Python selenium 使用说明
环境信息
- Selenium > 4.0
Selenium 是一个用于自动化 Web 浏览器操作的工具,可以用于模拟用户与网站的交互。
使用 pip 安装 Selenium 库
pip install selenium |
Selenium 需要一个 WebDriver 来控制不同的浏览器。可以根据要使用的浏览器下载相应的 WebDriver。以下是一些常见的浏览器和对应的WebDriver下载链接:
- Chrome : ChromeDriver 下载
- Firefox: GeckoDriver 下载
- Edge: EdgeDriver 下载
下载 WebDriver 并确保它在系统路径中可用。WebDriver 和浏览器具有版本对应关系,要确保版本匹配
selenium 常见用法总结
本示例中以 Chrome 浏览器为例。
创建一个浏览器实例,并请求指定的页面
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.example.com")关闭当前浏览器窗口
driver.close()
最大化浏览器窗口
driver.maximize_window()
后退
driver.back()
前进
driver.forward()
刷新页面
driver.refresh()
关闭浏览器
driver.quit()
查找元素并进行操作
通过元素 ID 查找元素并输入文本
element = driver.find_element(By.ID, "element_id")
element.send_keys("Hello, Selenium!")通过元素名称查找元素并点击
element = driver.find_element(by.NAME, "element_name")
element.click()通过链接文本查找元素并点击
element = driver.find_element(By.LINK_TEXT, "Click Here")
element.click()根据元素的 class 属性查找元素。如果有多个具有相同 class 属性的元素
element = driver.find_element(By.CLASS_NAME, "your_class_name")
element.click()查找网页源代码。
driver.page_source包含了网页源代码 [1]from selenium import webdriver
driver.implicitly_wait(10)
driver.get("https://the-internet.herokuapp.com/upload");
driver.find_element(By.ID,"file-upload").send_keys("selenium-snapshot.jpg")
driver.find_element(By.ID,"file-submit").submit()
if(driver.page_source.find("File Uploaded!")):
print("file upload success")
else:
print("file upload not successful")
driver.quit()
通过 XPath 定位元素
- 使用绝对 XPath 定位元素(不推荐,因为它对页面结构的变化敏感)
element = driver.find_element(By.XPATH, "/html/body/div[1]/div/div[3]/p/a")
- 使用相对XPath定位元素(更具灵活性,建议使用) 在上面的示例中,我们使用 XPath 定位元素。以下是 XPath 定位的一些常见语法:
element = driver.find_element_by_xpath("//div[@class='example']/p/a")
//:从文档的根节点开始搜索/:从当前节点的子节点中搜索。[]:用于筛选元素,可以包含属性名和值。@:用于引用元素的属性。
示例:
language_button = driver.find_element(By.XPATH, "//button[contains(@class, 'btn-lang') and contains(@class, 'btn-dropdown')]") |
实际使用中,自己分析 HTML 结构很难找到对的 XPath。这时候需要使用浏览器的开发者工具,在浏览器的开发者工具中,定位到目标元素,可以选择复制 XPath 获得完整的 XPath 路径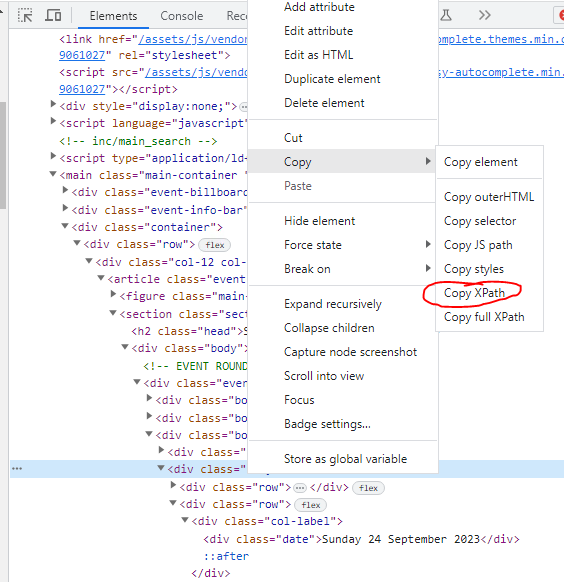
如果要获取 XPath 列表中的最后一个元素,可以参考以下方法
(//*[@id="section-event-round"]/div/div[1]/div[3]/div[2]/div[2])[last()] |
这个 XPath 将选择位于 //*[@id="section-event-round"]/div/div[1]/div[3]/div[2]/div[2] 位置的最后一个 <div> 元素。
处理表单
查找表单元素并填写表单字段
username = driver.find_element(By.ID, "username")
password = driver.find_element(By.ID, "password")
username.send_keys("your_username")
password.send_keys("your_password")提交表单
login_button = driver.find_element(By.ID, "login_button")
login_button.click()
处理下拉框或选择框
- 通过标签名查找下拉框元素
from selenium.webdriver.support.ui import Select
select = Select(driver.find_element(By.TAG_NAME, "select")) - 通过文本选择选某一个选择项
select.select_by_visible_text("Option 1")
- 通过值选择选某一个选择项
select.select_by_value("option_value")
- 过索引选择选某一个选择项
select.select_by_index(2)
等待元素加载
- 使用
WebDriverWait来等待特定元素出现或满足特定条件from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "element_id"))
)
切换窗口
切换窗口要使用窗口句柄来操作
获取当前窗口句柄
current_window_handle = driver.current_window_handle
获取所有窗口句柄
all_window_handles = driver.window_handles
切换到新窗口
driver.switch_to.window(new_window_handle)
截图
截取整个页面的屏幕截图
driver.save_screenshot("screenshot.png")
截取特定元素的屏幕截图
element = driver.find_element(By.ID, "element_id")
element.screenshot("element_screenshot.png")
配置浏览器启动选项
要自定义浏览器的启动选项,可以使用 Options
from selenium import webdriver |
如果要为 Selenium 指定 Chrome 浏览器的路径,使用 binary_location 属性 [2]
from selenium.webdriver.chrome.options import Options |
等待元素出现
在使用 Selenium 和浏览器交互的过程中,经常会遇到元素未加载完成而与元素交互导致的失败。这种情况可以使用 time.sleep() 方法等待一段时间。但是这种等待时间无法确定多少合适。 [3]
Implicit waits
Seleniu 也提供了 Implicit waits 机制。这是一个全局配置。默认值为 0。表示元素如果未出现,立即返回错误;如果配置了等待时间, driver 将会等待设置的时间,如果在配置的时间内元素依然未出现,则报错,如果在等待的时间内元素出现,程序立即执行,因此使用 Implicit waits 不会增加额外的等待时间。
driver.implicitly_wait(2) |
Implicit waits 和 Explicit waits 不要混用,否则会使等待时间变长
Explicit waits
Explicit waits 是添加到代码中的循环,用于轮询应用程序以获取特点条件。如果在指定的超时值之前未满足条件,代码将会给出超时错误。
revealed = driver.find_element(By.ID, "revealed") |
常见问题
浏览器页面中可以看到元素,但是 Selenium 中无法找到元素
现代的很多 HTML 页面中,肉眼可见的 HTML 页面,可能不止一个 HTML 页面,一个主页面中,可能还包括子 HTML 页面(如 ifram 框架)

比如上图所示页面中,肉眼可见其中包含按钮:搜索、统计 等,但是检查网页代码,其中并没有 搜索、统计 等按钮,Selenum 亦无法定位到这些元素。主要原因就是因为这些按钮(搜索、统计 等)并不在主页面中,而是包含在单独的 iframe 中。针对此种情况,在操作 iframe 中的元素之前要先切换到对应的 iframe
以下代码演示 iframe 相关操作
# 获取所有的 iframe 元素 |
浏览器下载文件因为安全原因需要手动确定
- chrome 版本127.0.6533.89
使用 Selenium 在 Chrome 浏览器中下载文件时,如果目标网站使用 HTTP 协议并下载压缩文件(如 zip 类型文件),下载时浏览器会弹出确认保留按钮
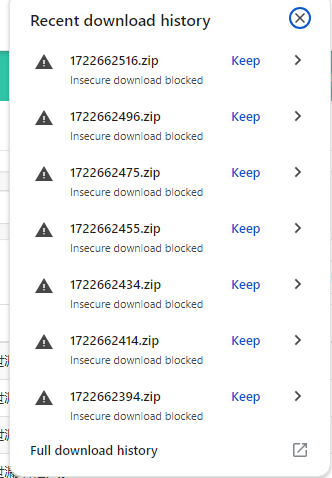
具体错误提示: Chrome blocked this download because the site isn't using a secure connection and the file may have been tampered with
这是因为 Chrome 的安全机制导致,要解决此问题,可以参考以下选项配置 Chrome 浏览器:
from selenium import webdriver |
解决此问题的关键选项说明:
--unsafely-treat-insecure-origin-as-secure=http://example.com: This is an experimental flag that allows you to list which domains to treat as secure so the download is no longer blocked. [4]--disable-features=InsecureDownloadWarnings: This is a more stable flag that disables the insecure download blocking feature for all domains.
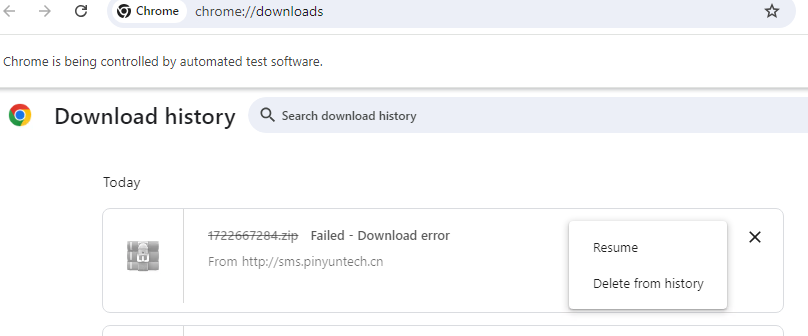
Failed - Download error
环境信息:
- Windows Operating System
- chrome 版本127.0.6533.89
使用以下 Chrome 配置,Chrome 下载文件时报错: Failed - Download error,并弹出 Resume 按钮供选择,点击 Resume 按钮后提示内容: Failed - Unknown server error. Please try again, or contact the server administrator.
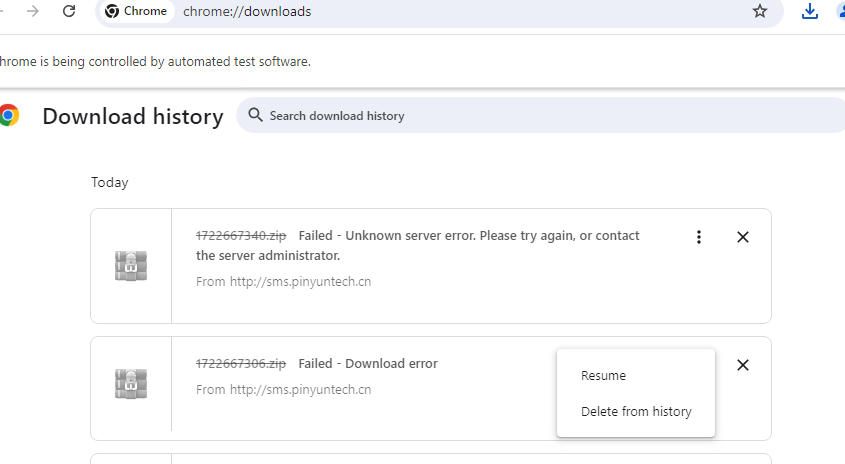
from selenium import webdriver |
影响下载的关键配置是 "download.default_directory": f"{os.path.abspath(os.path.dirname(__file__))}/Downloads",在注释此行后可正常下载,添加此行后下载失败。
导致此问题的原因是下载目录得路径有问题,可以修改为以下代码解决:
# 设置下载目录为当前脚本所在目录下的 Downloads 文件夹 |