Linux CPUs
CPU Architecture and Common Concepts
CPU Architecture
下图展示了一个简单的 CPU 架构图,有一个物理 CPU(Physical Processor),包含 4 个 CPU Cores,每个 CPU Core 包含 2 个 Hardware Threads,总计 8 个 CPUs。右侧的图是这 8 个 CPUs 在操作系统(Operating System)中的视图(也被称为 Logical CPU/Virtual Processor/Virtual Core) [1]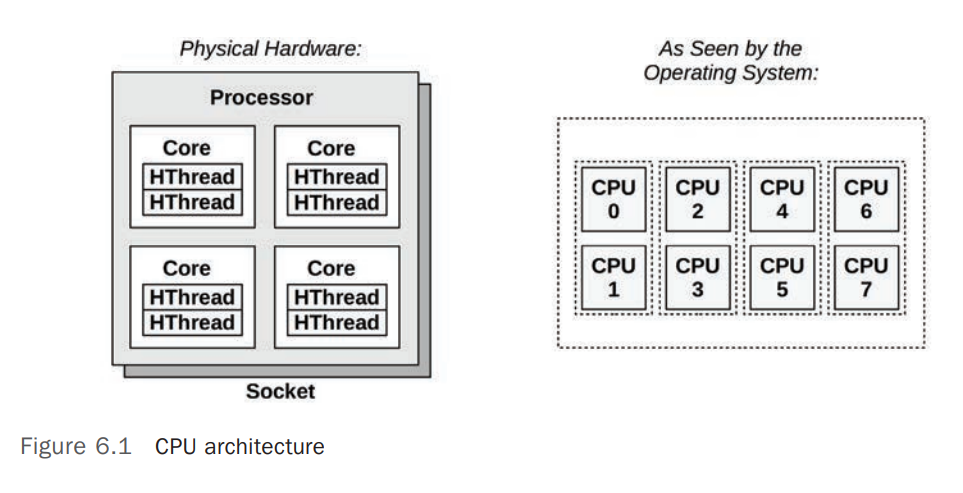
Operating System 可能对于 CPU 的拓扑结构(Topology)有一定程度的了解,如知道哪些 Logical CPU 位于同一个 CPU Core 或者 CPU Cache 是如何被共享的(Shared),这有助于 CPU Scheduler 做出更优的调度决策。
下图展示了通用 2 Core 处理器的组成。具体的组成取决于具体的处理器。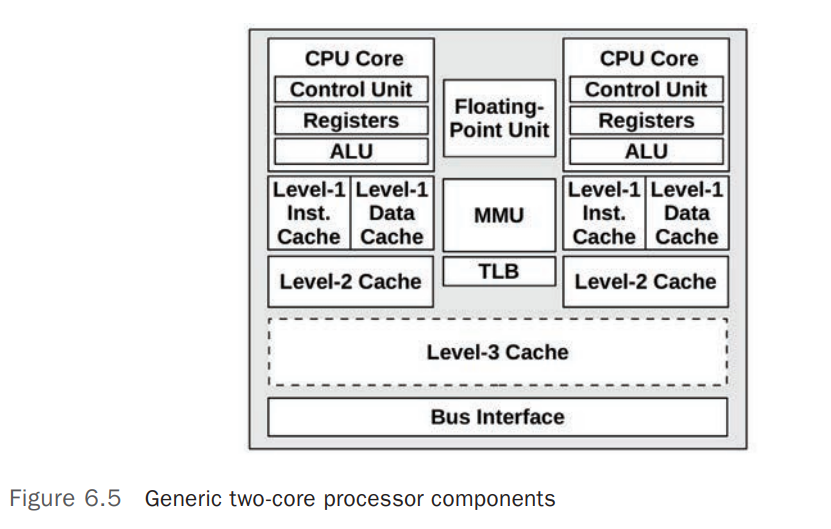
Control Unit是 CPU 处理器的核心组件,负责指令(Instruction)的Fetch、Decoding、Execution并负责保存执行结果(Storing Results)。Shared Floating-Points UnitShared Level-3 CacheMMUMemory Management Unit,负责将虚拟内存地址转换为物理内存地址(Virtual-to-Physical Address Translation)TLBTranslation Lookaside Buffer,用于 Cache 内存地址转换(Virtual-to-Physical Address Translation),未缓存的地址转换需要去 Main Memory 中的 Page Tables 中查询,MMU 的基本构成如下图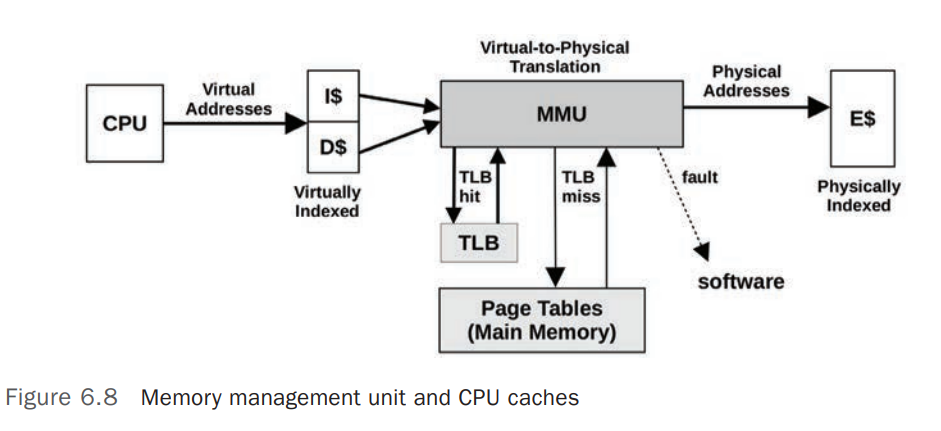
P-States and C-States
Intel 处理器的 ACPI(Advanced Configuration and Power Interface)标准定义了 P-States (Processor Performance States) 和 S-States (Processor Power States) 。 [4]
- P-States 通过在 Processor 运行过程中提供不同的 Clock Rate 提供不同的性能选择。 P0 提供最高级别的性能,P1 到 PN 提供较慢的 Clock Rate,这些级别通常可以被硬件(如依赖处理器温度)或者系统上的软件(如内核的节能策略)控制。
- C-States 提供当 CPU 处于 Idle 时,提供不同的
idle states,用于节省电力(节能),下图列出了常见的 C-States
Linux 中可以配置和管理 CPU Status 的方式包括(是否支持取决于不同的 Processor、操作系统和内核版本):
/sys/devices/system/cpu/cpufreq/policy0/scaling_available_governors可以查看可用的 CPU Scaling Governors,一般包括performance、powersave,通过配置/sys/devices/system/cpu/cpufreq/policy0/scaling_governor为对应值。 [6]cpupower工具箱,其中包括cpupower frequency-info、cpupower frequency-set等一系列管理和查看 CPU 频率等信息的工具
CPU Memory Caches
Processors(物理 CPU 处理器)提供了各种个样的硬件缓存(Hardware Caches)用于提高 CPU 读写 Memory I/O 的性能(CPU 的处理速度是 Memory I/O 处理速度的多个量级),下图展示了 Processor Caches 在大小(Sizes)和响应速度之间的关系, 离 Processor 越近,其响应速度越快,存储空间越小,成本越高(贵)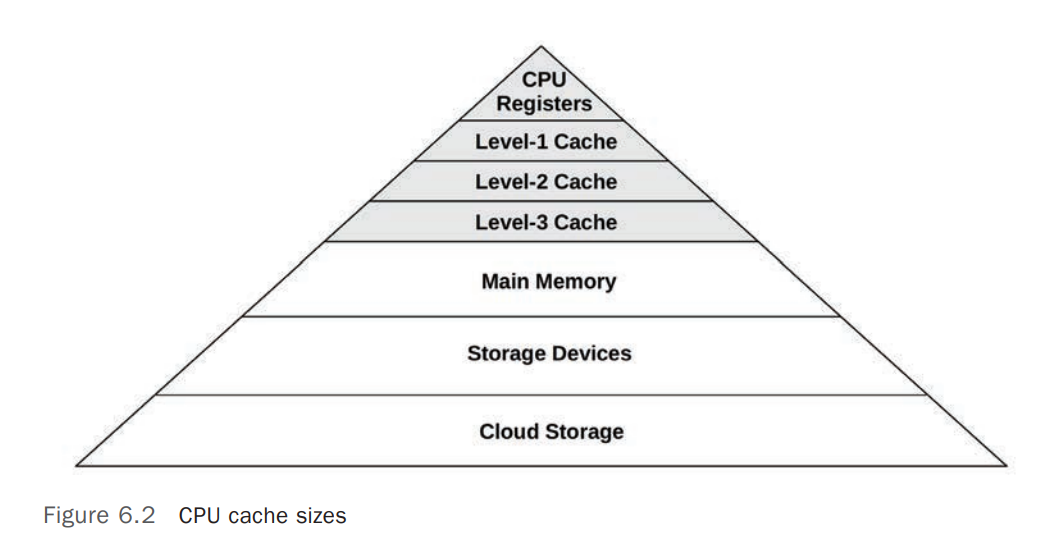
Clock Rate
CPU 时钟频率(Clock Rate) 是指 Processor 每秒跳动(转换)的次数,每一个 Processor 的时钟变化也称为一个 Clock Cycle 。 Processor 通常是以特定的时钟频率运行,比如 4GHz 的 CPU 每秒会进行 4 Billion Clock Cycles。每个 CPU 指令(Instruction)都需要通过一个或者多个 Clock Cycles 来完成。 现代 CPU 通常会变频,即调整 Processor 的 Clock Rate,如果提高 CLock Rate 以提升性能,降低 Clock Rate 以节能 。变频操作通常是通过 OS 请求 Processor 变频或者是 Processor 自动进行变频,比如内核中的 idle 线程通常会要求 CPU 降低其 Clock Rate 以节能。
Clock Rate 是衡量 Processor 能力(Capacity)的一个主要指标。通常来说,较高 Clock Rate 的 Processor 会有更高的性能,但是在性能分析的场景中,提高 CPU 的 Clock Rate 不一定会提高 CPU 性能,这主要取决于 CPU 的 Clock Cycles 到底是在忙于什么,如果 Clock Cycles 主要忙于等待 Memory Access,那么换成更高频率的处理器,并不会提高整个系统的性能。
SMT
Simultaneous Multi-Threading(SMT) 是一种由 Processor 支持的硬件多线程(Hardware Multithreading)技术,用于实现同一个 Processor Core 上的并发(Parallelism),它允许一个 CPU Core 运行多个 Thread,每个 Hardware Thread 从 Operating System 层面来看都是一个 CPU。这种技术的典型应用包括 Intel 的 Hyper-Threading 技术,允许每个 Processor Core 运行 2 个 Threads,以及 POWER8,允许每个 Processor Core 运行 8 个 Threads。
SMT 的实现通常基于 Core 运行指令(Instructions)的过程中的 Stall Cycles,当某个指令处于 Stall Cycles 时,Core 会允许调度另一个指令来运行。基于 Hardware Thread 的 CPU,其性能和单独的 CPU Core 是有区别的,这个差别取决于其上的工作负载(Workload),Stall Cycles 严重的 Workloads 会比 Instruction Cycles 严重的 Workloads 性能更好,因为 Stall Cycles 会减少竞争(Core Contention)
CPU Instructions Set
CPUs 的主要工作是执行从其指令集(Instruction Set)中选中的指令(Instruction),每个指令的执行会包括以下步骤,每个步骤都会由被称为 Functional Unit 的 CPU 组件进行处理:
- Instruction Fetch
- Instruction Decode
- Execute
- Memory Access
- Register Write-Back
步骤 4 和步骤 5 是可选的,是否有这两个步骤取决于具体的 Instruction。其中的每个步骤的执行都需要至少一个 Clock Cycle,Memory Access 通常是其中最慢的环节,可能需要好几十个 Clock Cycles 以进行内存的读写, 在这个过程中指令的执行(Instruction Execution)是处于暂停状态(Stalled)的,这些 Clock Cycles 被称为 Stall Cycles 。 [2]
IPC and CPI
Instructions Per Cycle(IPC) 是一个描述 CPU 如何使用其 Clock Cycles 的高级别指标(High Level Metric),并且是理解 CPU Utilization 的重要指标。 [3]
Cycles Per Instruction(CPI) 是 IPC 的倒数。IPC 经常用于 Linux 中,比如 perf,CPI 经常被 Intel 等使用。
较低的 IPC 代表 CPUs 经常处于 Stalled Cycles,通常是 Memory Access。较高的 IPC 代表 CPU 处于 Instruction Cycles,拥有较高的 Instruction Throughput,在性能分析中,这个指标可以为性能调试指出最好的发力点。
User Time and Kernel Time
User Time 是 CPU 花费在执行 User Space 的 Application 上的时间。
Kernel Time 是 CPU 花费在执行 Kernel Space 中的 Instructions 的时间,通常包括 Syscalls、Kernel Threads 和 Interrupts
PMCs
Performance Monitoring Counters(PMCs) 是处理器硬件上的一些寄存器(Registers),主要用于记录底层的 CPU 活动信息,主要包括以下内容: [5]
- CPU Cycles : 包括 Stall Cycles 和 Stall Cycles 的类型
- CPU Instructions : Retired (executed)
- Level 1、2、3 Cache Accesses : Cache Hists, Misses
- Floating-Point Unit : Operations
- Memory I/O : Reads, Writes, Stall Cycles
- Resource I/O : Reads, Writes, Stall Cycles
CPU Run Queues
下图展示了 CPU Scheduler 中的 Run Queues 的简要模型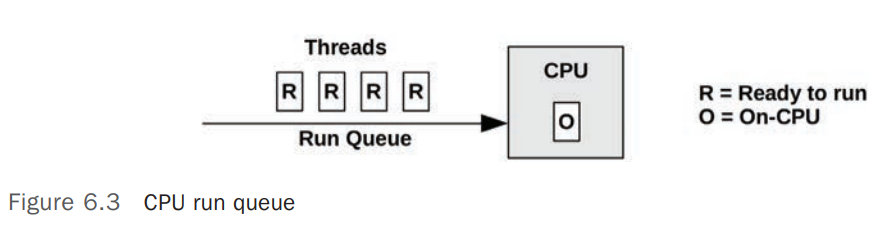
在 CPU Run Queues(CPU 调度队列)中等待调度/运行的线程/任务的数量是一个衡量 CPU 饱和度(Saturation)的重要指标,是 OS 中 CPU Load(正在 CPU 上运行的任务加正在 CPU Run Queues 中的任务数量) 的含义 ,上图中当前时刻有 4 个 Threads 在 Run Queue 中等待被调度到 CPU 上运行,有一个 Thread 正在 CPU 上运行(On-CPU),从操作系统负载(Load)指标来说,当前系统负载值为 5 ,只有一个 CPU 的情况下,可初步判断系统超负荷运行。
进程(Processes/Threads/Tasks)在 CPU Run Queue 中等待的时间被称为 运行队列延迟(Run-Queue Latency) 或者 分发队列延迟(Dispatcher-queue Latency) ,通常统称为 调度延迟(Scheduler Latency)
对于多处理器系统(Multiprocessor),内核通常会为每个 CPU 提供一个 Run Queue,并且会尽量确保同一个 Thread 每次会被调度到同一个 CPU 的 Run Queue 中,这可以确保 Thread 运行所需的 Cache 已经存在于它前一次运行的 CPU 的 Cache 中而无需重新加载(损失性能)。确保 Threads 在同一个 CPU 上运行,这种策略被称为 CPU 亲和性(CPU Affinity)
Load Averages
CPU Load 是 正在 CPU 上运行的任务加正在 CPU Run Queues 中的任务数量 ,是衡量对系统 CPU 资源需求程度的一个指标,值越大,表示系统需要更多的 CPU 资源。
Pressure Stall Information
PSI(Pressure Stall Information) 是 Linux 4.20 引进的一个新特性,用于提供有关 CPU、内存和 IO 子系统的资源压力信息。PSI 帮助管理员和开发者理解系统的资源瓶颈,优化性能和可靠性。
PSI 的核心是通过测量任务在不同资源(CPU、内存、IO)上 延迟 的时间比例,反映出系统资源的压力。
PSI 通过两种延迟指标评估压力:
Some: 部分任务因资源(CPU/Memory/IO)不足而被延迟。 值表示部分任务在等待 CPU/Memory/IO 时间片的比例。例如:部分任务在等待 CPU 时间片、等待内存分配、或等待 IO 操作完成。
Full: 所有任务都因资源不足而被延迟。例如:所有任务都在等待内存回收(OOM 回收导致)。
PSI 信息可以通过 /proc/pressure/ 目录下的文件查看:
| 文件路径 | 监控的资源 |
|---|---|
/proc/pressure/cpu |
CPU 使用压力 |
/proc/pressure/memory |
内存使用压力 |
/proc/pressure/io |
IO 使用压力 |
# cat /proc/pressure/cpu |
字段解释
some: 描述部分任务的延迟。avg10: 最近10秒内的平均压力百分比。avg60:最近60秒内的平均压力百分比。avg300:最近300秒内的平均压力百分比。total:自系统启动以来累计的延迟时间(微秒)。
full: 仅在/proc/pressure/memory和/proc/pressure/io中存在,描述所有任务的延迟。
PSI 指标可以帮助识别系统瓶颈(CPU、内存、IO)。当 some 或 full 指标持续高时,可能需要优化相关子系统。
CPU Observability Tools
要观察或者检查 CPU 状态及性能统计数据,有很多工具可用,以下列出常用工具
| Tool | Description | Examples |
|---|---|---|
uptimetopvmstat |
检查系统负载(System Load) | |
mpstat |
检查每个 CPU 的性能统计数据 | |
pidstat |
检查每个进程使用的资源统计数据 | pidstat |
perfprofile |
Profile CPU 使用堆栈(Stack Traces)。perf 可以测量 IPC 指标数据并用其来衡量基于 Clocl Rates 的性能 |
|
showboostturboboost turbostat |
检查当前的 CPU Clock Rates | |
sar |
||
time |
测试程序使用的 CPU 时间 |
turbostat
turbostat 是一个用于监控和分析 CPU 状态和功耗 的工具,通常用于调试和优化性能。它提供关于 CPU 的 频率 、 功耗 、 C 状态 、 P 状态 等详细信息。turbostat 是 Linux 内核 tools/power/x86 工具集的一部分,适用于支持 Intel Turbo Boost 的处理器。
turbostat 基本功能
- 实时监控 CPU 的频率、功耗和使用率。
- 显示各核心的 C 状态(睡眠状态)和 P 状态(性能状态)。
- 分析系统的功耗和性能特性。
- 帮助优化性能和节能配置。
输出字段详解
Core CPU Avg_MHz Busy% Bzy_MHz TSC_MHz IRQ SMI CPU%c1 CPU%c6 PkgWatt RAMWatt PKG_% RAM_% |
| 字段 | 含义 |
|---|---|
CPU |
逻辑 CPU ID。 |
Core |
CPU 所在的核心 ID(在 SMT 系统中,多个线程可能属于同一个核心)。 |
Pkg |
CPU 所在的物理包 ID。 |
Avg_MHz |
平均频率(MHz)。 |
%Busy |
CPU 在非空闲状态的时间百分比。 |
Bzy_MHz |
CPU 在忙碌状态下的平均频率。 |
TSC_MHz |
时间戳计数器的频率(通常是处理器的额定频率)。 |
C1%, C3%, C6% |
CPU 进入不同 C 状态(睡眠状态)的时间百分比。 |
POLL%, C1E% |
特殊低功耗状态的时间百分比。 |
PkgWatt |
整个 CPU 包(Package)的功耗(瓦特)。 |
CorWatt |
所有核心的功耗总和(瓦特)。 |
GFXWatt |
GPU 的功耗(如果支持)。 |
RAMWatt |
内存的功耗(如果支持)。 |
参考链接|Bibliography
Systems Performance: Enterprise and the Cloud v2
脚注
- 1.Systems Performance: Enterprise and the Cloud v2 #6.2.1 CPU Architecture ↩
- 2.Systems Performance: Enterprise and the Cloud v2 #6.3.2 Instructions ↩
- 3.Systems Performance: Enterprise and the Cloud v2 #6.3.7 IPC, CPI ↩
- 4.Systems Performance: Enterprise and the Cloud v2 #6.4.1 P-States and C-States ↩
- 5.Systems Performance: Enterprise and the Cloud v2 #6.4.1 Hardware Counters (PMCs) ↩
- 6.Systems Performance: Enterprise and the Cloud v2 #6.9.4 Scaling Governors ↩