操作系统导论
本文档中的内容主要源于以下书籍:
Memory
Main Memory
Main Memory 通常是 CPU 可以直接定位和访问的唯一的大存储设备。如果 CPU 要处理磁盘上的数据,数据必须首先被传输到 Main Memory,指令要能被 CPU 执行,也必须首先载入内存中。
Program 要能被运行,首先必须载入到内存中,并提供内存绝对地址给 CPU 以供加载指令和数据。
Logical Memory Address and Virtual Memory Address
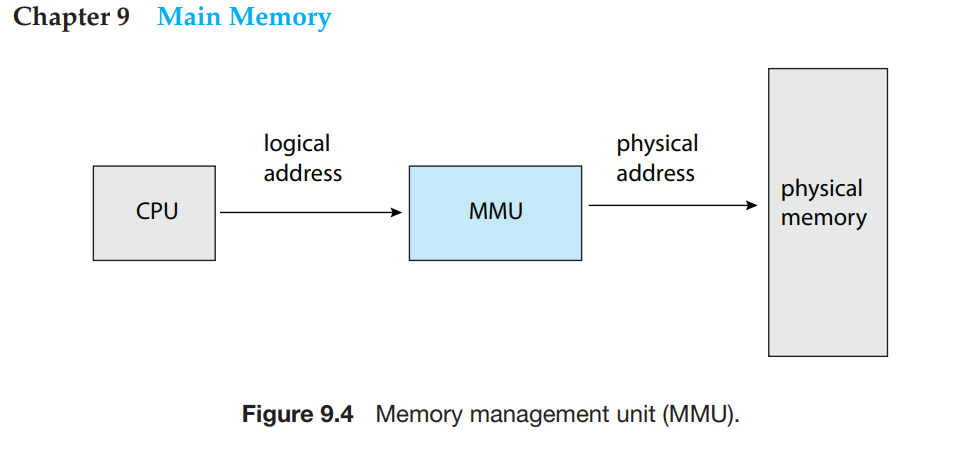
通常情况下,CPU 生成的内存地址被称为 Logical Memory Address,也称为 Virtual Memory Address。
Memory-address 注册器(memory-address register)加载的地址通常称为 Physical Memory Address。
程序运行过程中,CPU 操作的是 Virtual Memory Address,需要由硬件设备 MMU(Memory Management Unit)负责将 Virtual Memory Address space 映射到对应的 Physical Memory Address space。程序或者是 CPU 运行过程中,不会直接操作(访问/access)物理内存地址空间。
DMA
Direct Memory Access (DMA) 在 CPU 需要从存储读写大量数据到内存时,如果数据通过 CPU 中转,成本太高,为了解决这个问题,DMA 被采用,在传输大块数据时,首先在 CPU 中为数据设置好必要的 buffer、指针、计数器等资源,设备控制器(DMA Controller)直接(在磁盘和内存中)传输数据块而无须 CPU 参与实际的数据传输,只需要在数据块传输完成时,向 CPU 产生中断以指示设备控制器(DMA Controller)数据传输已完成。在 DMA 过程中,CPU 依旧可以做其他工作。 [1]
Dynamic Linking and Shared Libraries
DLLs(Dynamic Linked Libraries) 是程序运行期间需要链接的系统库文件(system libraries)。[6]
部分操作系统不支持 DLLs 机制,只能使用 静态链接(static linking),在这种情况下,应用程序运行过程中需要使用的系统库文件必须和应用程序一起编译进应用程序镜像(program image)中。假如多个应用程序使用了同样的库文件,那么这些库文件会同时存在于这些应用程序的程序镜像文件中,这些应用程序运行过程中也会在内存中加载多份同样的库文件。这可能会产生以下缺点:
- 应用程序镜像较大,占用更多磁盘空间
- 应用程序运行时,因为要加载多个同样的库文件,会占用更多的内存
- 库文件升级不灵活,要升级某个库文件,要重新编译所有使用此库文件的应用程序。
DLLs(Dynamic Linked Libraries) 是在运行过程中,动态加载库文件。这个特性在系统库文件(如 standard C language library)中很常用。程序编译过程中及运行过程中动态加载系统库文件,无需将系统库文件打包进应用程序镜像中,应用程序运行过程中动态加载系统库文件,如果要加载的目标系统库文件已经存在于内存中,则无需重复加载,直接共享使用即可。DLLs 有以下优势:
- 应用程序镜像无需包含常用的库文件,减少了磁盘使用量
- 应用程序运行时,可以在多个进程中共享库文件,无需重复加载(只存在一个库实例即可),减少了内存使用率并提升了内存效率
- 共享库文件升级后,所有加载此库文件的应用程序都可以直接使用更新后的新版本。应用程序和库文件中都包含了相应的版本信息,会防止应用程序使用错误的库版本
- 内存中可以加载多个版本的共享库文件,应用程序会使用自己的库文件版本信息加载正确的库文件
Memory Allocation
Fragmentation
假设在一个全新的未运行任何应用程序的操作系统中,初始情况下内存中存在一整块连续的可用地址范围(one large block of available memory),或者叫一个 Hole。
假设如下图所示情况,系统中运行了 processes 5, 8, and 2 并且占用了所有的内存地址范围。之后 process 8 退出,其所使用的内存释放,形成了一个 Hole,随后 process 9 开始运行并申请了一段内存,随后 process 5 退出并释放内存,导致内存中出现了 2 个地址非连续(noncontigous)的 Hole。随着系统中进程的运行和退出,内存中可能会存在很多大小不一,地址范围不连续的 Hole,这些 Hole 既是 外部内存碎片(External Memory Fragmentation)
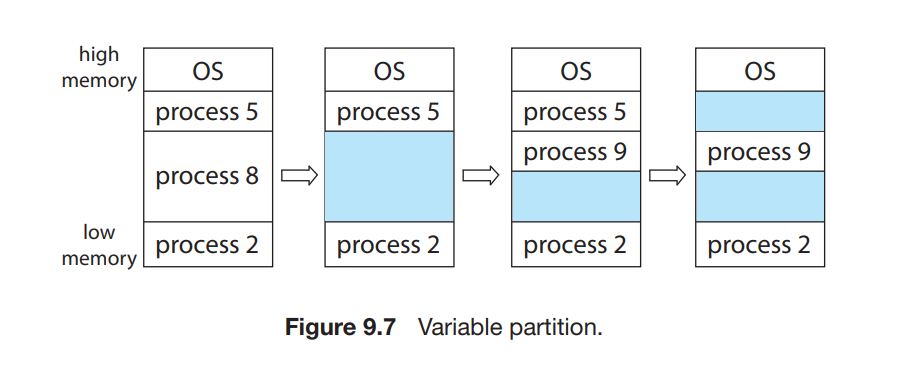
外部内存碎片(External Memory Fragmentation) 存在时,可能出现系统有足够多的空闲内存(非连续的地址空间,内存碎片)但是这些内存都是内存碎片。
在现代的内存管理中,内存的分配一般是以 block 为单位进行分配,block 是一个固定大小的内存。在这种情况下,假如 block 大小为 512 bytes,应用程序申请了 600 bytes 内存,那么需要分配 2 个 block 给应用程序,实际分配了 1024 bytes 。申请的内存(600 bytes)和实际分配的内存(2 blocks = 1024 bytes)之间的差值被称为 内部内存碎片(Internal Memory Fragmentation)
Paging
在当前的操作系统中,解决 外部内存碎片(External Memory Fragmentation) 的问题,通用解决方法是采用 内存页(Memory Paging) 技术: 应用程序申请的 Logical 内存/Physical 内存地址非连续(横跨多个 Hole)
Paging 解决了 外部内存碎片(External Memory Fragmentation) 的问题,没有解决 内部内存碎片(Internal Memory Fragmentation)
Virtual Memory
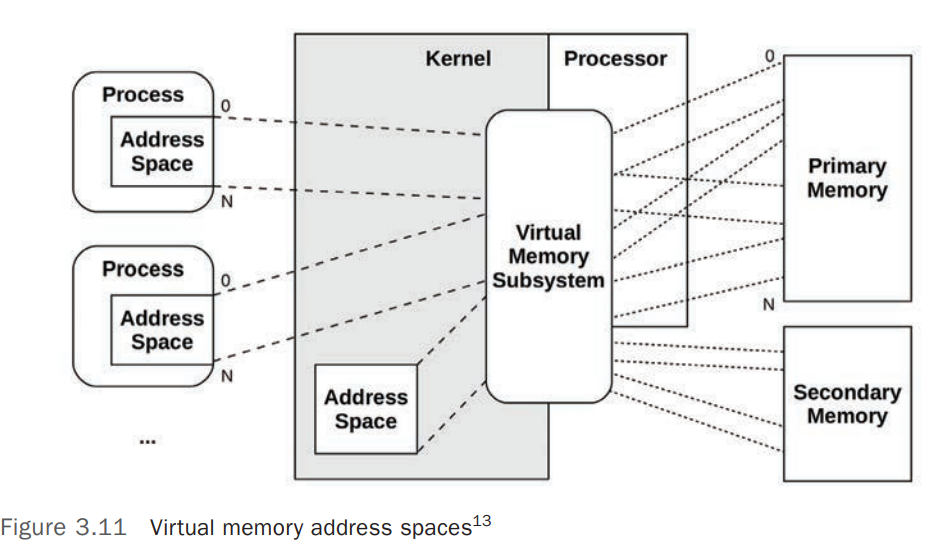
Virtual Memory 是 Main Memory 的一个抽象层,它将 Main Memory 抽象为一个近乎无限大的(Almost Infinite)拥有独立视图(Private View)的内存空间。
Virtual Memory 实现了了 允许程序运行过程中,无需将整个程序内容全部加载到内存中的技术 [7]
主要有以下优势:
- Processes/Kernel 都在自己独立的地址空间中(Private Address Spaces)运行,不用担心地址争用(Contention)
- 支持内存地址超分配(Oversubscription/Overcommit)
- 通过 Virtual Memory,OS 可以将按需 Virtual Memory 映射(Map)到 Main Memory 和 Secondary Storage(Disks)上
- 程序大小可以大于物理内存空间。开发者不必再关注物理内存是否足够。
- Virtual Memory 将 Main Memory 抽象成一个统一的大存储阵列,基于此,程序开发者可以不用关注物理内存的差异和限制。
- 允许进程共享文件和库,并实现了共享内存(Shared Memory)。
Page Fault
Virtual Memory 提供了 允许程序运行过程中,无需将整个程序内容全部加载到内存中的技术,实现此技术主要使用了 Demand Paging 技术,使用 demand-paged virtual memory,可以实现程序运行过程中,仅仅在 运行过程中必须的 pages 才会被加载到内存中,那些没有用到的 pages 永远不会加载到物理内存中,Demand Pageing 也是 Virtual Memory 的一个主要优势。
Demand Paging 技术的实现依赖于硬件的支持和 Page Fault 技术。
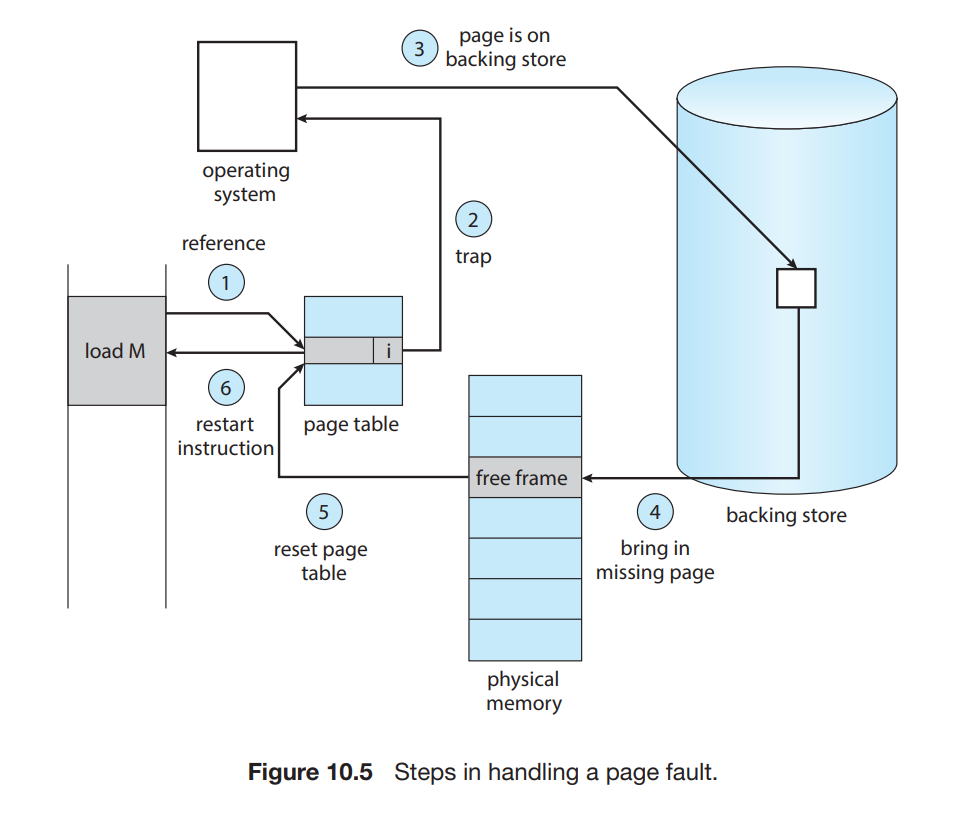
根据 Demand Paging 方案的原则,程序运行过程中用不到的 Pages 不应该被加载到内存中。因此,当一个程序刚刚启动时,它之后运行过程中所需的 Pages 理论上都不在内存中,而是存在于次级存储(secondary storage,如磁盘或者 swap)中,如果 程序运行过程中需要内存中不存在的 Pages,这时就要有机制确保实现将程序运行所需的 Pages 加载到内存中来,并且只是加载程序运行所需的 Pages,而不会加载用不到的 Pages,实现此机制的技术叫 Page Fault。
Page Fault 需要硬件支持,主要是内存组件中的硬件设备(Paging Hardware,负责 page table 内存地址转换),当程序运行过程中需要不存在于内存中的 Pages 时,会向 OS 产生一个 Page Fault 的 trap,此 trap 是一个 OS Failure(指示所需 Pages 不在内存中),硬件会注意到此 OS Failure 并进行相应处理。
操作系统处理 Page Fault 的简要工作流程如下:
- 检查并确保此内存请求合法后,如果所需的 pages 不在内存中,开始将其加载入内存(page in)
- 在物理内存中找到空闲的 frame(free frame)
- 向次级存储(secondary storage,如磁盘或者 swap)发送读取所需 Pages 到新分配的 frame 的请求
- 当存储(Pages)读取到内存完毕后,修改程序所属的 internal table 和 page table 以指示所需的 Pages 已经在内存中
- 重新启动因为缺少所需 Pages 而被中断(interrupted)的指令(instruction)
Major Page Fault
Major Page Fault 发生于所需要的 Page 不在内存中,这是系统需要在物理内存中找到可用的 Frames,然后将数据从 次级存储(secondary storage,如磁盘或者 swap) 读取到内存中并更新对应的 internal table 和 page table 以指示所需的 Pages 已经在内存中
Minor Page Fault
Minor Page Fault 发生在以下 2 中情况:
- 应用程序需要引用共享库,此共享库已经在内存中,但是应用程序的
page table中没有到此共享库所在内存页的 mapping。此种情况下,只需要更新应用程序的page table,向其中添加到共享内存库所在内存页的引用。 - Virtual Memory 中的 Page 被应用程序释放(reclaimed),对应物理内存 Frame 被标记为
free-frame,但是上面的数据未被zeroed out,此时 Page 被分配给其他应用程序。
Linux 系统中,使用 ps 命令的 -eo min_flt,maj_flt,cmd 参数可以查看进程相关的 major 和 minor page fault。
Page Replacement
现代的操作系统内存,一般都允许 超分配(over-allocating),即允许操作系统分配比实际的物理内存更多的内存给应用程序,当一个应用程序运行过程中,因为 Page Fault 要 Page In 时,可能会出现物理内存不足(no free frames on the free-frame list)的情况,此时操作系统会尽最大可能的满足应用程序对内存的申请。以前的操作系统大都采用 Swap 来实现,即将当前未在 CPU 上运行的应用程序使用的内存 swap out 到 Swap 中,并将空余出来的内存分配给要运行的程序使用。Swap 技术已被当前大多数操作系统摈弃,因为其在内存和 Swap 中拷贝数据成本太高,取而代之的技术是 Page Repalcement。
使用 Page Replacement 技术,在物理内存不足时,使用 page-replacement 算法找到物理内存中的 Frames(victim frames),将其上的内容写入(如果其上内容未改变,不用执行写入操作,如果内容改变,执行写操作)到次级存储(secondary storage),如果之后的运行过程中,应用程序需要这些数据,它会产生 Page Fault,这些数据会被重新加载回内存中。
Memory Compression
Memory Compression 是在物理内存不够时,使用的一种可替代 Page Repacement 的技术。在系统内存不足时,系统不执行 Page Replacement,而是先对选择出的 victim frames 执行内存压缩,将多个 frames 压缩成一个 frame 进而降低内存使用率,而无需进行 Page Swapping out 操作。
移动设备操作系统,包括 Android 和 IOS 都不支持
Swap和Page Repalcement,都采用了Memory Compression技术作为 Memory Management strategy 的一部分在性能方面,
Memory Compression拥有比Page Repalcement更快的速度。
Kernel Memory
内核(kernel)使用的内存和用户模式(user mode space)中的应用程序使用的内存分配机制不同。主要基于以下原因: [8]
- Kernel 中的数据结构大小差异很大,很多都比 Page Size 要小,内存使用不当会导致非常多的
internal fragmentation,导致内存严重浪费。而且很多操作系统并未将内核代码放置到 Paging Memory 中。 user-mode中的应用程序分配的内存在物理内存地址上没必要是连续地址空间,然而内核中包含的很多硬件设备都需要直接通过物理内存进行交互,无法使用Virtual Memory Interface,因此需要内存中连续的地址空间(contiguous pages)分配
CPU
SMP
Symmetric Multiprocessing (SMP),对称处理系统,在系统中存在多个处理器,每个处理器中包含一个或多个 CPU,每个 CPU 有自己的 L1 Cache (CPU 独享)和 Register,每个处理器有 L2 Cache(处理器中的多个 CPU 共享 L2 cache),同一个处理器中的 CPU 使用处理器内部通信系统通信,跨处理器的 CPU 之间通过系统总线(Bus)通信。 [2]
NUMA
系统中的处理器不宜太多,多处理器可以提高系统的任务处理能力,但是当 CPU 过高时,对系统总线的争抢会成为系统瓶颈。
为了避免太多 Processors 争抢系统总线造成的性能下降,一个可选的 方法是为每个 CPU(或 CPU 集)提供专用的本地内存,CPU 通过一个更小更快的本地 bus 连接专用的本地内存。所有的 CPU 通过一个 内部通信系统 进行连接,所有 CPU 共享同一个物理地址空间,这种架构被称为 Non-uniform Memory Access (NUMA)
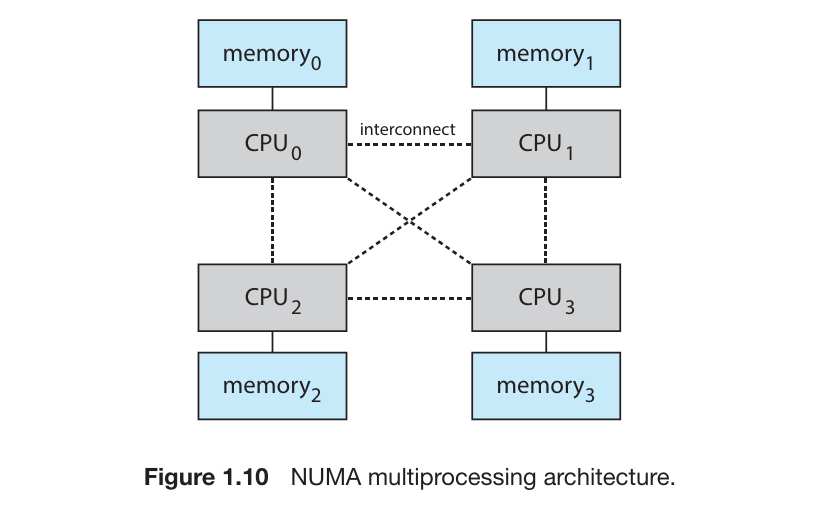
在 NUMA 系统中,内存访问分为两种类型:
本地内存访问(Local Memory Access) : 处理器访问其自身所在节点的内存。访问本地内存的延迟较低,带宽较高。
远程内存访问(Remote Memory Access) : 处理器访问其他节点的内存。由于访问的是远程内存,延迟较高,带宽较低。
NUMA 节点通过高带宽的互联技术(如 QuickPath Interconnect,HyperTransport,InfiniBand)来实现不同节点之间的通信,但这种通信仍然比本地内存访问要慢。
NUMA 的优势
提高并行处理能力 :每个处理器拥有自己的本地内存,这使得 NUMA 能够处理更多的并发任务,并且避免了在 SMP 系统中由于内存共享而产生的瓶颈。
优化内存访问 :由于每个处理器有自己的本地内存,处理器能够更高效地访问本地内存,从而减少内存访问的延迟。
适应多核和大规模计算 :在多核处理器和大规模计算环境中,NUMA 提供了更高的扩展性,允许系统能够容纳更多的处理器和内存节点。
优化内存分配策略 :NUMA 系统可以根据负载和内存访问模式智能地分配内存,减少远程内存访问的需求。
NUMA 的挑战
内存访问延迟差异 : 访问远程内存比访问本地内存慢得多,因此如何优化内存访问模式是一个挑战。程序需要特别设计,以避免频繁访问远程内存。
复杂的内存管理 : 操作系统和应用程序需要考虑 NUMA 的架构,避免内存分配和处理器调度不当造成性能下降。
负载均衡问题 : 如果某个 NUMA 节点的负载过重,而其他节点的负载较轻,可能会导致性能不均衡。操作系统需要具备有效的负载均衡机制。
现代操作系统(如 Linux、Windows)都支持 NUMA,并提供了一些功能来优化 NUMA 系统的性能:
NUMA-aware memory allocation : 操作系统可以根据当前任务的 CPU 核心来分配本地内存,避免远程内存访问。例如,Linux 使用
numactrl工具来控制 NUMA 节点的内存分配。CPU 亲和性(CPU Affinity) : 操作系统可以将进程或线程绑定到特定的 NUMA 节点上,以减少远程内存访问。
NUMA-aware scheduling : 操作系统可以根据每个 NUMA 节点的负载和内存访问模式进行任务调度,以平衡系统的负载。
Program and Process
Program 是一个静态实体,只是存储在操作系统中的文件(集合)
Process 是操作系统上的活动(Active)实体,是 Program 由操作系统加载运行之后的实体。
Process 运行过程中需要操作系统为其分配各种资源,如 CPU、Memory、Files、IO 等来完成其运行。
如果一个 Program 被操作系统运行(启动)了多次,那么其产生的多个 Process 属于分割(单独)的实体。
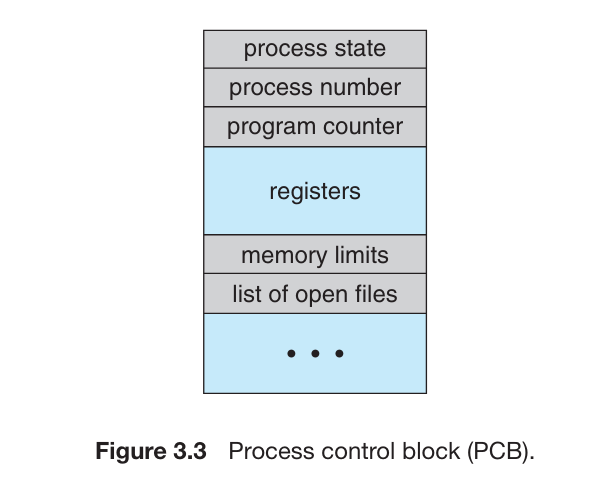
Process Control Block
PCB (Process Control Block) 代表了 OS 中进程(Process)的各种信息,包括
Process State: 进程当前的状态Program counter: 程序计数器指针。指向了当前进程中下一个要执行的指令的地址。CPU registers: 根据计算机架构的不同,可能包括计数器、栈指针(stack pointers)、通用指针(general-purpose registers)等。CPU-scheduling information: 包括进程优先级(process priority)信息、调度队列指针(pointers to scheduling queues)以及其他调度参数等。Memory-management information: 进程使用的内存信息Accounting information: CPU 数量和 CPU 使用时间,CPU 使用限制,进程数量等信息I/O status information: 分配给进程的 IO 设备,打开的文件列表等。
PCB 也可以称为 Process environment,从 User Space 和 Kernel Space 的角度,可以将其分为 User Address Space 和 Kernel Context。 [11]
Kernel Context包含了 Process 的各种属性和状态,如 PID、PPID、UID 、打开的文件描述符(File Descriptors)等User Address Space主要包含了 Process 的内存信息(Memory Segments)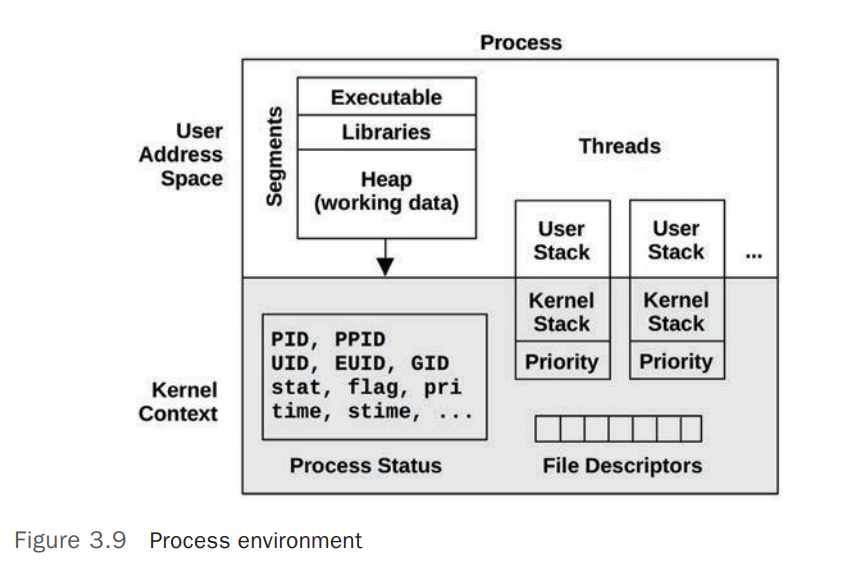
上图中的进程(Process)中包含了 2 个线程(Threads),每个线程包含自己的一些元数据(Metadata),如调度优先级(Schedule Priority),线程(Thread)包含的元数据(Metadata)远小于进程的地址空间(Process Address Space)
Scheduling Queues
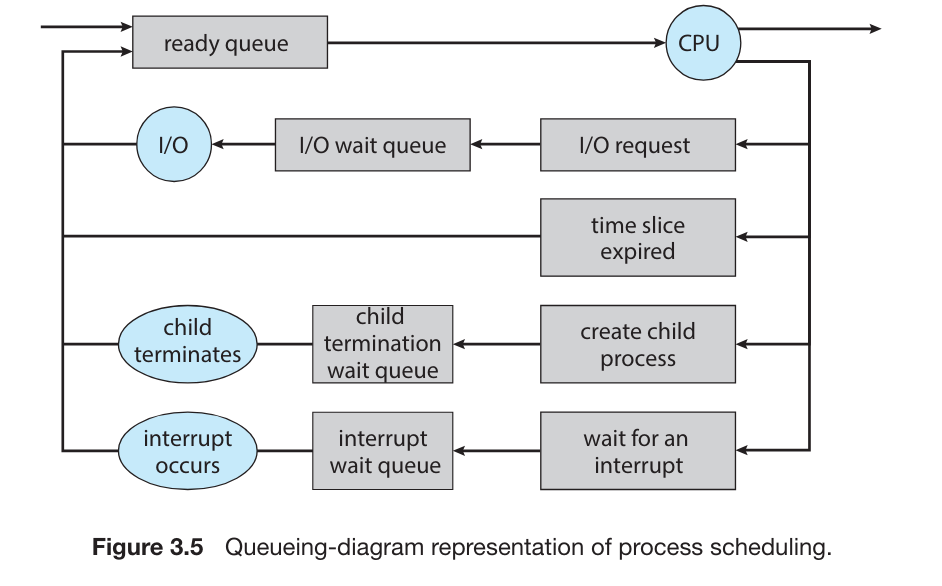
ready queue: 进程开始后,会被放入ready queue,等待 CPU 被分配给它。ready queue是一个 链接队列,其首部包含一个指向队列中第一个 PCB 的指针,每个 PCB 都包含一个指针,指向ready queue中的下一个 PCB。wait queue: 当ready queue中的进程被分配了 CPU 后,其执行一段时间后会中止或者是等待特殊事件,如 IO,在起等待的过程中会被放入wait queue
操作系统负载(system load) 衡量的就是 正在 CPU 上运行的任务加正在 Scheduling Queues 中的任务(线程/进程)的数量 。
Context Switch
CPU 会频繁的调度(因为 CPU Schedule 或 Interrupts)不同的进程来执行,当调度发生,OS 需要保存当前进程的上下文信息(Context)以备当前进程再次开始执行时恢复 Context,Context 信息保存在 PCB 中
切换 CPU core 要保存当前进程的 Context (到 PCB)并恢复另一个进程的 Context(从 PCB),这个过程被称为 Context Switch
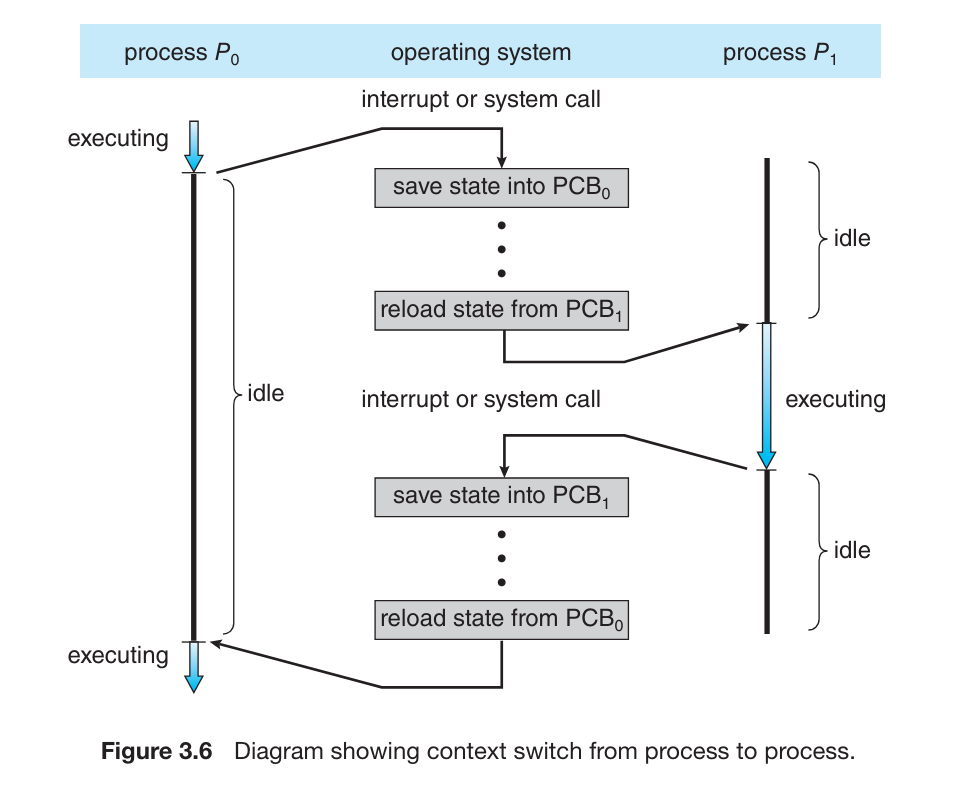
在现代化的操作系统上,OS 调度的更多的是
kernel-level threads,而不是 processes (进程)
Processor Affinity
Processes 在指定的 CPU 上运行的过程中,一般会加载数据到 CPU 的 cache 中,下一次调度到同一个 CPU 运行时,仍然可以使用 Cache 中的数据(称为 warm cache)。 [5]
假如后续 CPU 调度时,此进程被调度到了另一个 CPU,那么原来 CPU Cache 中的数据就要失效,新的 CPU 必须从新加载数据到 Cache 中。因为让 CPU Cache 中的数据失效和加载 Memroy 中的数据到 Cache 中是一个成本较高的操作,现代的 SMP 操作系统都会避免这类缓存迁移操作,会尽量将进程调度到同一个 CPU 以使用 warm cache 数据,这就是 Processor Affinity,一个进程对其正在运行的 CPU 拥有亲和性。
常见的 CPU 亲和性(Processor Affinity)有两类:
soft affinity: 尽量保证一个进程被调度到同一个 CPU,但是不保证一定,尽最大可能hard affinity: 允许配置进程只运行在选定的 CPU 集(subset of processors)
大多数系统同时实现了以上两种类型。
Disk
可以将 NVS (Nonvolatile Storage (NVS))根据硬盘组成划分成 2 大类
- 机械硬盘(Mechanical): HDDs,Optical Disks,Holographic storage,Magnetic Tape。
- Electrical(NVM): Flash Memory,FRAM,NRAM,SSD
HDD
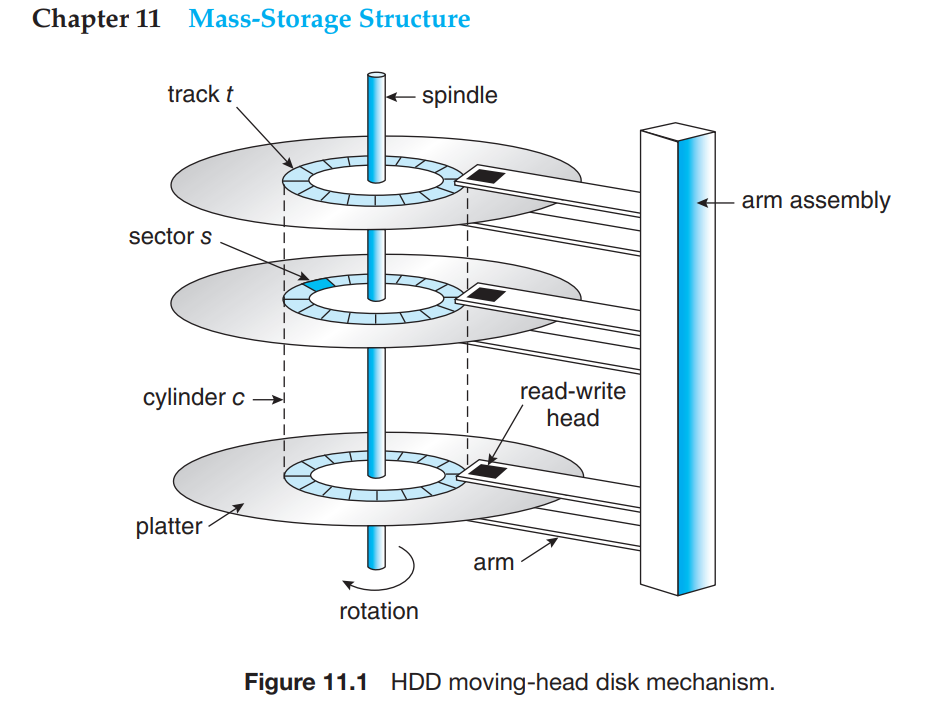
HDD (Hard Disk Driver)的主要组成如上图。主要包括以下主要组件: [9]
Platter
Platter 的两面由磁性材料(magnetic material)覆盖组成。Read-Write Head
Platter 的两面分别有个Read-Write Head(读写磁头) 负责在磁碟(Platter)上写入/读取数据。磁头和 Platters 之间一般由一层非常薄的气体作为保护层,如氦气(helium),磁头和 Platter 表面接触会造成 Platter 表面的磁性材料损坏,这被称为Head Crash,一般无法修复,磁盘上面数据会丢失。Disk Arm
Disk Arm 连接了Read-Write Head(读写磁头) 和Arm Assembly,Read-Write Head(读写磁头) 通过 Disk Arm 的移动来寻址到不同的存储单元。Tracks
Platter 的面被(逻辑/Logically)分割成圆弧形(两个不同半径的圆分割组成的部分)Sectors
Tracks被逻辑(Logically) 分割成Sectors(扇形),Sectors 是 HDD 磁盘上最小的传输单元,一般有固定大小的存储空间(2010 年前一般是 512 bytes,之后大多升级到了 4KB)。每个 Track 上面包含多个 Sectors。Cylinder
每个 Platter 上面,固定位置的Disk Arm/Read-Write Head垂直组成的存储单元组成一个Cylinder。每个磁盘上面会包含很多个同心的(Concentric) Cylinder
HDD 磁盘中包含一个高速旋转的 马达(disk driver motor),HDD 磁盘的传输速度(Transfer Rate)和马达的旋转速度相关,通常使用 RPM(Rotations Per Minute) 来衡量 HDD 磁盘的转速,通常在 5400/7200/15000 RPM。有些 HDD 磁盘在电量不足或者使用频率低时会降低 RPM 来节能和提高磁盘使用寿命。
Transfer Rate 是衡量数据在 HDD 磁盘和操作系统之间传输速度的指标。这个性能指标主要受到 寻址时间(Positioning Time) 或者叫 Random-Access Time 的影响,这个时间主要由 2 部分组成,一般在 几毫秒(several milliseconds)
Seek Time: Disk Arm 移动到目标 Cylinder 的时间Rotational Latency: 目标 Sector 移动到 Disk Read Wirte Head 的延迟。
NVM
Nonvolatile Memory Devices (NVM) 使用电特性(Electrical)存储,而不是机械(mechanical)特性,相比 HDD,其拥有更高的可靠性和性能(没有 Seek Time 和 Rotational Latency),更加的省电,劣势是他们价格相对 HDD 更贵并且存储空间相对较小,但是随着时间推移,这些劣势也会逐渐消弭。
NVM 存储的 写入性能 通常和其存储可用大小相关,因为 NVM 设备内部通常会保留部分空间用于 Garbage Collection 和 Over-Provisioning(通常为 20%),如果可用空间小,会导致 写性能 下降。
NVM 设备的寿命和其 Erase 的次数正相关
Error Detection and Correction
Error Detection 是计算机系统中最基础的功能之一,普遍用于 Memory、Network、Storage 系统中。Error Detection 的常见功能包括:
- 检测存储中存储的数据是否发生了(错误/非自发/无意的)改变,比如某个数据位由 0 变为了 1
- 网络数据在传输过程中发生了改变
- 存储设备上的数据读写不一致。
通过检测这些错误,可以防止在使用这些错误数据之前对其进行修正或者是发送通知给使用者。
Parity Bit
Memory 长使用 Parity Bit (奇偶校验位) 算法进行 Error Detection,Memory 系统中的每个 Byte 都有一个对应的 Parity Bit,此 Parity Bit 记录了对应的 byte 中 1 出现的次数是 偶数(even,Parity Bit = 0) 还是 奇数(odd, Parity Bit = 1)
根据 Parity Bit 算法的计算结果,会出现以下情况:
- Memory 中的一个 byte 中的一个 bit 位发生了改变,那么此 byte 计算出的 Parity Bit 值和保存的 Parity Bit 值不一样,说明数据不可靠
- Memory 中的一个 byte 中的任何 bit 都正常,但是保存的 Parity Bit 值发生了变化,那么此 byte 计算出的 Parity Bit 值和保存的 Parity Bit 值不一样,说明数据不可靠
- Memory 中的一个 byte 计算出的 Parity Bit 值和保存的 Parity Bit 值一致,说明数据可靠
Parity Bit 无法检测 2 个 bit 位的错误,因为 2 个 bit 位的数据错误,其正确计算出来 Parity Bit 的值不变。
Parity Bit 容易实现并且计算起来非常的快,但是因为 Parity Bit 的存在,会为每个 byte 增加一个 bit 的大小
CRCs
CRCs (Cyclic Redundancy Check) 是网络传输中常用的 Error Detection 算法。可以检测到多个 bit 位的错误。
ECC
ECC (Error Correction Code) 算法不仅可以检测到数据错误,并且可以尝试恢复数据。
EEPROM
EEPROM(Electrically Erasable Programmable Read-Only Memory) 是主板上的一个 NVM Flash Memory Firmware。
服务器上电运行后启动的第一个程序是 bootstrap loader program (操作系统启动引导程序,如 Linux 中的 grub2,其启动之后会加载操作系统)。RAM 是易失性存储,不能将 bootstrap program 放置到 RAM 中,当下主机会使用 EEPROM 放置 bootstrap program。bootstrap program 可以被修改,但是不能频繁修改,它属于慢速存储,其中包含了不经常会使用的静态程序和数据。比如 iPhone 使用了 EEPROM 存储了设备 serial numbers 和 hardware information
RAID
RAID (Redundant Arrays of Independent Disks) 。
RAID 0: Striping Volume
RAID 0,Striping Volume,条带卷,在多个存储设备上面,以 Block 为基本单位组成条带(Strip),数据分散写入到每个存储设备的对应的条带上,读取时从多个设备上的对应条带中读取。
- 不提供任何冗余(Redundancy),任意存储设备损坏,会导致整个存储系统上的数据损坏
- 有极高的读写速度,在多个设备上并发的读写
- 存储设备利用率 100%
RAID 1: Mirrored Volume
由 2 或多块物理存储设备(physical storage device)组成一个逻辑存储设备(logical disk),每次写入数据时,同时写入到 2 个或多个物理存储设备。
- 提供冗余(Redundancy),数据同时写入 2 个或多个物理存储设备上,只有在所有数据盘都损坏的情况下数据才会损坏
- 有极高的读取速度,可以从每个镜像盘读取数据
- 数据写入速度降低,因为要将数据写入多个数据盘,可能会导致写入速度下降
- 存储设备利用率 50%
RAID 4: Block-Interleaved Parity
RAID 4 使用 RAID 0 的 Strip(条带)作为基础,至少需要 3 块数据盘。数据存储以 Block 为单位。
假设由 3 块数据盘组成 RAID 4,数据写入过程如下:
- 写入数据的第一个 block 写入到第 1 块数据盘中,第二个 block 写入到第 2 块数据盘中,对写入第一块盘和第二块盘上的这 2 个 block 做 Error Correcting Code 计算,计算结果存储在第 3 块数据盘中。
- 第三个 block 继续写入到第 1 块数据盘中,第四个 block 写入到第 2 块数据盘中,对此 2 个 block 做 Error Correcting Code 计算,计算结果存储在第 3 块数据盘中
- 依次类推,直到数据写入完成。
- 其中一块盘存储了 Error Correction Code
- 假如其中一个数据盘或其上的一个 Block 损坏,那么这块数据可以根据其他盘上的数据和 Error Correction Code 做计算进行恢复
- 有极高的读写速度,在多个设备上并发的读写。
- 存储设备利用率 (N-1)/N
RAID 5: Block-Interleaved Distributed Parity
和 RAID 4 唯一的不同是: RAID 4 使用一个单独的盘存储了 Error Correction Code(Parity Bit),RAID 5 将 Error Correction Code(Parity Bit)分布存储在所有数据盘上,通过将 Parity 分布到所有的数据盘上,避免了专用的 Parity Block 的盘压力太大。
RAID 6: P + Q redundancy scheme
RAID 6 为每 4 个 Block 保留了 2 个冗余(Redundant)的 Block,使用了更复杂的算法来进行 Error Detect 和 Error Correcting,可以支持 2 块数据盘损坏。
RAID 10
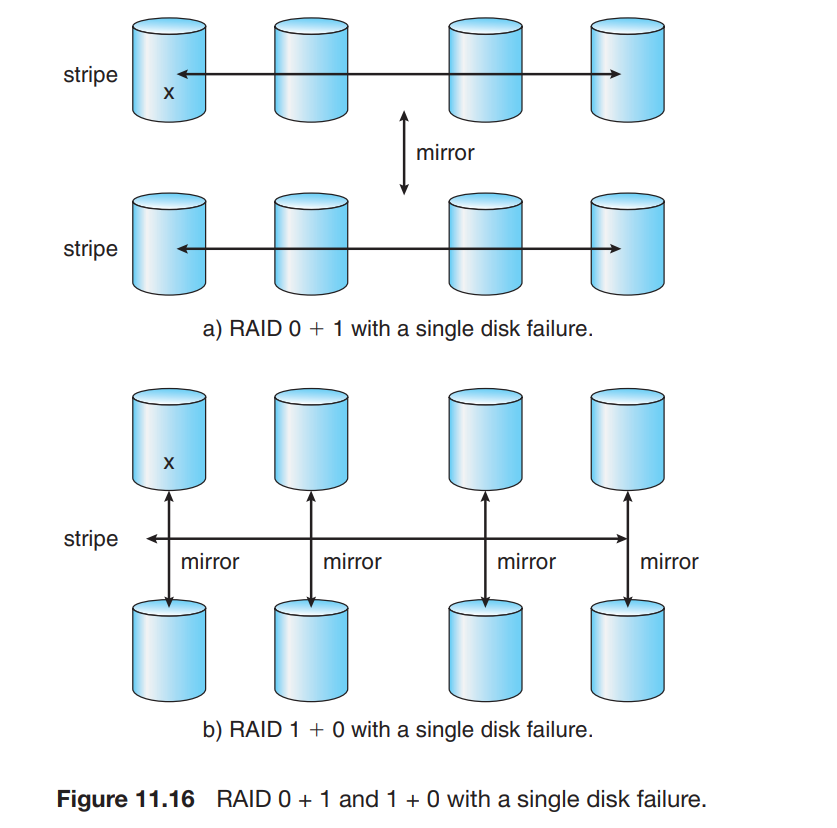
RAID 10 的结构:
- 首先将硬盘分成多个镜像组(RAID 1),每个镜像组包含两个或多个硬盘。
- 然后将这些镜像组组合成一个条带组(RAID 0)。
优缺点:
高数据冗余:每个数据块都有一个镜像副本,因此可以抵抗单个硬盘故障。
高读写性能:通过条带化技术,可以提高读写速度。
成本较高:需要至少四个硬盘,而且有效存储容量只有硬盘总数的一半。
RAID 01
RAID 01 的结构:
- 首先将硬盘分成多个条带组(RAID 0),每个条带组包含两个或多个硬盘。
- 然后将这些条带组组合成一个镜像组(RAID 1)。
优缺点:
高读写性能:通过条带化技术,可以提高读写速度。
数据冗余:整个条带组被镜像,因此可以抵抗硬盘故障。
成本较高:需要至少四个硬盘,而且有效存储容量只有硬盘总数的一半。
数据恢复复杂:如果一个硬盘发生故障,整个条带组都需要被重建,恢复时间较长。
RAID 10 和 RAID 01 在单一硬盘故障时的恢复方式基本一致,都是从对应的镜像组恢复数据到故障硬盘。 在涉及到多个硬盘的故障的情况下,RAID 10 相比 RAID 01 拥有更多的优势:
- RAID 10 提供了更高的冗余性和恢复灵活性,因为它允许多个独立的镜像组。
- RAID 10 可以承受每个镜像组中的一个硬盘故障而不影响整体系统。
- RAID 01 在任一条带组中失效的硬盘超过一个时,会导致整个 RAID 组不可用。
File System
File Systems 为访问(stored、located、retrieve)存储系统(Storage)上存储的文件提供了高效和便利的途径(方式)。文件系统的设计主要涉及到以下问题: [10]
- File System 对用户(User)应该如何呈现。包括如何定义文件以及文件属性,允许哪些操作,目录结构是怎样的(如何组织)
- 使用怎样的算法来创建文件或者目录结构,以及如何将逻辑上的文件(logical files system)和物理存储(硬件)上的内容进行对应
File System 通常由多个功能分层(Levels or layers)构成,其中 下层为上层提供服务,上层利用下层提供的服务来构建文件系统的功能(特性)
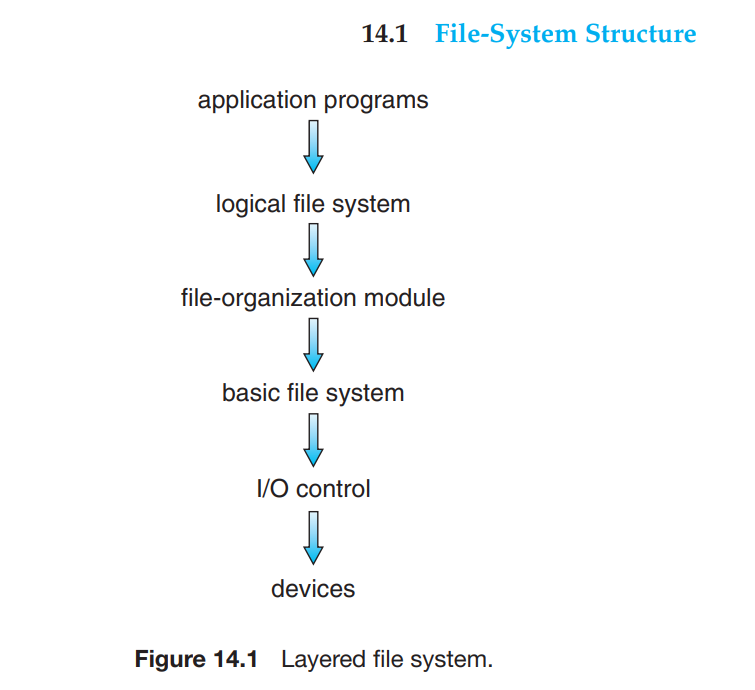
在如上图所示的分层的文件系统架构中,主要包括以下层:
I/O control: 主要由存储设备驱动器(Device Drivers)和中断控制器(interrupt handlers)组成。主要功能是在存储设备和主内存之间传输数据。它接受更高层的指令(如retrieve block 123),并将此指令转换为能被存储设备驱动器识别的针对存储硬件设备的指令。basic file system: 在 Linux 系统中被称为“block I/O subsystem。这一层的主要功能是将上层的通用的读写 block 的指令发布给正确的存储设备驱动器(device driver)来读写存储设备上的 block。它发送给存储设备驱动器(device driver)的是 逻辑块地址(Logical block address),它还负责 IO request scheduling 以及 buffers 和 caches。file-organization module: 主要存储了文件和他们对应的logical blocks的信息。还包括free-space manager,用来跟踪未分配的logical blocks,当file-organization module需要空闲块时提供空闲的块地址信息。logical file system: 负责管理metadata信息。Metadata 信息存储了所有的文件系统结构信息(包括 目录结构、文件名),只是不包括具体的数据。关键信息包括 FCB (file-controle blocks,即inode),存储了文件的具体信息如owership、permissions、locations of file contents(location of logical blocks)。
VFS
VFS(Virtual File System) 是内核提供的用来抽象(Abstract)各种文件系统类型的接口。VFS 使添加各种新类型的文件系统到内核变得更加的灵活,Programs 可以使用相同的方式访问各种不同类型的文件系统。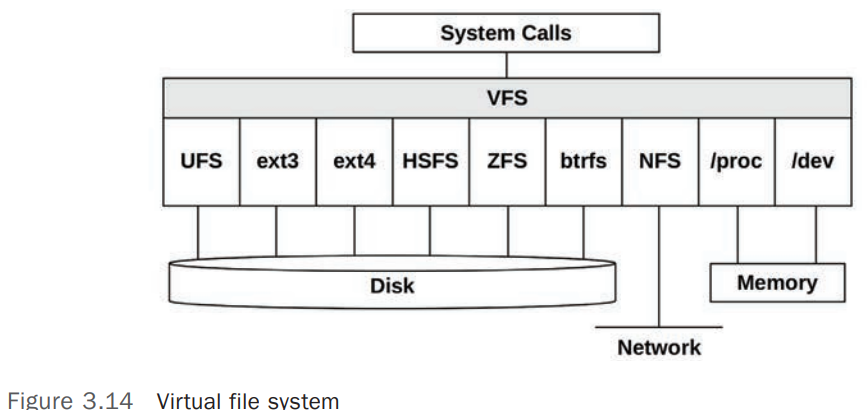
IO Stack
对 基于存储设备的文件系统(Storage-Device-based Filesystem) 来说,从应用软件(Application Software)到存储设备(Storage Device)之间的调用路径被成为 I/O Stack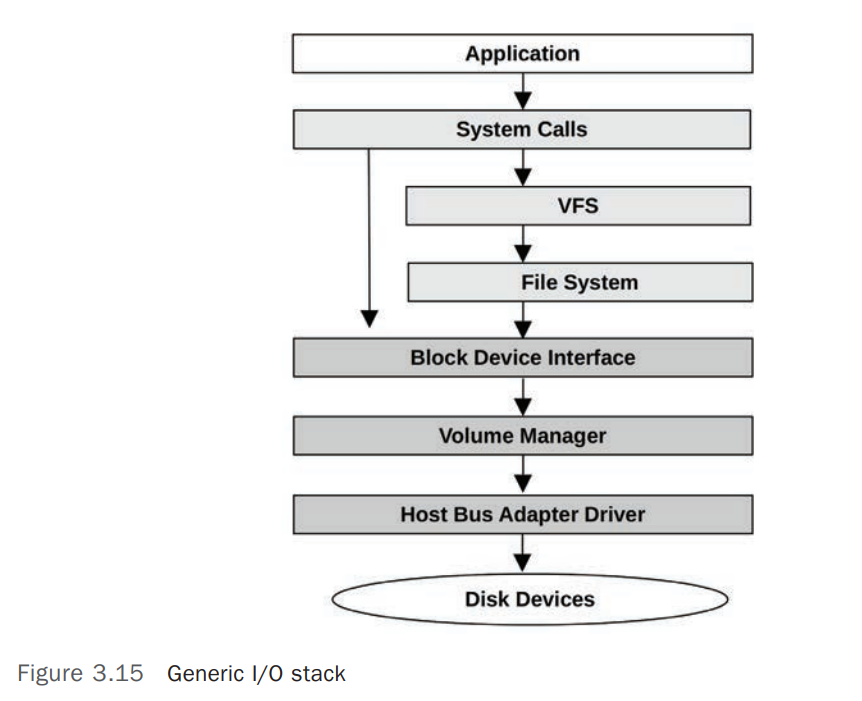
图中左侧跨过 VFS 和 File System 直接调用块设备(Block Device)的路径一般是管理工具(Administrative)或者 Databases 使用。
Caching
硬盘 IO 通常有较高的延迟,文件系统模型又涉及多层,会导致更大的延迟,为了解决这些延迟问题,文件系统和存储设备通常使用 读写缓存(Caching Reads and Buffering Writes) [12]
Caching 可能会包括以下部分,这些缓存会自上而下搜索:
| # | Cache | Examples |
|---|---|---|
| 1 | Client Cache | Web browser Cache |
| 2 | Application Cache | |
| 3 | Web Server Cache | Apache Cache |
| 4 | Caching Server | memcached |
| 5 | Database Cache | MySQL |
| 6 | Directory Cache | dcache |
| 7 | File Metadata Cache | inode cache |
| 8 | Operating System buffer Cache | Buffer Cache |
| 9 | File System Primary Cache | Page Cache, ZFS ARC |
| 10 | File System Secondary Cache | ZFS L2ARC |
| 11 | Device Cache | ZFS vdev |
| 12 | Block Cache | Buffer Cache |
| 13 | Disk Controller Cache | RAID Card Cache |
| 14 | Storage Array Cache | |
| 15 | On-disk Cache |
system-wide open-file table And per-process open-file table
大多数操作系统再打开并使用文件之前,都需要(implicitly or explicitly)系统调用 open(),操作系统维护了一个 open-file table,维护着所有的打开文件的信息。当一个文件操作(如读,写,执行等)被请求前,系统调用 open(),文件会通过一个 index 被加入到 open-file table,当文件不在使用时,open-file table 中关于此文件的条目(index) 被移除。
系统中维护了 2 中类别的 open-file table:
per-process open-file table: 跟踪进程打开的文件列表,此表中的列表实际是指向system-wide open-file table中相关条目(entry)的指针(pointer)。system-wide open-file table: 维护了系统上所有的打开的文件信息,保存了如 文件路径、文件大小、文件时间属性(access time 等)、open count等信息,当一个进程打开一个文件后,system-wide open-file table中就会添加一个此文件相关的条目,当另一个进程打开同样的文件后,进程的per-process open-file table中只是会添加一条到system-wide open-file table中对应文件的引用(entry)。system-wide open-file table中的每个条目还维护了一个open count,记录了有多少进程打开了此文件,当某个进程关闭此文件后,其open count会减少,值为0时,表示没有任何进程打开了此文件,此条目可以从system-wide open-file table中移除。
system-wide open-file table 里面关于文件的信息,保存的主要是 FCB 的拷贝(Copy)
per-process open-file table 里面存储的主要是到 system-wide open-file table 里面的对应文件的指针(pointers)
Linux 系统中要查看 open-file table 相关信息,可以使用 lsof、fuser、/proc/<pid>/fd/ 等方法。
Security
Encryption
Symmetric Encryption
在 对称加密算法(Symmetric Encryption) 中,加密和解密使用同样的密钥(Key)
Glossary
GNU: GNU’s Not Unix,Richard Stallman 于 1984 年开始开发的自由(free)的类 Unix 操作系统。包括编译器、编辑器、库文件、游戏等应用,没有内核。
GNU/Linux: 1991 年,Linus Torvalds 发布了最初版类 Unix 操作系统内核,并使用了 GNU 提供的编译器和工具。
FSF: Free Software Foundation,自由软件基金会,由 Richard Stallman 于 1985 年成立,旨在鼓励和推动自由软件的使用和开发。自由不等于免费
GPL: GNU General Public License。
ELF: Executable and Linkable Format.
ABI : Application Binary Interface. ABI 定义了在不同架构以及不同的操作系统中,一个二进制代码(Binary Code)提供的接口的差异性。ABI 定义了二进制代码的底层细节,如地址宽度、向系统调用(system calls)提供参数的方法、运行时的堆栈(stack)的组织方式、系统库的二进制格式、数据类型等信息。ABI 是架构级别(architecture-level)的定义,如果一个二进制文件是根据特点的架构(如 ARMv8 processor)编译(链接)而成,那将他迁移到支持此 ABI 的另外的系统上,理论上它也可以正常运行。[3]
RTE : Run Time Environment.
LKMs : Loadable Kernel Modules.
Darwin : iOS/MacOS 底层的类 Unix 操作系统,主要基于 BSD UNIX 的 microkernel
IPC : Inter-Process Communication.
RPCs : Remote Procedure Calls.
JNI : Java Native Interface.
HAL : Hardware Abstraction Layer.
UEFI : Unified Extensible Firmware Interface. 最新的硬件初始化程序,用于取代 BIOS
initramfs : 在系统启动过程中(Bootstrap Program 运行过程,比如 GRUB),因为根文件系统(root file system)还未挂载,为了挂载根文件系统,必须加载必要的驱动程序和内核模块,boot loader 会创建一个临时 RAM 文件系统,即 initramfs。一旦内核开始运行,必要的驱动已经安装,内核会将根文件系统从 initramfs 切换到已经挂载的根文件系统。然后启动 systemd 进程。
CMT : Chip MultiThreading. 一个物理 CPU 核上实现了双线程或多线程的支持。在一个 CPU 线程因等待内存加载数据而空闲(Memory Stall)时,另一个 CPU 线程开始执行。每个 CPU 线程拥有自己独立的状态数据(architectural state)、指令指针(instruction pointer)、注册器(regester set)等,可以将其当作一个单独的逻辑 CPU 来运行单独的线程(进程/Job)。如 Intel 的超线程(hyper-threading)或者叫 SMT(Simultaneous Multi-Threading)
CFS : Completely Fail Scheduler。Linux kernel 2.6.23 版本开始默认的 CPU 调度算法。
MMU : Memory Management Unit.
HDD : Hard Disk Driver.
SSD : Solid State Disk.
ATA : Advanced Technology Attachment. 存储设备接口协议
SATA : Serial ATA. 存储设备接口协议
SAS : Serial Attached SCSI. 存储设备接口协议
USB : Universal Serial Bus. 存储设备接口协议
FC : Fibre Channel. 存储设备接口协议
NVMe : NVM express. NVM 存储设备专用的通信接口协议。NVM 设备通过 NVMe 接口协议直接连接在系统 PCI 总线上。 相比其他存储接口协议(如 SATA 、SAS 等)增加了吞吐量及减少了延迟。
HBA : Host Bus Adapter.
HAS : Host Attached Storage.
NAS : Network Attached Storage. 存储设备接口协议,使用基于 TCP/IP 的 RPC 实现,如 NFS
FC : Fibre Channel,光纤通道,存储设备接口协议
SANs : Storage Area Networks. 使用基于 TCP/IP 的 RPC 实现
RAIDs : Redundant Arrays of Independent Disks.
DES : Data Encryption Standard.
AES : Advanced Encryption Standard
IKE : Internet Key Exchange.
TLS : Transport Layer Security. SSL 的升级版
SSL : Secure Sockets Layer.
MAC : Mandatory Access Control. Linux 系统中,是 SELinux 的一部分。
DAC : Discretionary Access Control. UNIX-based 系统上使用的权限控制策略(chmod、chown、chgrp)
PAM : Pluggable Authentication Modules. UNIX-based 系统上使用的用户鉴权模块
BSD : Berkeley Software Distribution. 第一个 Unix 发行版,由 California Berkeley 大学发行
FSF : Free Software Foundation, 自由软件基金会,由 理查德斯托曼 于 1984 年发起的开源运动,GNU 是其主要的一部分
IPIs : Inter-Processor Interrupt, 也叫 SMP Call 或者 CPU Cross Call。在 SMP CPU 架构中,多个 CPU 可能需要相互协同工作,某个 CPU 需要其他一个或多个 CPU 执行某个操作,此时需要使用 IPS 通知其他 CPU
参考链接|Bibliography
Operating System Concepts v10 Online
Systems Performance: Enterprise and the Cloud v2
脚注
- 1.Operating System Concepts v10 Online 1.2.3 I/O Structure ↩
- 2.Operating System Concepts v10 Online 1.3.2 Multiprocessor Systems ↩
- 3.Operating System Concepts v10 Online 2.6 Why Applications Are Operating-System Specific ↩
- 4.Operating System Concepts v10 Online CHAPTER 5 CPU Scheduling ↩
- 5.Operating System Concepts v10 Online 5.5.4 Processor Affinity ↩
- 6.Operating System Concepts v10 Online 9.1.5 Dynamic Linking and Shared Libraries ↩
- 7.Operating System Concepts v10 Online CHAPTER 10 Virtual Memory ↩
- 8.Operating System Concepts v10 Online 10.8 Allocating Kernel Memory ↩
- 9.Operating System Concepts v10 Online 11.1.1 Hard Disk Drives ↩
- 10.Operating System Concepts v10 Online 14.1 File-System Structure ↩
- 11.Systems Performance: Enterprise and the Cloud v2 3.2.6 Processes ↩
- 12.Systems Performance: Enterprise and the Cloud v2 3.2.11 Caching ↩