环境信息
- Prometheus 2.44.0
- Grafana 9.5.2
- Kubernetes 1.24
Kubernetes
CPU
Grafana 中获取所有 node 的 CPU 使用率
以下示例中,$node 为在 Grafana 的 Dashboard 中配置的 Variables,其值为 Kubernetes 的节点主机名。$interval 为在 Grafana 的 Dashboard 中配置的 Variables,其值表示 Prometheus 的查询时间范围变量。
100 - avg(rate(node_cpu_seconds_total{mode="idle",kubernetes_io_hostname=~"$node"}[$interval])) * 100
|
Memory
Grafana 中获取所有 node 的 Memory 使用率
100 - (sum(node_memory_MemFree_bytes{kubernetes_io_hostname=~"$node"}) + sum(node_memory_Cached_bytes{kubernetes_io_hostname=~"$node"}) + sum(node_memory_Buffers_bytes{kubernetes_io_hostname=~"$node"})) / sum(node_memory_MemTotal_bytes{kubernetes_io_hostname=~"$node"}) * 100
|
Disk
Grafana 中获取所有 node 的 Disk 使用率
100 - (sum(node_filesystem_avail_bytes{kubernetes_io_hostname=~"$node"}) / sum(node_filesystem_size_bytes{kubernetes_io_hostname=~"$node"})) * 100
|
Network
统计节点物理网卡的流入流出流量
irate(node_network_receive_bytes_total{device!~"cni0|docker.*|flannel.*|veth.*|virbr.*|lo",kubernetes_io_hostname=~"$node"}[$prometheusTimeInterval])
irate(node_network_transmit_bytes_total{device!~"cni0|docker.*|flannel.*|veth.*|virbr.*|lo",kubernetes_io_hostname=~"$node"}[$prometheusTimeInterval])
|
Pod
计算集群中可以使用的 Pod 的数量
相关指标参考说明
100 - sum(kubelet_running_pods{kubernetes_io_hostname=~"$node"}) / sum(kube_node_status_capacity{resource="pods",node=~"$node"}) * 100
|
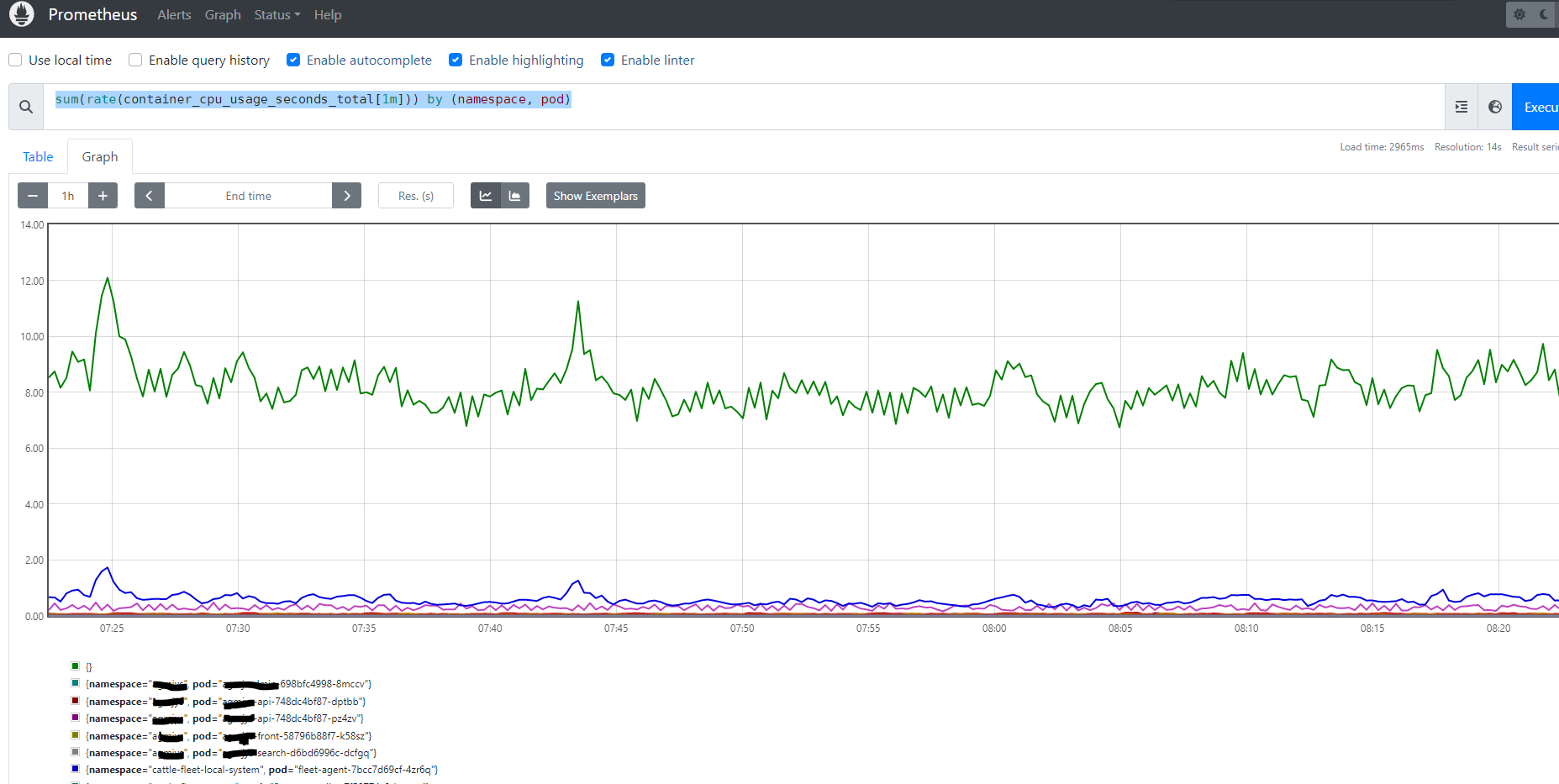
按照 namespace 及 Pod 统计 Pod CPU 使用率
sum(rate(container_cpu_usage_seconds_total[1m])) by (namespace, pod)
|
统计 Pod 使用的内存
container_memory_usage_bytes
|
统计 Pods 的流量
irate(container_network_receive_bytes_total{namespace=~"$k8sNamespace",interface="eth0",kubernetes_io_hostname=~"$node"}[$prometheusTimeInterval])
|
统计 Pods 的重启次数
sum(kube_pod_container_status_restarts_total{namespace=~"$k8sNamespace"}) by (namespace,container)
|