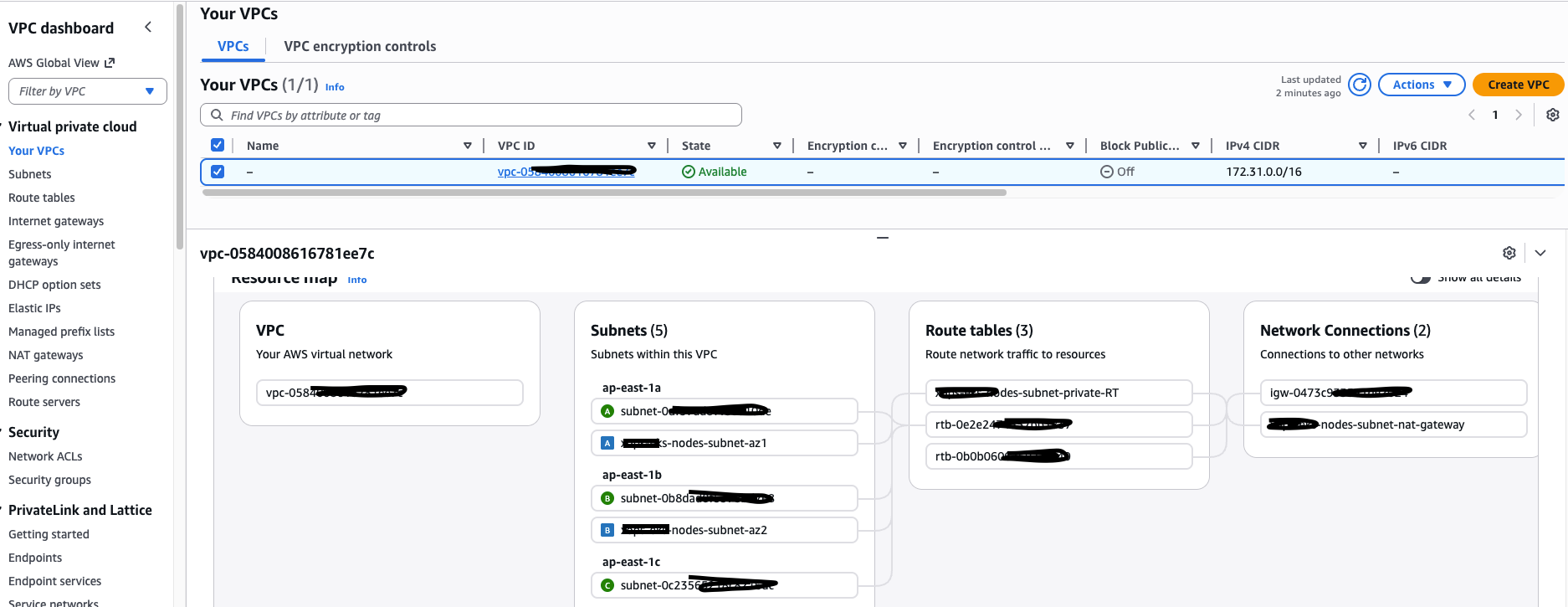
最终的 VPC 整体路由可以在 VPC 的 Resource map 中进行检查
Kubernetes 原生提供 RBAC(Role-Based Access Control) 来控制集群中的 用户和服务账户(ServiceAccount) 对资源的访问权限。
| 对象 | 描述 |
|---|---|
| Role | 命名空间级别(Namespace)权限,指定某个命名空间内允许的操作和资源类型。 |
| ClusterRole | 集群级别权限,可以跨命名空间使用。 |
| RoleBinding | 将 Role 绑定到一个用户或 ServiceAccount。 |
| ClusterRoleBinding | 将 ClusterRole 绑定到一个用户或 ServiceAccount。 |
核心字段
apiGroups :资源所属 API 组,例如 "" 代表 core API 。
resources :允许访问的资源类型,如 pods、deployments。
verbs :允许的操作,如 get, list, create, delete 。
RBAC 示例:
apiVersion: rbac.authorization.k8s.io/v1 |
RBAC 控制的是 Kubernetes 资源访问权限 。
RBAC 对象绑定的是 Kubernetes 用户或 ServiceAccount,而不是 AWS IAM 用户 。
| 概念 | 全称 | 解决的问题 | 作用范围 |
|---|---|---|---|
| RBAC | Role-Based Access Control | 决定 “用户/进程” 在 K8s 集群内能做什么(如:查看 Pod) | K8s 集群内部 |
| Role | Kubernetes Role | RBAC 的一部分,定义一组具体的集群内操作权限 | 命名空间 (Namespace) |
| IRSA | IAM Roles for Service Accounts | 决定 “Pod 里的应用” 对 AWS 外部资源(如 S3/RDS)的访问权限 | AWS 云环境 |
AWS IAM Role 是 AWS 层面的权限机制,用于授权 AWS 资源访问,例如 S3、DynamoDB、Secrets Manager 等。
AWS IAM Role 的特点:
可以被 IAM 用户、服务或 EC2/EKS Pod 假设(Assume)。
权限通过 IAM Policy 定义。
AWS IAM Role 在 EKS 中的应用:
管理集群本身访问 AWS 资源,例如节点组(NodeGroup)访问 S3。
可以通过 IAM 用户/Role 管理集群级别的操作权限,例如 eks:DescribeCluster 。
💡 核心点:IAM Role 本身无法直接控制 Kubernetes 资源,它管理的是 AWS 资源访问。
IRSA(IAM Roles for Service Accounts) 是 AWS EKS 引入的将 Kubernetes ServiceAccount 与 AWS IAM Role 绑定,实现 Pod 级别的 AWS 权限控制的机制。其大致原理如下:
eks.amazonaws.com/role-arn。实践建议:
不要在 Pod 内放 AWS AccessKey,使用 IRSA。
最小权限原则:
RBAC:只给 Pod 或用户真正需要的 Kubernetes 权限。
IAM Role / IRSA:只给访问 AWS 资源的最小权限。
多集群管理:可以通过 ClusterRole + RoleBinding 管理跨命名空间权限。
审计:
使用 CloudTrail 监控 IRSA 调用。
Kubernetes API Server 日志审计 RBAC 权限。
EKS 集群特性总结
如果集群需要固定的出口 IP,最推荐,最标准的做法是 使用 NAT 网关 ,将 EKS 节点部署在私有子网中,所有访问外部网络的流量都会经过 NAT 网关
本示例中使用 EKS 自治模式(EKS Auto Mode)
EKS 自治模式 接管了原本需要手动管理的节点、存储和网络配置,因此它需要一组非常具体且强大的权限
EKS 自治模式 有额外的费用,大概比 EC2 价格高 12%
EKS 自治模式 在集群创建完成后可修改(编辑)为非自治模式
EKS 自治模式 中的 Worker Nodes 配置 不能在控制台修改参数、不能自定义 ,具体的配置可以通过 API 接口查看
nodepool资源
Name: general-purpose
Namespace:
Labels: app.kubernetes.io/managed-by=eks
Annotations: karpenter.sh/nodepool-hash: 4012513481623584108
karpenter.sh/nodepool-hash-version: v3
API Version: karpenter.sh/v1
Kind: NodePool
Metadata:
Creation Timestamp: 2026-02-06T09:38:18Z
Generation: 1
Resource Version: 784637
UID: e85261b9-3a4b-41b0-ac5...
Spec:
Disruption:
Budgets:
Nodes: 10% # 这是一个安全阀。在同一时间内,由于缩容或更新导致的节点离线比例不能超过 10%。这保证了你的集群不会因为自动优化而导致业务大面积中断。
Consolidate After: 30s # 节点达到上述状态 30 秒后,EKS 就会考虑将其关闭,并把上面的 Pod 迁移到更划算的节点上。
Consolidation Policy: WhenEmptyOrUnderutilized # 当节点变为空闲(没有 Pod)或者利用率较低(比如一个大节点只跑了一个小 Pod)时,EKS 会自动触发节点合并。
limits: # 资源限制
cpu: "1000"
memory: 1000Gi
Template:
Metadata:
Spec:
Expire After: 336h # 节点的最大“寿命”是 14 天(336 小时),强制节点定期更换,以确保所有节点都运行在最新的安全补丁和 Bottlerocket 镜像上,防止出现长期未重启的“僵尸节点”。
Node Class Ref: # nodeclass 信息,可通过 kubectl get nodeclass 查看
Group: eks.amazonaws.com
Kind: NodeClass
Name: default
Requirements: # 节点选择标准 (Requirements)
Key: karpenter.sh/capacity-type # 实例类型,on-demand 为 按需实例
Operator: In
Values:
on-demand
Key: eks.amazonaws.com/instance-category # 限定了实例系列 c: 计算优化型(适合高并发); m: 通用型(平衡 CPU 和内存); r: 内存优化型(适合数据库或缓存)。
Operator: In
Values:
c
m
r
Key: eks.amazonaws.com/instance-generation # 只使用 4 代以后的机型(如 c5, m6i 等)。这确保了节点拥有较新的硬件特性和性能。
Operator: Gt
Values:
4
Key: kubernetes.io/arch # CPU 架构。如果你想尝试性价比更高的 ARM 架构(Graviton),需要在这里添加 arm64
Operator: In
Values:
amd64
Key: kubernetes.io/os # 节点操作系统(OS)类型
Operator: In
Values:
linux
Termination Grace Period: 24h0m0sEKS 自治模式限制资源上限 编辑 NodePool,修改
spec.limits.cpu和spec.limits.memory。这决定了该池子最多能“烧”掉多少 EC2 资源。强制回收节点 : 如果你想让 EKS 重新平衡节点(例如你更改了实例限制),可以手动删除节点,Auto Mode 会自动根据 Pod 需求拉起符合新规的新节点
同时要关注
nodeclass资源,其中定义了 子网(Subnet)和安全组(Security Group)等信息
NAME ROLE READY AGE
default eksNodeRole True 44h
kubectl describe nodeclass default
Name: default
Namespace:
Labels: app.kubernetes.io/managed-by=eks
Annotations: eks.amazonaws.com/nodeclass-hash: 13740036326424352917
eks.amazonaws.com/nodeclass-hash-version: v2
API Version: eks.amazonaws.com/v1
Kind: NodeClass
Metadata:
Creation Timestamp: 2026-02-06T09:38:18Z
Finalizers:
eks.amazonaws.com/termination
Generation: 2
Resource Version: 827607
UID: 5065b0f3-3795-4347-893a-338ae6fa882d
Spec:
Ephemeral Storage:
Iops: 3000
Size: 80Gi
Throughput: 125
Network Policy: DefaultAllow
Network Policy Event Logs: Disabled
Role: eksNodeRole
Security Group Selector Terms:
Id: sg-058bd1ef...
Snat Policy: Random
Subnet Selector Terms:
Id: subnet-07963d9b...
Id: subnet-0e359aac...
Id: subnet-0e76c601...
创建项目所需新目录,用于存储持久化数据
mkdir -p /opt/devops/{confluence,jira,postgresql} |
下载 atlassian-agent.jar 文件,将其分别放置在 ./confluence/atlassian-agent.jar 和 ./jira/atlassian-agent.jar ,用于之后为 Confluence 和 Jira 生成 License
docker-compose.yaml 文件内容如下
services: |
启动容器
docker compose up -d |
postgres 数据库启动正常后,执行以下命令为 Jira 创建数据库,Confluece 数据库在容器启动是会自动创建。
docker compose exec -it postgres-db psql -U postgres -c "CREATE DATABASE jira WITH ENCODING='UTF8' LC_COLLATE='en_US.utf8' LC_CTYPE='en_US.utf8' CONNECTION LIMIT=-1;" |
浏览器访问 http://<IP>:8090 在 Confluence 初始化页面拿到 Server ID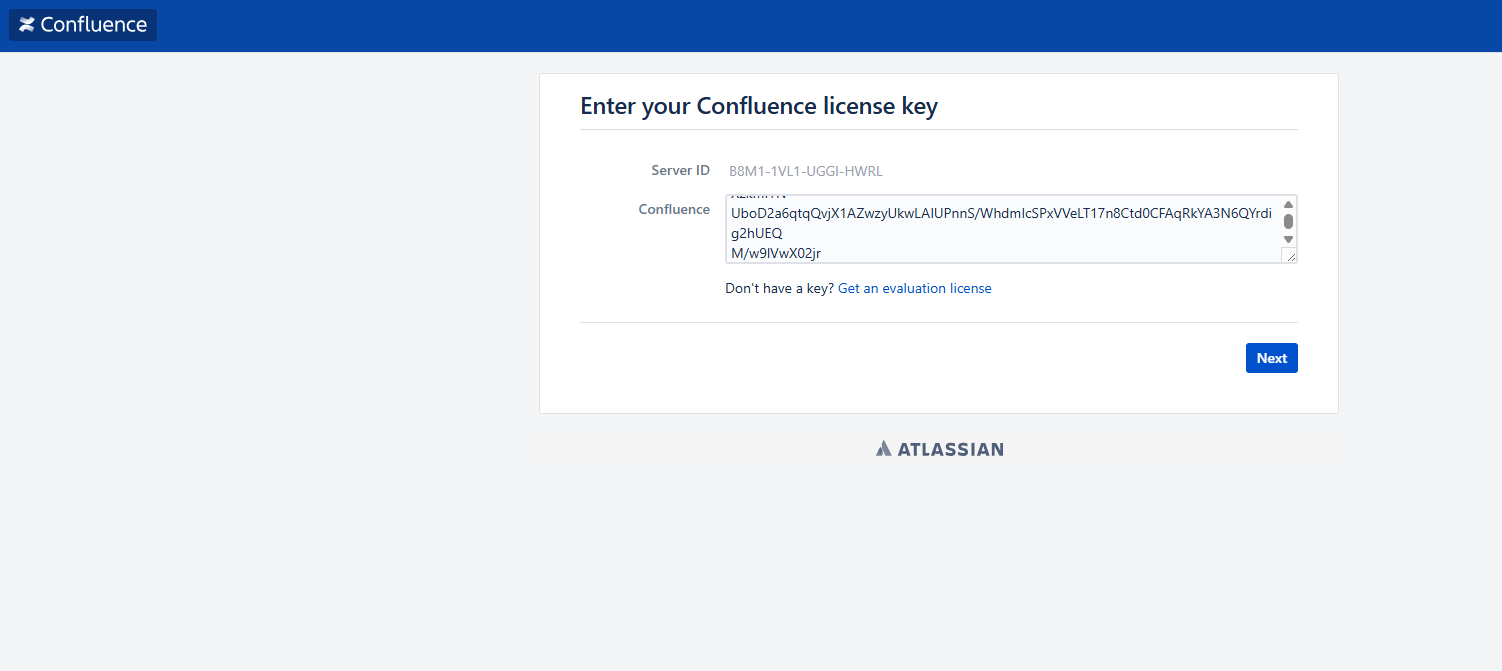
登录 Confluence 容器,执行以下命令获取破解得 License
docker compose exec -it confluence bash |
命令参数说明:
-d调试模式 必选,用于输出生成的许可证信息。
-m电子邮箱 随便填 ,如[email protected]。
-n用户名 随便填 ,如 Organization_Admin。
-p产品标识 不可乱填 。Confluence 是conf,Jira 是jira,Bitbucket 是bitbucket。
-o组织/URL 建议填你的访问地址,如https://wiki.mysite.com。
-sServer ID 核心参数。必须填 Web 页面上显示的那个 16 位代码 。
License 验证成功后,填写数据库连接信息并测试连接成功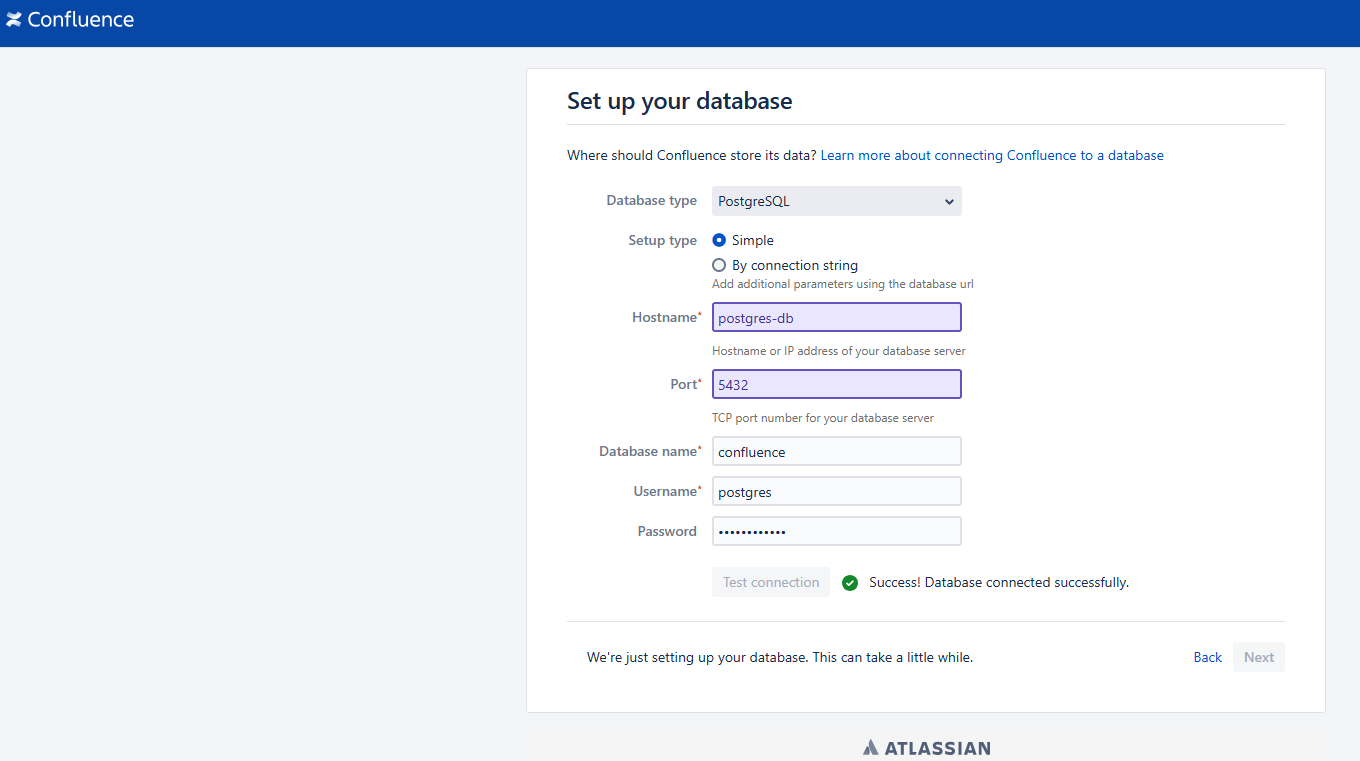
浏览器访问 http://<IP>:8080 打开 Jira 初始化页面,在 Jira setup 中选择 I'll set it up myself 。因为后面要指定数据库信息,因此要选择自定义。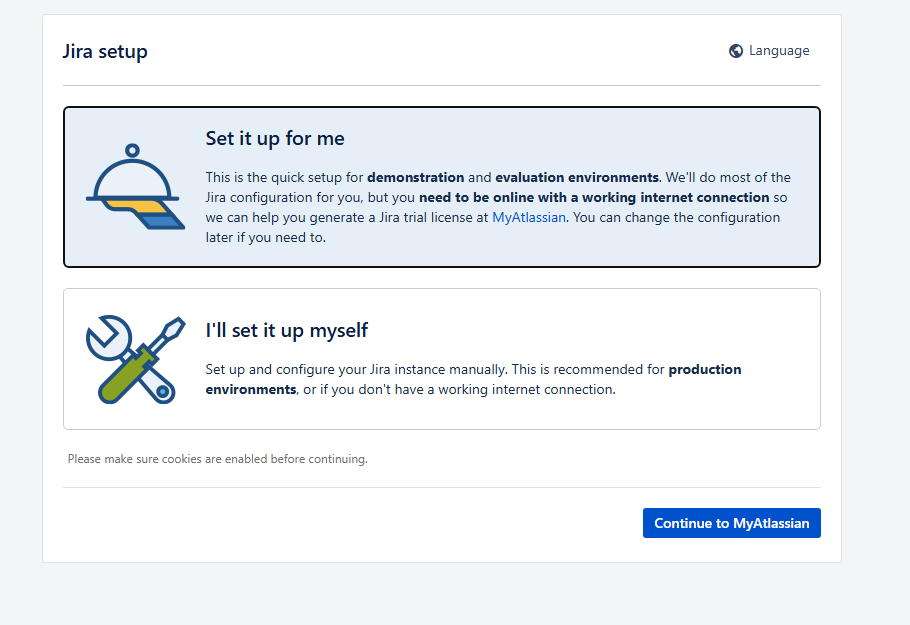
根据提示填入数据库连接信息,测试无误后,到 Specify your license key 页面,复制 Server ID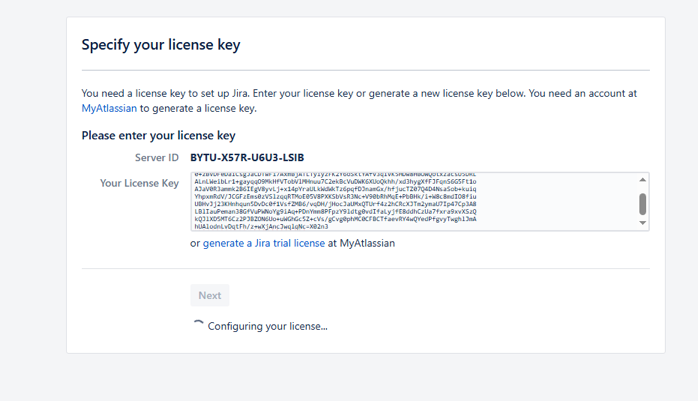
登入 jira 容器,使用以下命令为 Jira 生成 License
root@69487899ebea:/var/atlassian/application-data/jira# java -jar /var/atlassian/application-data/jira/atlassian-agent.jar -d -p jira -m [email protected] -n [email protected] -o your-org -s BYTU-X57R-U6U3-LSIB |
注意其中的参数
-p jira
根据提示完成其他配置即可开始使用 Jira。
部署好相同版本的 Confluence 和 PostgreSQL 环境,
在开始之前,请确保:
confluence )。迁移 PostgreSQL 数据库
由于版本一致,直接使用 pg_dump 是最稳妥的方案。
docker exec -t <旧数据库容器名> pg_dump -U <用户名> <数据库名> > confluence_db.sql |
先删除新环境中的数据库 confluence,再新建
psql -h <HOST> -U postgres -d postgres |
然后导入备份数据,将 confluence_db.sql 拷贝到新服务器,然后执行:
cat confluence_db.sql | docker exec -i <新数据库容器名> psql -U <用户名> -d <数据库名> |
迁移 Confluence Home 目录
Confluence 的用户附件、索引、插件配置等都存储在 Home 目录下。进入旧服务器的映射目录,执行
tar -zcvf confluence_home_backup.tar.gz /path/to/old/confluence_home |
将备份文件传输到新 Confluence 环境 Home 目录并解压
修改配置文件(如果数据库连接变了)
如果新环境的数据库 IP、端口或密码与旧环境不同,你需要修改新环境 Home 目录下的配置文件:
文件路径: <confluence-home>/confluence.cfg.xml
迁移完成后,重启 Confluence,即可加载到旧环境中的数据。
迁移完成后,Confluence 打开正常,数据已经恢复,但是编辑文档保存时报错: Something went wrong after loading the editor. Copy your unsaved changes and refresh the page to keep editing.
这个错误通常意味着 Confluence 协作编辑(Collaborative Editing) 服务出现了通讯故障。在 Confluence 9.0.2 中,这通常与 Synchrony(负责实时协作的组件)的配置或网络环境有关。
可以 刷新 Synchrony 状态 解决
以管理员身份登录 Confluence。
前往 管理 (Confluence administration) > 协作编辑 (Collaborative editing) 。
点击 Change mode ,将其切换为 Disabled 。
等待几秒钟后,重新切换回 Enabled 。
这会重启 Synchrony 进程并清理过时的锁定状态。
本示例以 PostgreSQL 为例
rds-ops-sg 的安全组。5432 端口(不要暴露给 0.0.0.0/0 )。Production ,测试选 Dev/Testkubectl get nodes -o wide |
kubectl delete service -n <namespace> <name> |
kubeadm init --pod-network-cidr=10.244.0.0/16 --cri-socket=unix:///var/run/cri-dockerd.sock |
| 选项 | 说明 | 示例 |
|---|---|---|
--pod-network-cidr |
指定 pod 的 cidr,安装 CNI 插件时,配置的 CIDR 要和此处一致 | |
--service-cidr |
service 使用的 CIDR |
|
--cri-socket |
配置集群使用的 CRI,不指定时系统会扫描主机,如果有多个可用 CRI,会出现提示 | |
--apiserver-advertise-address |
手动配置 api-server 的 Advertise IP 地址。不配置的情况下,系统默认选择主机上的默认路由对应网卡上面的 IP |
|
--control-plane-endpoint |
配置 api-server 的共享地址,可以是域名或者负载均衡器的 IP单节点的 Master 后期需要扩展为多节点(高可用)时,需要有此配置,否则不支持( kubeadm)扩展 |
kubeadm join 172.31.10.19:6443 --token 8ca35s.butdpihinkdczvqb --discovery-token-ca-cert-hash sha256:b2793f9a6bea44a64640f99042f11c4ff6 \ |
其中的 token 可以在 master 上使用以下命令查看
kubeadm token list |
默认情况下,令牌会在 24 小时后过期。如果要在当前令牌过期后将节点加入集群, 则可以通过在控制平面节点上运行以下命令来创建新令牌:
kubeadm token create |
如果你没有 --discovery-token-ca-cert-hash 的值,则可以通过在控制平面节点上执行以下命令链来获取它[1]:
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | \ |
官方镜像仓库 中搜索 jenkinsci/blueocean,下载最新镜像
docker pull jenkinsci/blueocean |
创建数据目录
mkdir /data/JenkinsData_blueocean |
启动 jenkins 容器
docker run -d -p 8080:8080 --name jenkins \ |
-v /var/run/docker.sock:/var/run/docker.sock - 在需要使用 Jenkins 构建 Docker 镜像时,Jenkins 容器中的 docker 客户端需要连接到宿主机的 Docker server-v /data/JenkinsData_blueocean/:/var/jenkins_home/ - 数据持久化到宿主机目录-u root - 容器中使用 root 用户运行,要使用 Jenkins 构建 Docker 镜像时,默认的 jenkins 用户无权限访问 /var/run/docker.sockGrafana 是一款用 GO 语言开发的开源数据可视化工具,可以做数据监控和数据统计,带有告警功能。
Organization 相当于一个 Namespace,一个 Organization 完全独立于另一个 Organization,包括 datasource、dashboard 等,创建一个 Organization 就相当于打开了一个全新的视图,所有的 datasource、dashboard 等都需要重新创建。一个用户(User) 可以属于多个 Organization。
User 是 Grafana 里面的用户,用户可以有以下 角色
admin - 管理员权限,可以执行任何操作。editor - p不可以创建用户、不可以新增 Datasource、可以创建 Dashboard**viewer - 仅可以查看 Dashboardread only editor - 允许用户修改 Dashboard,但是 不允许保存Grafana 中操作的数据集、可视化数据的来源
在 Dashboard 页面中,可以组织可视化数据图表。
Panel - 在一个 Dashboard 中,Panel 是最基本的可视化单元。通过 Panel 的 Query Editor 可以为每一个 Panel 添加查询的数据源以及数据查询方式。每一个 Panel 都是独立的,可以选择一种或者多种数据源进行查询。一个 Panel 中可以有多个 Query Editor 来汇聚多个可视化数据集Row - 在 Dashboard 中,可以定义一个 Row,来组织和管理一组相关的 Panel在 Dashboard 的设置页面中,有 Variables 页面,在其中可以为 Dashboard 配置变量,之后可以在 Panel 的 Query Editor 中使用这些预定义的变量。变量的值也可以是通过表达式获取的值。也可以在 Panel 的标题中使用变量
例如以下 Variables 配置
Node label_values(kubernetes_io_hostname) |
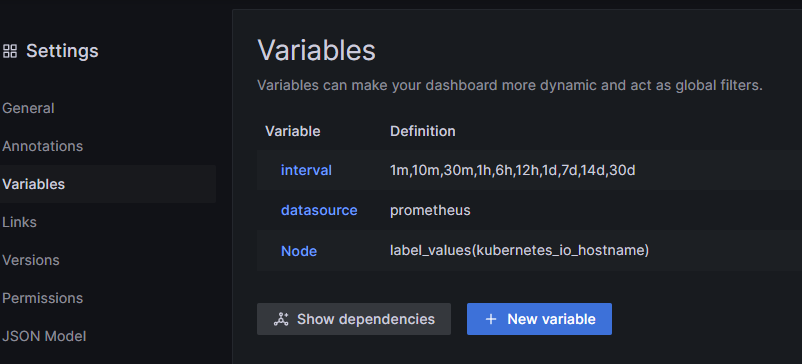
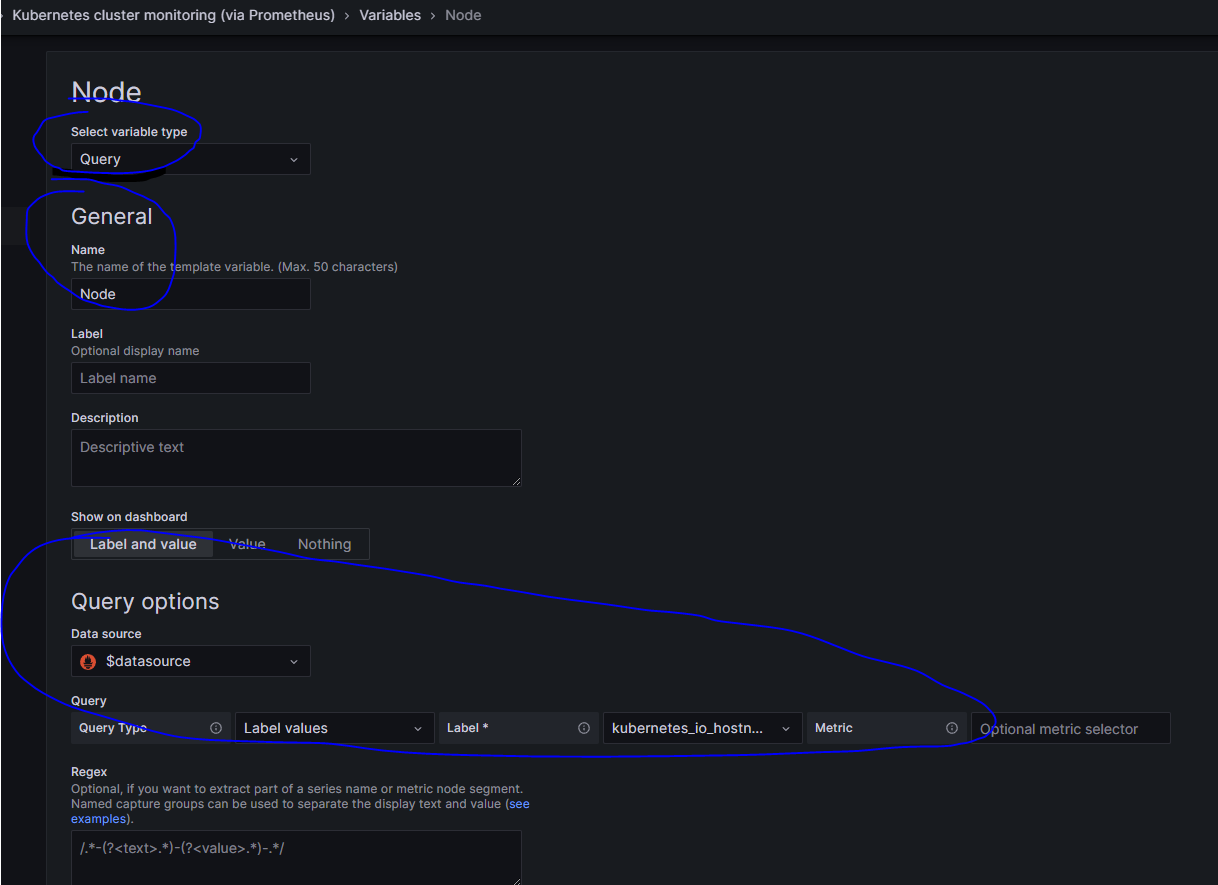
在 Dashboard 中定义了这些变量后,可以在 Panel 的 Query Editor 中使用,在 Query Editor 中使用了 Variables 中定义的变量后,在 Dashboard 的顶部下拉菜单中可以选择预定义的变量的值(需要在定义 Variables 时配置 Show on dashboard 为 Label and Value 以使在 Dashboard 顶部显示下拉菜单),Panel 中的 Query 表达式就会使用这些变量的值进行计算以及显示图表。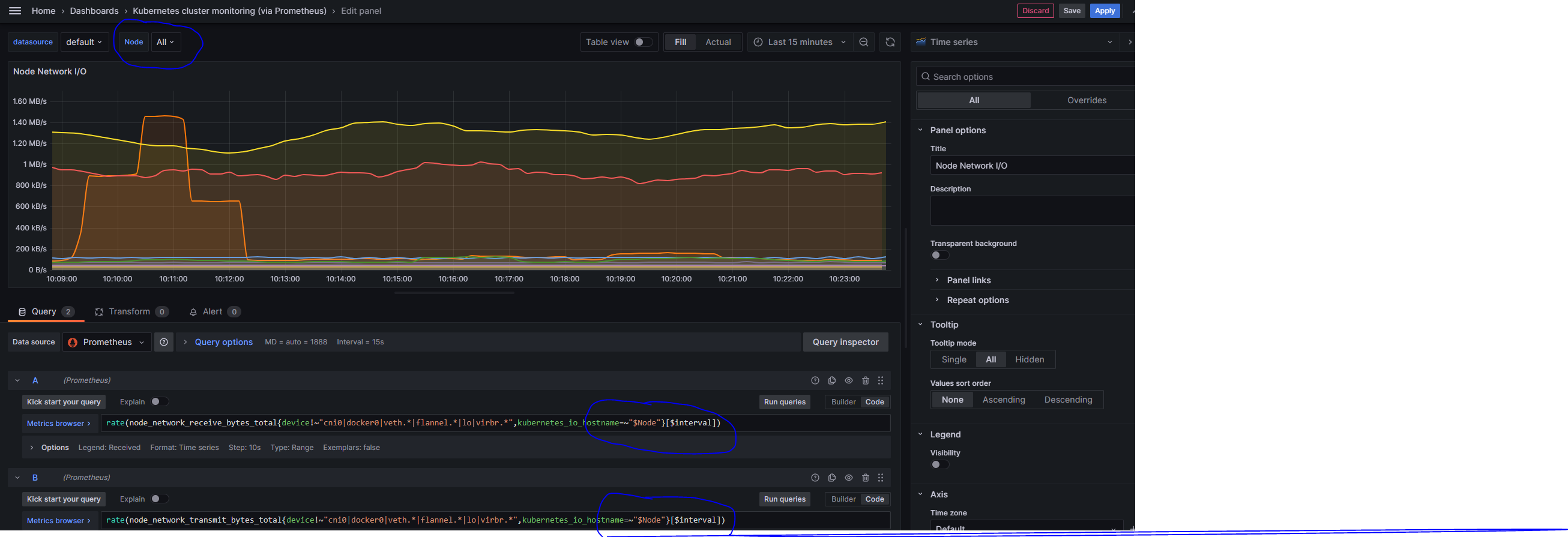
简单来说,Amazon CloudWatch 是 AWS 的全家桶级监控和观察平台。是一个用于收集、监控、分析和响应 AWS 资源及应用程序运行数据的托管服务。无论你的代码运行在虚拟机(EC2)、容器(ECS/EKS)还是无服务器环境(Lambda)中,它都能提供实时的数据洞察。
CloudWatch 的功能可以概括为以下四大支柱:
指标 (Metrics)
概念 :指标是反映系统性能的时间序列数据(如 CPU 利用率、磁盘读写、网络流量)。
AWS 指标 :大多数 AWS 服务会自动向 CloudWatch 发送免费的基础指标。
自定义指标 :你可以推送自己应用的特定数据(如:每分钟下单量)。
要查看所需服务(如 EC2)的 CloudWatch 监控指标(Metrics),只需要在 CloudWatch 控制面板中选择对应的服务即可
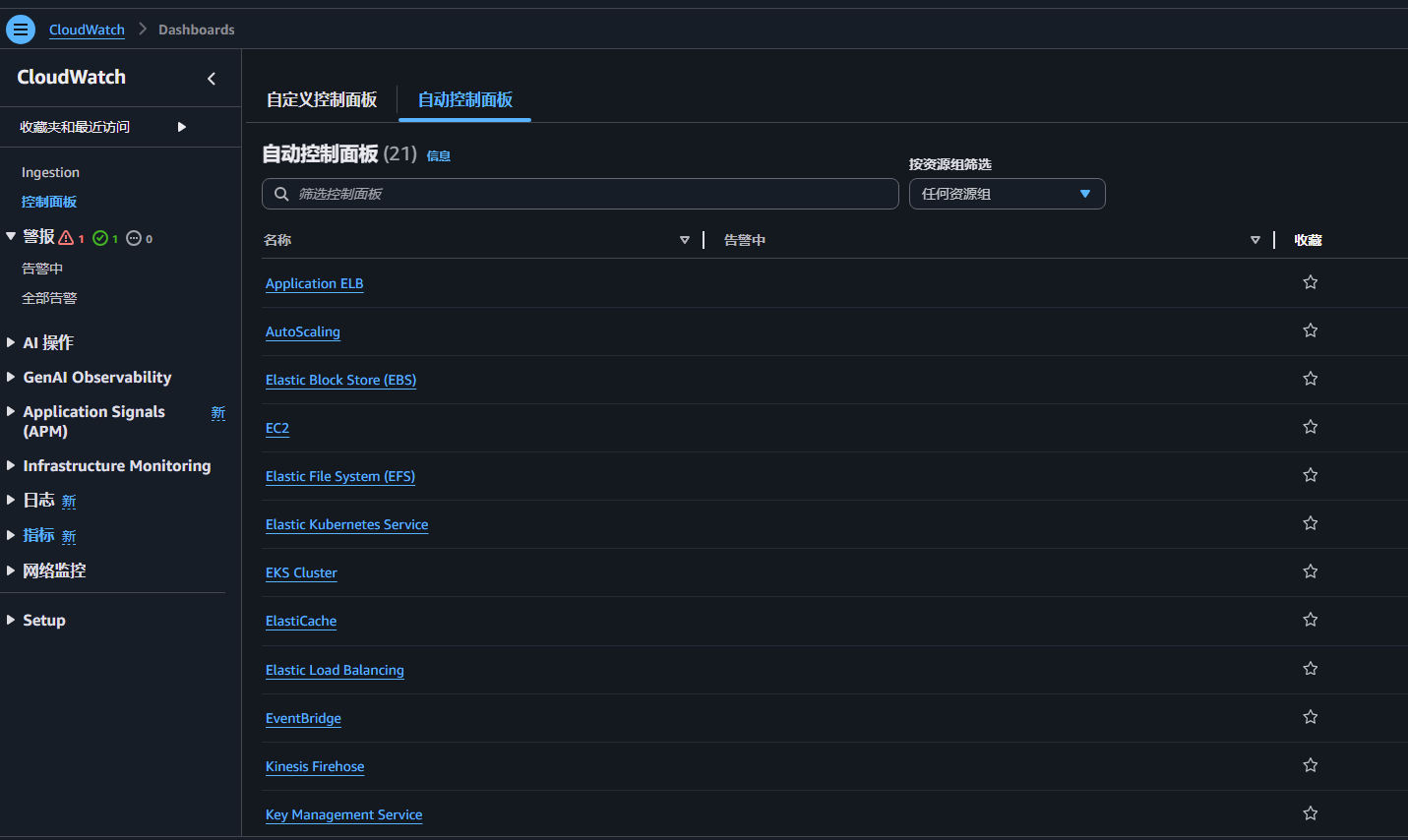
日志 (Logs)
集中化管理 :收集来自 EC2 实例、Lambda 函数、CloudTrail 或其他来源的日志文件。
日志分析 (Logs Insights) :支持类 SQL 语法的快速查询,几秒钟内就能从 GB 级别的日志中找出特定的错误代码。
报警 (Alarms)
阈值触发 :设定一个界限(例如:CPU > 80% 持续 5 分钟),达到时触发操作。
自动化响应 :报警可以发送通知(通过 SNS 邮件/短信),或者执行自动操作(如:Auto Scaling 自动增加机器,或者重启故障实例)。
要创建报警(Alarms),在 CloudWatch 控制面板左侧点击 报警 (Alarms) -> 创建报警(Create Alarm) ,根据提示 选择指标(Select Metric) , 配置 触发条件(Conditions) , 配置 动作(Actions) 可以发送通知(Notification)或者执行脚本、自动扩容等。
事件 (Events / EventBridge)
状态监听 :监听 AWS 资源的状态变更。
定时任务 :相当于云端的 crontab ,可以定时触发某个 Lambda 函数或脚本。
CloudWatch 默认提供了很多 Dashboard,也可以自定义自己喜欢的仪表盘(Create Dashboard)
AWS 里 安全组(Security Group, SG)不是“防火墙规则表”,而是一套 关系型访问控制架构
安全组是在 网络接口 (ENI) 级别运行的,而不是在子网级别。这意味着即使两个实例在同一个子网内,如果它们的安全组规则不允许通信,它们也无法互相访问。
AWS 安全组(Security Group, SG)有以下关键特性
| 关键特性 | 说明 |
|---|---|
| 有状态 (Stateful) | 如果你允许入站请求,响应流量会自动允许流出,不受出站规则限制。 |
| 白名单机制 | 默认拒绝所有流量。你只能添加“允许”规则,不能设置“拒绝”规则。 |
| 即时生效 | 修改规则后,变更会立即应用到所有关联的资源上。 |
| 拓扑关系 | 安全组之间可以 互相引用,形成拓扑关系。也可以包含 自引用规则(self-referencing SG rule),在规则中引用自身安全组 |
安全组可以绑定到:
EC2 实例
ENI(弹性网卡)
ALB / NLB
RDS
EKS Pod(通过 ENI / SG for Pod)
📌 一个资源可以绑多个 SG,多个 SG 规则没有顺序概念
📌 一个 SG 也可以被多个资源复用
引用安全组作为源(Security Group Referencing)
这是 AWS 架构设计中最优雅的功能之一。在设置规则时,源(Source)不仅可以是 IP 地址(如 10.0.0.5/32),还可以是 另一个安全组 ID 。典型场景如下:
场景 :Web 层服务器需要访问数据库层。为 Web 层服务器创建一个安全组,如 sg-web-servers
做法 :在数据库安全组中添加规则:允许来自安全组 sg-web-servers 的 3306 端口访问。
好处 :当 Web 层实例由于自动缩容(Auto Scaling)增加或减少时,你不需要手动更新 IP 地址列表,权限会自动随安全组标签流转。不关心 IP 变化,不关心实例扩缩容,只关心 角色之间的通信关系
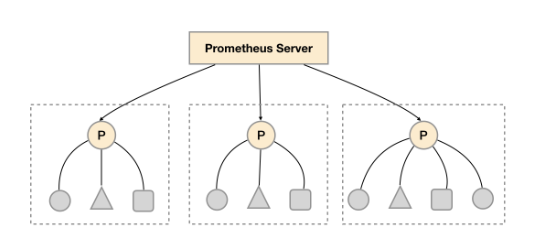
如上图所示,在每个数据中心部署单独的 Prometheus Server,用于采集当前数据中心监控数据。并由一个中心的 Prometheus Server 负责聚合多个数据中心的监控数据。这一特性在 Promthues 中称为 Federation (联邦集群)。
Prometheus Federation (联邦集群)的核心在于每一个 Prometheus Server 都包含一个用于获取当前实例中监控样本的接口 /federate。对于中心 Prometheus Server 而言,无论是从其他的 Prometheus 实例还是 Exporter 实例中获取数据实际上并没有任何差异。
以下配置示例在中心 Prometheus Server 配置其抓取其他 Prometheus Server 的指标,必须至少有一个 match 配置,以指定要抓取的目标 Prometheus Server 的 Job 名称,可以使用正则表达式匹配抓取任务
scrape_configs: |
__name__是 Prometheus 特殊的预定义标签,表示指标的名称
使用以下配置采集目标 Prometheus Server 的所有指标
'match[]':
- '{job=~".+"}'
Master Prometheus 的 Explorer(Web)中不会出现 Leaf 抓取的 Target,可以使用具体的指标如 up 等检查是否抓取到了数据
Master prometheus 上面测试 match 是否能抓取指标:
curl -G 'http://43.13.23.59:9090/federate' --data-urlencode 'match[]={__name__=~".+"}' | tail |
安装 yum 源,docker官方 centos 安装文档
yum install -y yum-utils |
安装 docker
yum install docker-ce docker-ce-cli containerd.io docker-compose-plugin |
参考链接下载rpm安装包
wget https://download.docker.com/linux/centos/7/x86_64/stable/Packages/docker-ce-19.03.15-3.el7.x86_64.rpm |
安装 docker
yum localinstall -y containerd.io-1.4.13-3.1.el7.x86_64.rpm \ |
以上 2 条命令可以使用以下 1 条命令完成
yum localinstall -y https://download.docker.com/linux/centos/7/x86_64/stable/Packages/docker-ce-19.03.15-3.el7.x86_64.rpm \ |
Docker 26 安装,适用于 Centos 8、Rocky Linux 8 等
yum localinstall -y https://download.docker.com/linux/centos/8/x86_64/stable/Packages/docker-ce-26.1.3-1.el8.x86_64.rpm https://download.docker.com/linux/centos/8/x86_64/stable/Packages/docker-ce-cli-26.1.3-1.el8.x86_64.rpm https://download.docker.com/linux/centos/8/x86_64/stable/Packages/containerd.io-1.6.32-3.1.el8.x86_64.rpm https://download.docker.com/linux/centos/8/x86_64/stable/Packages/docker-compose-plugin-2.6.0-3.el8.x86_64.rpm |
启动docker
systemctl enable docker --now |
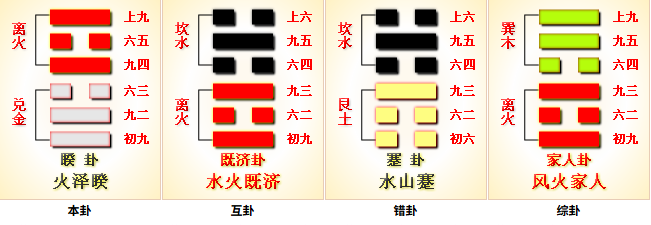
火泽睽,内(下)兑(泽、口、悦)外(上)离(火、附丽、文明),上火下泽,两相乖离,相违不相济,水火不容,相互矛盾。睽,乖异、不同、不合、背离、矛盾之卦。
睽,小事吉。 |
彖曰:睽,火动而上,泽动而下。二女同居,其志不同行。悦而丽乎明,柔进而上行,得中而应乎刚。是以小事吉。天地睽而其事同也;男女睽而其志通也;万物睽而其事类也。睽之时用大矣哉! |
象曰:上火下泽,睽。君子以同而异。 |
悔亡,丧马勿逐,自复。见恶人,无咎。 |
象曰:见恶人,以辟咎也。 |
初九阳刚处兑之下,睽之始,背道而驰之势方起。位卑而无应,本有“悔”;然刚而得正,能自守不躁,丧马勿逐,故“悔亡”。
古人注解 :
王弼
丧马自复,不必逐也。
程颐
见恶人而远之,则无咎。
睽乖之世,不可求也。
遇主于巷,无咎。 |
象曰:遇主于巷,未失道也。 |
古人注解 :
王弼
中正而应,虽睽不失。
程颐
世睽,人散,惟中正者,乃能遇其主。
巷者,穷途也。能遇其主,是未失道也。
见舆曳,其牛掣,其人天且劓。无初有终。 |
象曰:见舆曳,位不当也;无初有终,遇刚也。 |
六三阴居阳位,处兑体之终,下乘九二、上承九四,前后皆刚,位既不当,才弱志又欲进,于是“睽”之极变,显出乖离、掣肘、刑伤之象。终与上九之刚相应,得阳刚接引,故“无初有终”。
古人注解 :
王弼
处睽之极,故多碍。
程颐
始虽甚困,得刚而终有济。
刑罚之象,以明其困。
睽孤,遇元夫。交孚,厉,无咎。 |
象曰:交孚无咎,志行也。 |
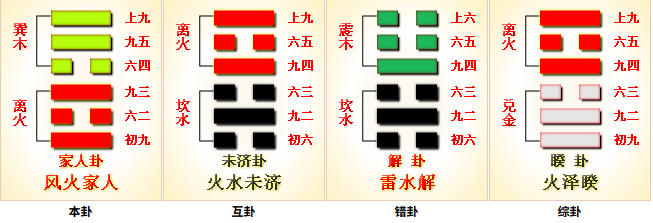
风火家人,内(下)离(火、附丽、文明)外(上)巽(风、顺),家人,内也;(火泽)睽,外也。家人卦核心为正家。
家人,利女贞。 |
彖曰:家人,女正位乎内,男正位乎外。男女正,天地之大义也。家人有严君焉,父母之谓也。父父、子子、兄兄、弟弟、夫夫、妇妇,而家道正,正家而天下定矣。 |
象曰:风自火出,家人。君子以言有物而行有恒。 |
闲有家,悔亡 |
象曰:闲有家,志未变也。 |
治理家庭(有家)之初,要先建立规范、防患未然(闲),因为此时人的心志未变,态度可控,因此设立规矩最为有效,趁此时机立规,易被接受、易于推行,故能消除悔恨。
初九是家人卦的初始爻,阳爻居阳位,刚健得正、处家之始,内卦巽为 “顺、入、教化”,初爻为 “家道之基”,刚健有决断、能立规范、防患于未然。行动契合时位、合乎正道
古人注解 :
王弼
初为家道之始,宜及其时闲之也。
程颐
家之始,宜早正其风。
始而闲之,则悔亡也。
无攸遂,在中馈。贞吉。 |
象曰:六二之吉,顺以巽也。 |
六二以阴居内卦离之中,得位又得中,上应九五之阳,有“妻道”之象;其德柔顺附丽而逊(巽),以柔顺之德承接主内之责,不刚愎、不专断,故能安定家庭、得享吉祥。
古人注解 :
王弼
不遂其志,舍己以顺。
程颐
二以柔中居内,克尽其职。
中馈者,内事也。顺则吉。
家人嗃嗃,悔厉吉;妇子嘻嘻,终吝。 |
象曰:家人嗃嗃,未失也;妇子嘻嘻,失家节也。 |
九三阳居阳位,处下卦离的终位,刚健过盛、处家之极,可能过于严苛,有失柔顺,但位正,未失大节(正家),故悔厉吉,治家宁失之严、不失之纵。
古人注解 :
王弼
刚正之道,虽悔厉,终吉也。
程颐
家道贵严,严则无失。
家若无正声,则妇子当嬉笑而不肃。
富家大吉。 |
象曰:富家大吉,顺在位也。 |
古人注解 :
王弼
处家之位,以柔为主,故能富家。
程颐
顺以得位,家道富也。
六四阴顺,相应于九三,得以富家。
王假有家,勿恤,吉。 |
象曰:王假有家,交相爱也。 |
九五为阳爻居阳位,处尊得位而正,下应六二,王者之德来主持家庭,治理有方。
古人注解 :
王弼
以阳居尊,正家之主也。
程颐
五为尊位,又得其中正,故可以正家。
以德理家,家乃吉也。
有孚威如,终吉 |
象曰:威如之吉,反身之谓也。 |
上九处家人卦最上位,为最具影响力的人,代表家庭治理的最高境界,真正的威信,来自于“有孚”(真实可信),威来自自律,而不是压制他人,要以身作则。
古人注解 :
王弼
威而有孚,德之威也。
程颐
威之在己,则终吉。
非暴怒之威,乃自反正己之威也。