logstash 使用详解
环境信息
- Centos 7
- logstash 8.8
一个 Logstash 管道(pipeline) 至少要包含 2 个组件: input 及 output,可以包含可选组件 filter [2]
input- 负责从数据源获取数据filter- 负责按照配置修改数据output- 负责将数据写入目标存储,如 Elasticsearch
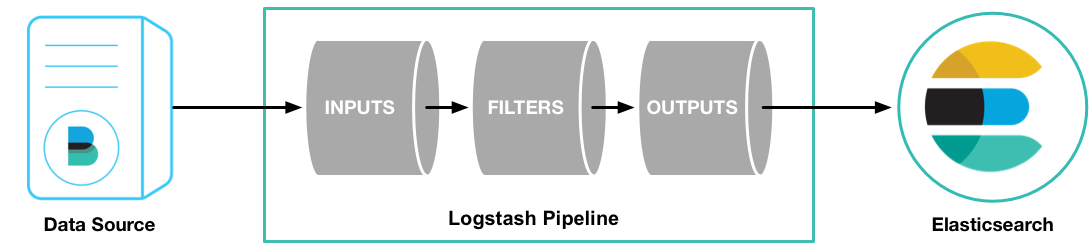
安装
yum 安装
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch |
运行 Logstash 后,可以使用最基本的 Logstash Pipeline 测试 Logstash 运行是否正常
/usr/share/logstash/bin/logstash -e 'input { stdin { } } output { stdout {} }' |
-e- 选项用来在 command line 中指定配置
运行之后在 shell 中输入内容,Logstash 会为数据添加元数据后输出到 stdout,表明 Logstash 运行正常
hello world |
logstash 服务默认端口 5044
logstash 命令汇总
logstash 命令是 Logstash 的 command line 命令,使用它可以管理 Logstash
| 选项 | 说明 | 示例 |
|---|---|---|
-e |
用来在 command line 中指定配置 | logstash -e 'input { stdin { } } output { stdout {} }' |
-f |
指定配置文件 | |
--config.test_and_exit, -t |
测试配置文件并退出 | 测试配置文件 |
--config.reload.automatic |
自动加载配置文件 配置文件启动后无需重启 |
logstash-plugin
查看已安装的插件列表
/usr/share/logstash/bin/logstash-plugin list |
Logstash 配置
Logstash 主要有以下几种类型的配置文件
- Logstash 服务配置文件(
/etc/logstash/logstash.yml),控制 Logstash 启动和运行的配置 - JVM 配置文件(
/etc/logstash/jvm.options) - Pipeline 配置文件(
/etc/logstash/pipelines.yml),定义了 Logstash 的 Pipeline log4j2**配置文件(/etc/logstash/log4j2.properties)**,假如要修改 Logstash 程序的日志级别,可以修改此配置文件
Logstash 服务配置文件
Logstash 服务配置文件默认为 /etc/logstash/logstash.yml,主要为配置 Logstash 程序运行时的配置信息。配置文件中的大多数配置都具有 command-line flags ,并且 command-line flags 会覆盖 logstash.yml 中的配置。 [4]
pipeline.ordered
在 Logstash 的设计中,也是默认配置,Logstash 不保证 event 被顺序处理,在批量处理中,event 的顺序可能因为 (filter) 处理速度关系而被打乱。假如 event 的顺序至关重要,就需要使用 pipeline.ordered => true 选项来确保 event 被按序处理。
如果 pipeline.workers 被配置为 1,pipeline.ordered 会自动被配置为 true
Pipelines 配置文件说明
默认的 Pipelines 配置文件为 /etc/logstash/pipelines.yml,其中 include 配置目录 /etc/logstash/conf.d/*.conf
Logstash 的 Pipeline 最简单的配置示例如下
Sample Logstash configuration for creating a simple |
要测试配置文件是否有问题,可以使用以下命令
/usr/share/logstash/bin/logstash -f /etc/logstash/logstash.yml --config.test_and_exit |
如果配置文件异常,测试配置文件会显示配置文件错误的位置
[LogStash::Runner] runner - The given configuration is invalid. Reason: Expected one of [ \t\r\n], "#", "input", "filter", "output" at line 9, column 1 (byte 68) after |
Logstash Plugins
input
input 和 output 插件是 Pipeline 中必须存在的插件
stdin
从 stdin 中读取输入数据
input { |
file
从指定文件中读取数据
input { |
beat
filebeat
读取从 filebeat 中输出的数据,参考以下配置,Logstash 会监听 5044 端口,Filebeat 将数据发送到 Logstash 服务器的 5044 端口,Logstash 会使用 input 插件读取数据(event)
input { |
output
input 和 output 插件是 Pipeline 中必须存在的插件
stdout
使用 stdout 可以将数据输出到 stdout
output { |
file
使用 file 可以将数据输出到指定的文件中
output { |
Elasticsearch
output { |
Grok
Grok 插件是 Logstash 为数不多几个默认就启用了的插件。Grok 插件主要用来将非格式化的数据分析成格式化的可查询的数据
input { |
Grok 通过(预先定义或者临时定义的)正则表达式来匹配任意的文本数据,其使用格式为 [5]
{SYNTAX:SEMANTIC} |
SYNTAX是要匹配文本的正则表达式的名称SEMANTIC是要给予正则匹配到的文本内容的标识/ID
例如有以下日志内容:
55.3.244.1 GET /index.html 15824 0.043 |
可以使用以下 Grok 语法,为各个字段添加字段名
input { |
%{IP:client}会正则匹配 IP,并将匹配到的 IP 存储到字段client中%{WORD:method}会正则匹配word%{URIPATHPARAM:request}会正则匹配 URI%{NUMBER:bytes}会正则匹配 数值,包括int和float类型的数据
默认情况下,正则匹配到的字段,其类型都是 strings,比如 %{NUMBER:bytes},bytes 字段的值默认是 strings,如果想要对其进行类型转换,可以使用格式:%{NUMBER:bytes:int} 或者 %{NUMBER:bytes:float},目前仅支持转换为 int 或者 float 类型 [5]
Grok 提供了很多 常用的以命名的正则表达式,可以在 Grok 中直接使用。其中最基础的正则表达式在 grok-patterns 中
Grok 常用命名正则表达式
%{IP:client_ip}%{HTTPDATE:timestamp}- 匹配时间格式04/Jan/2015:05:30:37 +0000,如[04/Jan/2015:05:30:37 +0000]使用\[%{HTTPDATE:timestamp}\]进行匹配%{WORD:http_method}- 匹配单词(两边以空格分割)%{URIPATHPARAM:request}- 匹配 URI 路径和参数(不包括 schema 和 domain),如/style2.css%{NUMBER:http_version}- 匹配数值,如 HTTP 版本(HTTP/1.1)可以使用HTTP/%{NUMBER:http_version}来匹配%{URI:referrer}- 匹配 URI (包括 schema 和 domain),如http://www.semicomplete.com/projects/xdotool/%{DATA:message}- 匹配其他所有数据
在使用正则表达式之前,建议使用 Grok 调试器 调试,确保表达式没问题。如下图表示正则表达式存在问题。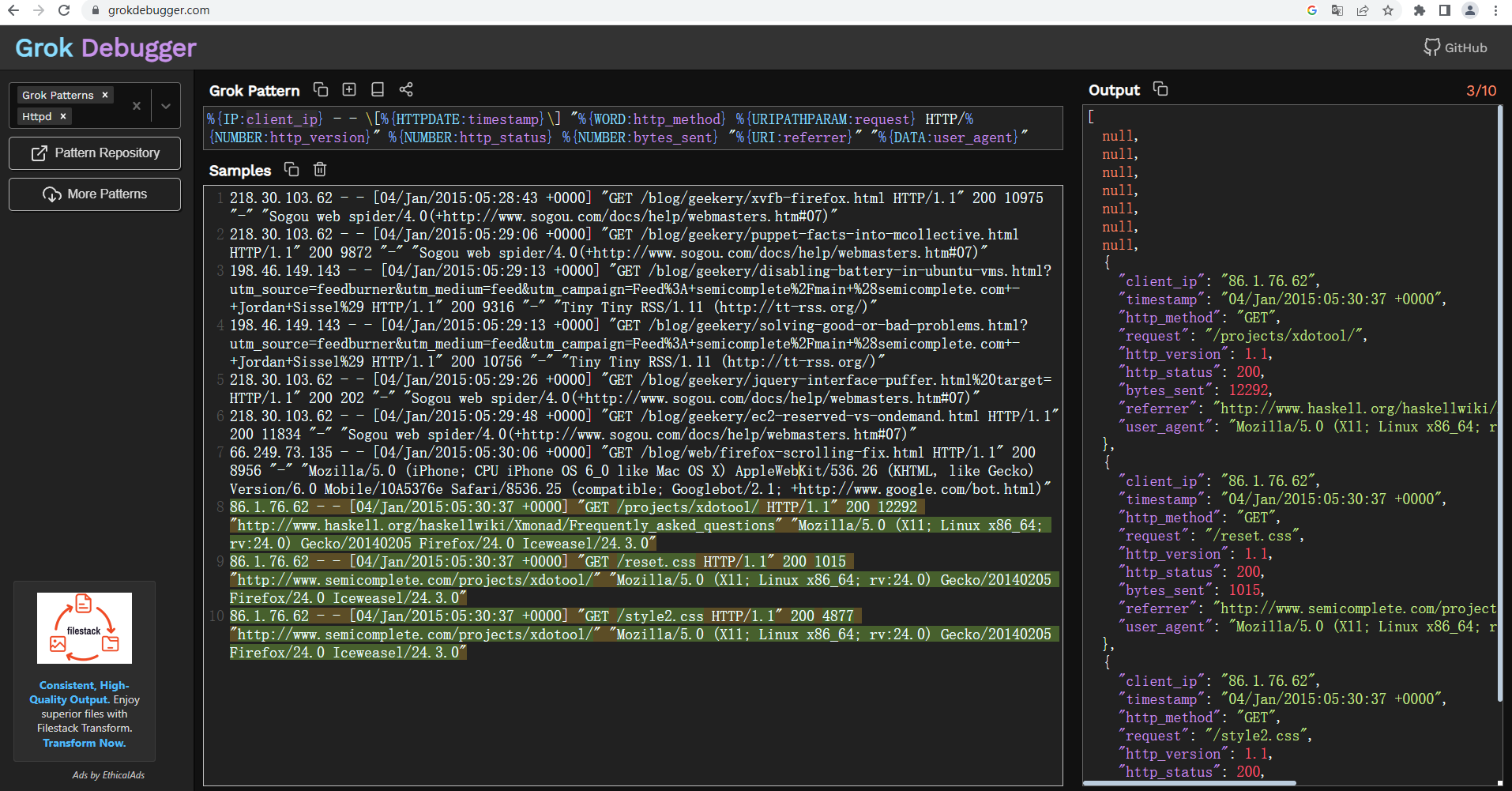
多字段匹配
如果需要在 Grok 中执行多个字段的匹配,可以参考以下格式,在 match 中使用多个条目
filter { |
如果一个正则表达式中使用的字段依赖于之前的正则表达式,必须将其放置在 2 个不同的 Grok 块中
filter { |
overwrite 选项
数据进入 Grok 格式化后,原始数据默认会保留,此时保留了原始数据和格式化后的数据,如果不想保留原始数据,可以使用 overwrite 选项覆盖原始数据
filter { |
geoip
geoip 插件可以将 IP 转换为地理位置并添加到数据中。geo 插件默认启用
geoip 需要指定包含要转换成地理位置信息的 IP 字段。Logstash 的 Filter 是顺序执行的,后一个 filter 可以使用前一个 filter 格式化后的字段,反之不行。
input { |
常见错误
No configuration found in the configured sources
logstash 服务启动后端口(默认 5044)未监听,检查服务日志(默认/var/log/logstash/logstash-plain.log),日志中报错:
[ERROR][logstash.config.sourceloader] No configuration found in the configured sources. |
其中关键报错信息 No configuration found in the configured sources,表示 没有找到任何一个可用的 pipline 配置
logstash 服务默认的配置文件为 /etc/logstash/logstash.yml,Pipeline 配置文件入口为 /etc/logstash/pipelines.yml。检查 Pipeline 配置文件可知,默认情况下,其加载符合 /etc/logstash/conf.d/*.conf 的配置文件,检查 /etc/logstash/conf.d/,没有 .conf 的 Pipeline 配置文件
cat pipelines.yml |
创建 Pipeline 配置文件 /etc/logstash/conf.d/test.conf,重启 logstash 服务后,服务及端口都正常
cat /etc/logstash/conf.d/test.conf |