Prometheus 安装配置
环境信息
- Centos 7
- Prometheus Server 2.4
- Node Exporter v1.4.0
- Grafana v9.2.5
安装
在 Docker 中安装 Prometheus Server
创建 Prometheus Server 配置文件,如 /root/prometheus/prometheus.yml,内容如下 [1]
my global config |
使用 Docker 启动时挂载此文件,作为 Prometheus Server 的配置文件,之后需要修改配置,可以直接修改此文件。
docker run -d -p 9090:9090 \ |
启动后,可以通过 $Prometheus_IP:9090 访问 Prometheus Server UI
prometheus 启动参数
prometheus 进程启动时常用选项说明如下。Prometheus 启动是使用的选项可以在 Prometheus UI 中查看 Status -> Command-Line Flags
| 选项 | 说明 | 示例 |
|---|---|---|
--config.file=/etc/prometheus/prometheus.yml |
指定主配置文件路径,默认为 /etc/prometheus/prometheus.yml |
|
--storage.tsdb.retention.time=12h |
数据保留在磁盘上的时常 | |
--storage.tsdb.path=/prometheus/ |
TSDB 数据的存储路径 默认 /prometheus/ |
|
--web.enable-lifecycle |
开启 Prometheus 支持配置变更后的热更新 通过 curl -X POST "localhost:9090/-/reload" 执行热更新,可以减少 Prometheus 重启的时间 |
使用 docker compose 配置 Prometheus
如果要使用 docker compose 配置启动 Prometheus,可以参考以下 docker-compose.yml 文件
version: "3" |
安装 Node Exporter
Node Exporter 同样采用 Golang 编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。获取最新的 node exporter 版本的二进制包。[2]
wget https://github.com/prometheus/node_exporter/releases/download/v1.4.0/node_exporter-1.4.0.linux-amd64.tar.gz |
运行 Node Exporter
node_exporter |
启动成功后,可以看到以下输出:
INFO[0000] Listening on :9100 source="node_exporter.go:76" |
访问 http://localhost:9100/metrics,可以看到当前 node exporter 获取到的当前主机的所有监控数据,如下所示:
配置 Prometheus Server 从 Node Exporter 收集数据
为了能够让 Prometheus Server 能够从当前 node exporter 获取到监控数据,需要修改 Prometheus Server 配置文件。编辑 prometheus.yml 并在 scrape_configs 节点下添加以下内容 : [3]
scrape_configs: |
重启 Prometheus Server
docker restart prometheus |
配置 Grafana 可视化 Prometheus 监控数据
启动 Grafana [4]
docker run --name grafana -d -p 3000:3000 grafana/grafana |
默认情况下使用账户 admin/admin 进行登录
添加 DATA SOURCES
这里将添加 Prometheus 作为默认的数据源,如下图所示,指定数据源类型为 Prometheus 并且设置 Prometheus 的访问地址即可,在配置正确的情况下点击 Add 按钮,会提示连接成功的信息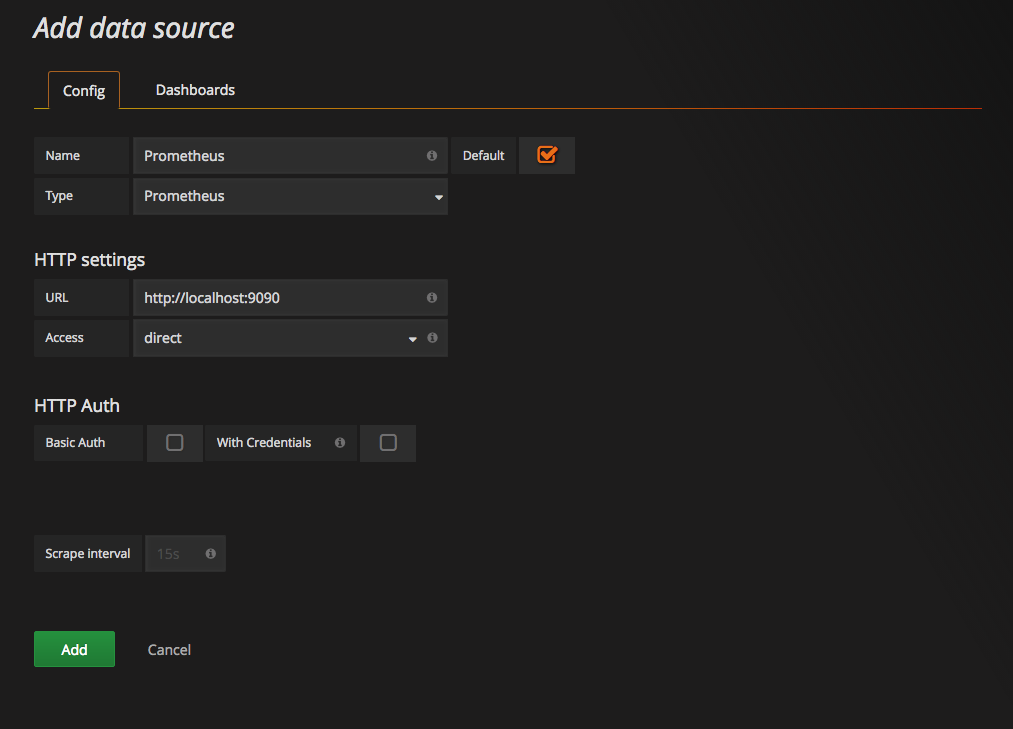
PromQL
可以通过 Prometheus 提供的 UI 来调试表达式及对应的图形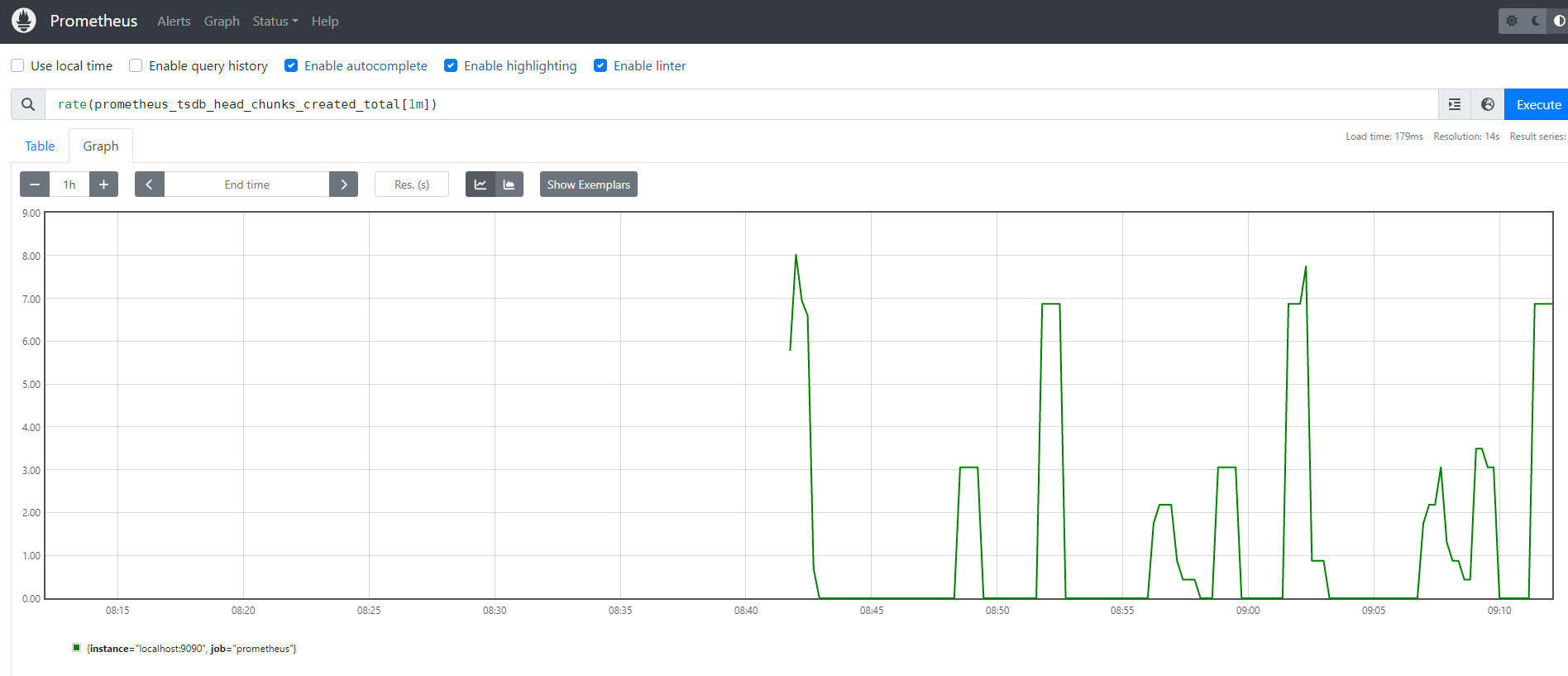
标签
当 Prometheus 从目标采集数据指标时,它会自动在采集到的时间序列上附加一些标签,以便于识别被采集的目标: [5]
job: 采集数据目标所属的已配置的作业名称。instance: 采集数据目标 URL 的<host>:<port>部分。
例如对 up 这个时间序列,可以根据标签筛选出不同值 up{job="<job-name>", instance="<instance-id>"}
其中以
__作为前缀的标签,是系统保留的关键字,只能在系统内部使用。在 Prometheus 的底层实现中指标名称实际上是以__name__=<metric name>的形式保存在数据库中的,因此以下两种方式均表示的同一条time-series:
等同于
本质上,时间序列所对应的监控指标(metric)都是通过
labelset唯一命名的。
标签表达式算符
标签匹配操作符如下所示:
=选择与提供的字符串完全相同的标签(精确匹配)!=选择不等于提供的字符串的标签(反向匹配)=~选择与提供的字符串进行正则表达式匹配的标签(正则表达式匹配)!~选择正则表达式不匹配提供的字符串的标签(反向正则表达式匹配)
范围向量选择器
- 瞬时向量 - 直接通过类似于 PromQL 表达式
api_http_requests_total查询时间序列时,返回结果中只包含该时间序列中各指标最新的样本值,这种类型的数据集称之为 瞬时向量,对应的表达式称为 瞬时向量表达式 - 区间向量 / 范围向量 - 在 瞬时向量 基础上指定时间范围,例如
api_http_requests_total[5m],表达式被称为 区间向量表达式 或者 范围向量表达式,其查询到的时间序列是以当前 瞬时向量 为基准的过去 5 分钟内的时间序列的集合,其结果称之为 区间向量
范围向量 从当前瞬间选择了一定范围的样本 [6]
语法上,将范围持续时间附加在向量选择器末尾的方括号([])中,以指定为每个范围向量元素提取多久的时间值。
持续时间指定为数字,紧随其后的是以下单位之一:
s- 秒m- 分钟h- 小时d- 天w- 周y- 年
在此示例中,我们选择在过去 5 分钟,数据指标名称为 http_requests_total 且 job 标签为 prometheus 的所有时间序列记录的所有值:
http_requests_total{job="prometheus"}[5m] |
时间位移操作
在 瞬时向量表达式 和 区间向量表达式 中,都是以当前时间为基准。 [6]
http_request_total{} # 瞬时向量表达式,选择当前最新的数据 |
如果想查询 5 分钟前的瞬时样本数据,或者昨天一天的区间内的样本数据,这时候可以使用 时间位移操作,关键字为 offset
http_request_total{} offset 5m # 瞬时向量表达式,选择 5 分钟之前的样本数据 |
指标
在形式上,所有的指标 (Metric) 都通过如下格式标示: [7]
<metric name>{<label name>=<label value>, ...} |
Metrics 类型
根据不同监控指标之间的差异,Prometheus 定义了4种不同的指标类型 [8]
Counter- 计数器。只增不减的计数器。一般在定义Counter类型指标的名称时推荐使用_total作为后缀Gauge- 仪表盘。侧重于反应系统的当前状态,可增可减Histogram- 直方图。Summary- 摘要。
prometheus 相关指标
以下列出常见的指标名称及其相关信息
| 指标名称 | 类型 | 说明 | 示例 |
|---|---|---|---|
up |
实例运行状态良好,则为 1; 如果采集失败,则为 0 |
||
scrape_duration_seconds |
采集的持续时间 |
PromQL 语法
当我们直接使用监控指标名称查询时,可以查询该指标下的所有时间序列。如: [9]
http_requests_total |
等同于:
http_requests_total{} |
等同于
{__name__="http_requests_total"} |
该查询会返回指标名称为 http_requests_total 的所有时间序列
http_requests_total{code="200",handler="alerts",instance="localhost:9090",job="prometheus",method="get"}=([email protected]) |
PromQL 内置函数
increase
increase(v range-vector) 函数获取 区间向量 中的第一个和最后一个样本并返回其增长量。其中参数 v 是一个 区间向量 [10]
increase(node_cpu[2m]) / 120 |
这里通过 node_cpu[2m] 获取时间序列最近两分钟的所有样本,increase 计算出最近两分钟的增长量,最后除以时间 120 秒得到 node_cpu 样本在最近两分钟的平均增长率。并且这个值也近似于主机节点最近两分钟内的平均 CPU 使用率。
rate & irate
rate(v range-vector) 函数可以直接计算出 区间向量 v 在时间窗口内的平均增长速率。以下表达式获取和 increase(node_cpu[2m]) / 120 函数相同的效果。
rate(node_cpu[2m]) |
需要注意的是使用 rate 或者 increase 函数去计算样本的平均增长速率,容易陷入“长尾问题”当中,其无法反应在时间窗口内样本数据的突发变化。 例如,对于主机而言在 2 分钟的时间窗口内,可能在某一个由于访问量或者其它问题导致 CPU 占用 100% 的情况,但是通过计算在时间窗口内的平均增长率却无法反应出该问题。
为了解决该问题,PromQL 提供了另外一个灵敏度更高的函数 irate(v range-vector)。irate 同样用于计算区间向量的计算率,但是其反应出的是瞬时增长率。irate 函数是通过区间向量中最后两个样本数据来计算区间向量的增长速率。这种方式可以避免在时间窗口范围内的“长尾问题”,并且体现出更好的灵敏度,通过 irate 函数绘制的图标能够更好的反应样本数据的瞬时变化状态。
irate(node_cpu[2m]) |
irate 函数相比于 rate 函数提供了更高的灵敏度,不过当需要分析长期趋势或者在告警规则中,irate 的这种灵敏度反而容易造成干扰。因此在长期趋势分析或者告警中更推荐使用 rate 函数。
常用 metrics 及 PromQL
CPU
CPU 使用率
主要使用指标 node_cpu_seconds_total,该指标包括多个标签,分别标记了每种处理模式使用的 CPU 时间,该指标为 counter 类型,不适合直接使用,需要使用 PromQL 转换成感兴趣的指标
| 指标名称 | 类型 | 说明 | 示例 |
|---|---|---|---|
node_cpu_seconds_total |
counter |
每种处理模式使用的 CPU 时间 |
以下 PromQL 可以用来计算 CPU 使用率,若对其他模式的 CPU 监控指标感兴趣,可以根据需求自己调整。
100 -avg(irate(node_cpu_seconds_total{job="kubernetes-nodes",mode="idle"}[5m])) by (instance)* 100 |
Memory
Memory 使用率
涉及到的内存指标
| 指标名称 | 类型 | 说明 | 示例 |
|---|---|---|---|
node_memory_MemTotal_bytes |
总内存大小 | ||
node_memory_MemFree_bytes |
空闲内存大小 | ||
node_memory_Buffers_bytes |
缓冲缓存的大小 | ||
node_memory_Cached_bytes |
页面缓存的大小 |
物理内存使用率计算公式如下: (总内存 -(空闲内存 + 缓冲缓存 + 页面缓存))/ 总内存 * 100
(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes+node_memory_Cached_bytes ))/node_memory_MemTotal_bytes * 100 |
Disk
磁盘相关指标,多个分区可以通过 mountpoint 标签区分,device 标签区分所属设备
| 指标名称 | 类型 | 说明 | 示例 |
|---|---|---|---|
node_filesystem_size_bytes |
分区空间总容量 | ||
node_filesystem_free_bytes |
分区空间空闲容量 | ||
node_disk_read_bytes_total |
counter |
分区读总字节数 | |
node_disk_written_bytes_total |
counter |
分区写总字节数 | |
node_disk_reads_completed_total |
counter |
分区读总次数 | |
node_disk_writes_completed_total |
counter |
分区写总次数 |
获取根分区的磁盘使用率
公式如下
(node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_free_bytes{mountpoint="/"})/node_filesystem_size_bytes{mountpoint="/"} * 100 |
磁盘吞吐率
公式如下
irate(node_disk_read_bytes_total{device="vda"}[5m]) |
磁盘 IOPS
IOPS 表示每秒对磁盘的读写次数,它与吞吐量都是衡量磁盘的重要指标。对于 IOPS 的监控,可通过下面两个指标算得出
irate(node_disk_reads_completed_total{device="vda"}[5m]) |
Network
网卡流量一般分为上传和下载流量
| 指标名称 | 类型 | 说明 | 示例 |
|---|---|---|---|
node_network_receive_bytes_total |
下载(接收/流入)流量总字节数 | ||
node_network_transmit_bytes_total |
上传(/发送/流出)流量总字节数 |
网卡流量
以下公式计算每秒网卡流量
irate(node_network_receive_bytes_total{device != "lo"}[1m] |
Prometheus 告警
PromQL 告警规则
一条典型的告警规则如下所示:
groups: |
在告警规则文件中,我们可以将一组相关的规则设置定义在一个 group 下。在每一个 group 中我们可以定义多个告警规则(rule)。一条告警规则主要由以下几部分组成:
alert:告警规则的名称。expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager。summary- 描述告警的概要信息description- 描述告警的详细信息
为了能够让 Prometheus 启用定义的告警规则,需要在 Prometheus 的全局配置文件 中通过 rule_files 指定 告警规则文件的访问路径。Prometheus 启动后会自动扫描这些路径下规则文件中定义的内容,并且根据这些规则计算是否告警。
global: |
默认情况下 Prometheus 会每分钟对这些告警规则进行计算,如果用户想定义自己的告警计算周期,则可以通过 evaluation_interval 来覆盖默认的计算周期:
global: |
在 annotations 的 summary 和 description 可以使用变量访问当前告警实例当中指定标签和对应的值
$labels.<labelname>- 访问名为<labelname>的label$value- 访问标签$labels.<labelname>的值
groups: |
配置生效后,可以在 Prometheus 的 Web 的 Status --> Rules 下看到所有的告警规则,也可以在 Alerts 中看到所有的告警规则及其状态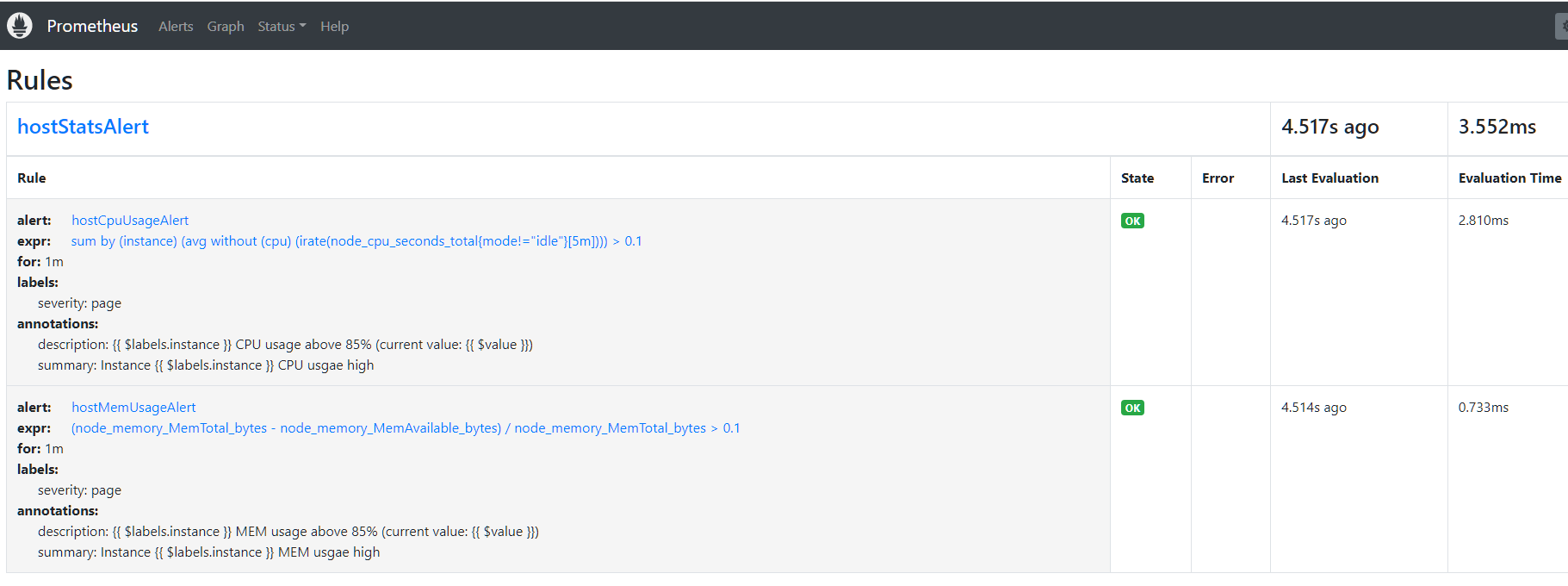
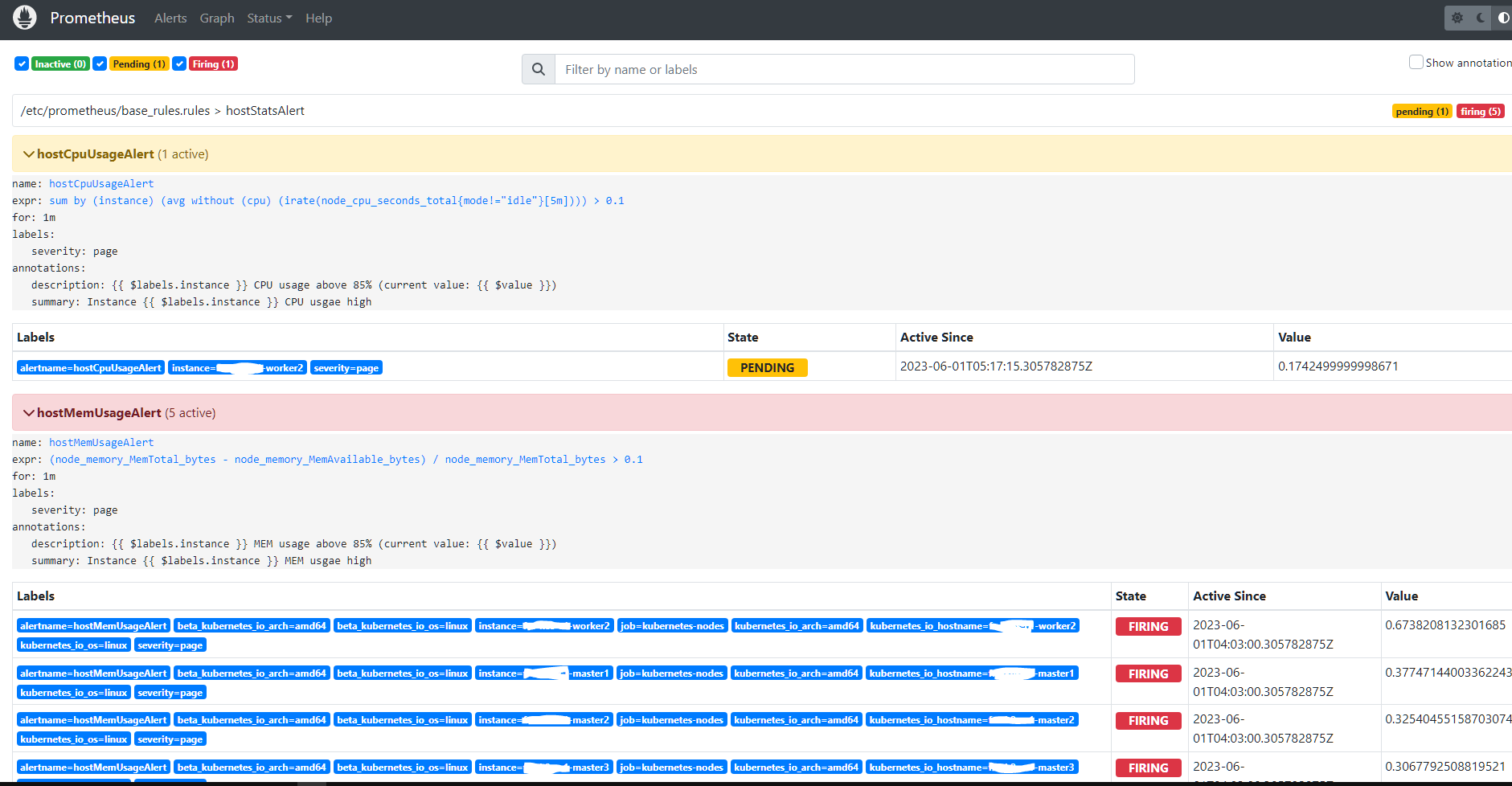
Prometheus 首次检测到满足条件的样本后,告警就会处于活动状态,由于配置了 for 等待时间,告警状态是(PENDING),如果到了 for 等待时间,告警条件持续满足,则会实际触发告警并且告警状态为 FIRING
Prometheus 配置文件说明
Prometheus 配置文件内容大体如下,主要分为:
global- 全局配置选项alerting- 告警管理的配置选项rule_files- 高级规则文件的路径scrape_configs- 要抓取的目标和抓取配置
global: |
global 常用选项说明
scrape_interval- 指定抓取间隔,即 Prometheus 定期抓取指标数据的时间间隔。默认值为15秒(15s)。scrape_timeout- 指定抓取超时时间,即在超过此时间后如果抓取请求未完成,则认为抓取失败。默认值为10秒(10s)。evaluation_interval- 指定评估间隔,即 Prometheus 对规则和表达式进行计算和评估的时间间隔。默认值为1分钟(1m)。external_labels- 指定用于所有指标时间序列的额外标签。这些标签可以在查询和告警规则中使用,以提供额外的上下文信息。例如:external_labels:
environment: 'production'
region: 'us-west'这将在所有指标的时间序列中添加
environment=production和region=us-west的标签。在 Prometheus UI 中查看,不会有这些标签存在,但是通过如 Prometheus Federation 架构中的中心 Prometheus 采集后的指标中会有这些标签,方便删选聚合
alerting 常用选项说明
以下配置指定 AlertManager 的配置,以使 Prometheus 可以发送告警。
alerting: |
rule_files 常用选项说明
scrape_configs 常用选项说明
每个scrape_config 块包含以下选项
job_name- 抓取任务的名称static_configs- 静态目标配置,可以包含一个或多个目标的配置relabel_configs- 对目标标签进行重新标记或者重写metrics_path- 目标的指标抓取路径params- 为抓取指标的请求提供额外的参数(键值对)scheme- 抓取请求使用的协议,http或httpsscrape_interval- 抓取该目标的间隔时间。可以覆盖全局配置。scrape_timeout- 抓取超时时间。honor_labels-true|false,指定是否要保留来自抓取目标的指标的标签。默认值为false当
honor_labels设置为true时,Prometheus 将尊重被抓取目标提供的标签,并将其视为指标标签的一部分。这意味着来自同一指标名称但带有不同标签值的多个时间序列将被保留和区分。例如,如果抓取目标提供一个名为
cpu_usage的指标,并在不同的 Pod 之间使用pod_name标签进行区分,那么 Prometheus 会存储多个时间序列,每个时间序列代表一个不同的 Pod 的 CPU 使用情况。通过保留标签,你可以根据 Pod 名称对这些时间序列进行过滤、聚合和查询。然而,当
honor_labels设置为false时,Prometheus 将忽略来自被抓取目标的标签,并且不会将其包含在存储的指标数据中。在这种情况下,相同指标名称的所有时间序列将被视为相同,并且标签信息将丢失。通常情况下,如果你希望保留和使用被抓取目标提供的标签信息,你应该将
honor_labels设置为true,以便在 Prometheus 中进行更灵活和细粒度的指标查询和操作。honor_labels选项仅适用于service_discovery和static_configs中的目标。对于其他类型的目标,例如relabel_configs或file_sd_configs,honor_labels并不适用。
scrape_configs: |
| 参数 | 说明 | 示例 |
|---|---|---|
labels |
配置自定义标签,会附加到指标的标签中 |
relabel_configs 详解
relabel 重定义标签是在拉取(Scrape)阶段钱,修改 Target 和 Lables。
默认情况下,Target 会自动被添加以下标签
job- 设置为配置中job_name的值__address__- 设置为配置中targets的值instance- 是重定义标签__address__的值__scheme__- 设置为配置中 协议类型 的值,从配置中读取__metrics_path__- 从配置中读取,拉取 Metrics 的 uri
action
action 定义了对标签的动作,主要有以下可选项,默认值为 replace
| action | 说明 | 示例 |
|---|---|---|
replace |
使用正则匹配到的源标签的值来替换目标标签的值,如果有 replacement,则直接使用 replacement 的值替换目标标签 |
|
keep |
如果正则没有匹配到源标签,则删除 Targets | |
drop |
如果正则匹配到源标签,则删除 Targets | |
hashmod |
设置 目标标签的值为 源标签值的 hash 值 | |
labelmap |
正则匹配所有标签名,使用匹配到的标签名 和 原标签名的值 生成新的标签 |
Prometheus 多配置文件实现
在 Prometheus 的 Targets 数量太多的情况下,将所有的配置写在一个文件中,会显得特别累赘也不好管理。最好是将配置文件分割成多个小配置文件。本示例使用 Prometheus 的 file_sd_config 方式实现配置文件的分割。
file_sd_config 实现配置文件分割
本示例按照统计数据采集客户端(如 node_exporter、nginx_vts_exporter 等)的不同,将配置分割到不同的子配置文件目录中。
配置文件目录结构如下:
/etc/prometheus/ |
Prometheus 主配置文件中 file_sd_config 相关配置如下:
- job_name: 'node_exporter' |
在
file_sd_configs中使用参数refresh_interval可以配置重载子配置文件的周期,这样更新子配置文件后,无需重启 prometheus 服务即可自动加载新配置
子配置文件内容如下:
- targets: ['IP1:9100', 'IP2:9100'] |
- targets: ['IP1:8899', 'IP2:8899'] |
子配置文件中只配置 Targets 配置,如果需要其他上级配置(如
job_name、metrics_path等)则需在主配置文件(prometheus.yml)中配置。
Prometheus 优化建议
Prometheus 随着收集的指标数量的增加,对 CPU 和内存的要求也会上周,一般首先使用率变高的是内存。
- Prometheus 每隔 2 小时做一个 Block 数据落盘,落盘之前所以的数据都在 内存 中。采集量越多,占用内存越大。
- 加载历史数据时,是从磁盘读取到内存,因此查询范围越大,内存占用越大
为了减小 Prometheus Server 的压力,可以采取以下方法
- 进行指标优化,去除无效的 Metrics 采集
在 Prometheus UI 的 Status 中,有TSDB Status,里面包含了 Prometheus 的统计概要