kubernetes 安装配置
环境信息
- Centos 7 5.4.212-1
- Docker 20.10.18
- containerd.io-1.6.8
- kubectl-1.24.7
- kubeadm-1.24.7
- kubelet-1.24.7
kubernetes 环境安装前配置
升级内核版本
Centos 7 默认的内核版本 3.10 在运行 kubernetes 时存在不稳定性,建议升级内核版本到新版本
Linux 升级内核
Centos 7 默认的内核版本 3.10 使用的 cgroup 版本为 v1,Kubernetes 的部分功能必须使用
cgroup v2来进行增强的资源管理和隔离 [13]使用以下命令检查系统使用的
cgroup版本
如果输出是
cgroup2fs, 表示使用 cgroup v2如果输出是
tmpfs, 表示使用 cgroup v1
User Namespaces功能需要 Linux 6.3 以上版本,tmpfs才能支持idmap挂载。并且其他功能(如 ServiceAccount 的挂载)也需要此功能的支持 [14]Kubernetes v1.32 需要 Linux Kernel >= 4.19, 建议 5.8+ 以更好的支持 cgroups v2
Rocky Linux 8 或者 Centos 8 默认使用
cgroup v1,需要升级到cgroup v2,执行命令grubby --update-kernel=ALL --args="systemd.unified_cgroup_hierarchy=1"后重启即可升级到cgroup v2。 使用以下命令检查:
cgroup2fs若 CRI 使用 Containerd,需要 配置启用 CRI 以及配置其使用
cgroup v2。
关闭 SELinux
kubernetes 目前未实现对 SELinux 的支持,因此必须要关闭 SELinux
sudo setenforce 0 |
集群中所有计算机之间具有完全的网络连接
配置集群所有节点的防火墙,确保所有集群节点之间具有完全的网络连接。
- 放通节点之间的通信
- 确保防火墙允许
FORWARD链的流量/etc/sysconfig/iptables *filter
:INPUT DROP [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [4:368]
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
-A INPUT -i lo -j ACCEPT
kubernetes nodes
-A INPUT -m comment --comment "kubernetes nodes" -s 172.31.5.58 -j ACCEPT
-A INPUT -m comment --comment "kubernetes nodes" -s 172.31.5.68 -j ACCEPT
-A INPUT -m comment --comment "kubernetes nodes" -s 172.31.0.230 -j ACCEPT
-A INPUT -p tcp -m multiport --dports 80,443 -j ACCEPT -m comment --comment "k8s ingress http,https"
...
-A INPUT -p icmp -m icmp --icmp-type 8 -j ACCEPT
-A INPUT -p icmp -m icmp --icmp-type 0 -j ACCEPT
-A INPUT -j REJECT --reject-with icmp-host-prohibited
COMMIT
集群通信 ( iptables ) 矩阵说明: [6]
| Protocol | iptables table | ipables chain | Port Range | Purpose | Used by |
|---|---|---|---|---|---|
| UDP | filter | INPUT | 8472 | flannel | network |
| TCP | filter | INPUT | 6443 | Kubernetes API server | ALL node |
| TCP | filter | INPUT | 2379-2380 | etcd server client API | kube-apiserver,etcd |
| TCP | filter | INPUT | 10250 | kubelet API | Control plane, Self ,kubectl exec |
| TCP | filter | INPUT | 10251 | kube-scheduler | self |
| TCP | filter | INPUT | 10252 | kube-controller-manager | self |
| TCP | filter | INPUT | 30000-32767 | NodePortService | All |
- 不同节点之间的
Pod通信需要经过flannel的8472/udp nodePort类型的service,默认可用的nodePort端口范围为30000-32767,根据实际情况配置
若对网络安全要求较为严格,可在 master 节点使用以下防火墙规则,本示例中 CNI 对接的网络插件为 flannel,若使用其他网络插件,则根据插件要求放通对应端口。
本示例中 192.168.142.8 - 10 为 master 节点,192.168.142.11 - 12 为 worker 节点
*filter |
在 node 节点使用以下防火墙规则
*filter |
禁止swap分区
以下命令临时关闭 swap,要永久关闭 swap,修改配置文件 /etc/fstab,删除或注释其中 swap 相关的行。
swapoff -a |
配置主机名
节点之中不可以有重复的主机名、MAC 地址或 product_uuid
配置集群中的 3 台主机名分别为 kubernetes1,kubernetes2,kubernetes3,本示例中 kubernetes1 作为 master
hostnamectl set-hostname kubernetes1 |
添加主机名和 ip 解析到 /etc/hosts 文件
172.31.10.19 kubernetes1 |
为 kube-proxy 开启 ipvs
kube-proxy 模式对比:iptables 还是 IPVS
此配置为可选操作,在不启用 ipvs 模式的情况下,kube-proxy 会使用 iptables 模式
cat > /etc/sysconfig/modules/ipvs.modules <<EOF |
转发 IPv4 并让 iptables 看到桥接流量
以下操作需要在 kubernetes 集群中的所有节点操作
通过运行 lsmod | grep br_netfilter 来验证 br_netfilter 模块是否已加载。Kubernetes 通过 bridge-netfilter 配置使 iptables 规则可以应用在 Linux Bridge 上,对 Linux 内核进行宿主机和容器之间的数据包的地址转换是必须的,否则 Pod 进行外部服务网络请求时会出现目标主机不可达或者连接拒绝等错误(host unreachable 或者 connection refused)
lsmod | grep br_netfilter |
若要显式加载此模块,请运行以下命令
sudo modprobe overlay |
为了让 Linux 节点的 iptables 能够正确查看桥接流量,请确认 sysctl 配置中的 net.bridge.bridge-nf-call-iptables 设置为 1
为配置永久生效,可以添加以下配置,/etc/modules-load.d/k8s.conf 中追加要加载的模块
overlay |
/etc/sysctl.d/k8s.conf 中追加内核参数
net.bridge.bridge-nf-call-iptables = 1 |
执行以下命令重新载入 sysctl 参数而无需重启系统
sudo sysctl --system |
安装 Docker Engine
以下操作需要在 kubernetes 集群中的所有节点操作
参考以下链接,在每个节点上安装 Docker Engine
Centos 安装 Docker Engine 官网参考文档
安装 cri-dockerd
Docker Engine 没有实现 CRI,因此 Kubernetes 无法直接使用 Docker Engine,需要先安装 cri-dockerd,以让 Kubernetes 可以通过 Kubernetes 的 CRI 操作 Docker。
以下操作需要在 kubernetes 集群中的所有节点操作
按照源代码仓库中的说明安装 cri-dockerd
git clone https://github.com/Mirantis/cri-dockerd.git |
对于 cri-dockerd,默认情况下,CRI 套接字是 /run/cri-dockerd.sock
Kubernetes 安装配置
安装 kubeadm、kubelet 和 kubectl
需要在每台机器上安装以下的软件包:
kubeadm: 用来初始化集群的指令。kubelet: 在集群中的每个节点上用来启动 Pod 和容器等。kubectl: 用来与集群通信的命令行工具。
添加 yum 源
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo |
安装软件包
sudo yum install -y kubelet-1.24.7 kubeadm-1.24.7 kubectl-1.24.7 --disableexcludes=kubernetes |
启动服务并配置开机启动
sudo systemctl enable --now kubelet |
kubelet 现在每隔几秒就会重启,因为它陷入了一个等待 kubeadm 指令的死循环。
systemctl status kubelet |
初始化控制平面节点
创建单控制平面集群
控制平面节点是运行控制平面组件的机器, 包括 etcd (集群数据库) 和 API Server (命令行工具 kubectl 与之通信)。
初始化控制平面节点
要初始化控制平面节点,请在 master 节点上(
kubernetes1)运行以下命令,命令参数说明:kubernetes1 kubeadm init --pod-network-cidr=10.244.0.0/16 --cri-socket=unix:///var/run/cri-dockerd.sock
--pod-network-cidr=10.244.0.0/16指定 pod 使用的网络段,后面配置网络(CNI)时配置的网段要和此处一致--cri-socket=unix:///var/run/cri-dockerd.sock指定使用的 CRI 为 Docker
使用
kubeadm init --config=./kubeadm-config.yml的情况下,对应配置文件中内容示例:kubeadm-config.yml apiVersion: kubeadm.k8s.io/v1beta2
kind: ClusterConfiguration
kubernetesVersion: stable
controlPlaneEndpoint: "192.168.254.106:6443"
networking:
podSubnet: "10.244.0.0/16"
---
apiVersion: kubeadm.k8s.io/v1beta2
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: "192.168.254.106"
nodeRegistration:
criSocket: /var/run/containerd/containerd.sock输出结果如下:
[init] Using Kubernetes version: v1.25.0
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local kubernetes1] and IPs [10.96.0.1 172.31.10.19]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [localhost kubernetes1] and IPs [172.31.10.19 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [localhost kubernetes1] and IPs [172.31.10.19 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 17.003297 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node kubernetes1 as control-plane by adding the labels: [node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node kubernetes1 as control-plane by adding the taints [node-role.kubernetes.io/control-plane:NoSchedule]
[bootstrap-token] Using token: 8ca35s.butdpihinkdczvqb
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] Configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] Configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] Configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
beadm join 172.31.10.19:6443 --token 8ca35s.butdpihinkdczvqb \
--discovery-token-ca-cert-hash sha256:b2793f9a6bea44a64640f99042f11c4ff6e4fef99fa2407241e1a0e8ea652149根据
kubeadm init输出提示,配置kubectl需要的环境变量,root 用户执行以下命令
export KUBECONFIG=/etc/kubernetes/admin.conf
为永久生效,可将其添加到~/.bash_profile此时,执行以下命令查看集群节点信息
kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-565d847f94-dc8tl 0/1 Pending 0 5m42s
kube-system coredns-565d847f94-zqctg 0/1 Pending 0 5m42s
kube-system etcd-kubernetes1 1/1 Running 0 5m54s
kube-system kube-apiserver-kubernetes1 1/1 Running 0 5m53s
kube-system kube-controller-manager-kubernetes1 1/1 Running 0 5m54s
kube-system kube-proxy-6kwdx 1/1 Running 0 5m43s
kube-system kube-scheduler-kubernetes1 1/1 Running 0 5m54s
其中,coredns的 pod 处于Pending状态,是因为网络还没配置。因为 CRI 使用 docker,此时使用以下命令,可以查看到启动的所有容器
docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
741a6d32b2cd 58a9a0c6d96f "/usr/local/bin/kube…" 5 minutes ago Up 5 minutes k8s_kube-proxy_kube-proxy-6kwdx_kube-system_93101b10-7ee5-437c-a234-3e31edc7cfa9_0
31509b3f06cc k8s.gcr.io/pause:3.6 "/pause" 5 minutes ago Up 5 minutes k8s_POD_kube-proxy-6kwdx_kube-system_93101b10-7ee5-437c-a234-3e31edc7cfa9_0
fb3ec15950b6 bef2cf311509 "kube-scheduler --au…" 6 minutes ago Up 6 minutes k8s_kube-scheduler_kube-scheduler-kubernetes1_kube-system_c455960b65afeadd009ff9ba9e7ab7b0_0
333188677c01 4d2edfd10d3e "kube-apiserver --ad…" 6 minutes ago Up 6 minutes k8s_kube-apiserver_kube-apiserver-kubernetes1_kube-system_11596873d958a699a1b923df2333eaad_0
4bdbf8689bbb 1a54c86c03a6 "kube-controller-man…" 6 minutes ago Up 6 minutes k8s_kube-controller-manager_kube-controller-manager-kubernetes1_kube-system_23ce2f60ac97b06bde25c1662e88e409_0
a399d3484c17 a8a176a5d5d6 "etcd --advertise-cl…" 6 minutes ago Up 6 minutes k8s_etcd_etcd-kubernetes1_kube-system_84da44e552601c02573afe1dc1e3b0a2_0
28aae0e41a7d k8s.gcr.io/pause:3.6 "/pause" 6 minutes ago Up 6 minutes k8s_POD_kube-apiserver-kubernetes1_kube-system_11596873d958a699a1b923df2333eaad_0
3f4f378ed731 k8s.gcr.io/pause:3.6 "/pause" 6 minutes ago Up 6 minutes k8s_POD_kube-scheduler-kubernetes1_kube-system_c455960b65afeadd009ff9ba9e7ab7b0_0
eaa6d312a174 k8s.gcr.io/pause:3.6 "/pause" 6 minutes ago Up 6 minutes k8s_POD_etcd-kubernetes1_kube-system_84da44e552601c02573afe1dc1e3b0a2_0
707e84291ac2 k8s.gcr.io/pause:3.6 "/pause" 6 minutes ago Up 6 minutes k8s_POD_kube-controller-manager-kubernetes1_kube-system_23ce2f60ac97b06bde25c1662e88e409_0-
在进行下一步之前,必须选择并部署合适的网络插件。 否则集群不会正常运行。
将节点加入集群
在 work 节点上执行以下命令加入集群
kubeadm join 172.31.10.19:6443 --token 8ca35s.butdpihinkdczvqb --discovery-token-ca-cert-hash sha256:b2793f9a6bea44a64640f99042f11c4ff6 \
--cri-socket=unix:///var/run/cri-dockerd.sock加入集群成功后,在 master 上查看所有节点
kubectl get nodes
NAME STATUS ROLES AGE VERSION
kubernetes1 Ready control-plane 36m v1.25.0
kubernetes2 NotReady <none> 21s v1.25.0
kubernetes3 NotReady <none> 18s v1.25.0
创建高可用控制平面的集群
创建 堆叠(Stacked)etcd 拓扑 的高可用控制平面集群
堆叠(Stacked)etcd 拓扑 主要有以下特点:
etcd分布式数据存储集群堆叠在kubeadm管理的控制平面节点上,作为控制平面的一个组件运行。- 每个控制平面节点运行
etcd、kube-apiserver、kube-scheduler和kube-controller-manager实例。kube-apiserver使用负载均衡器暴露给工作节点。 - 每个控制平面节点创建一个本地
etcd成员(member),这个etcd成员只与该节点的kube-apiserver通信。 这同样适用于本地kube-controller-manager和kube-scheduler实例。 - 堆叠集群存在耦合失败的风险。如果一个节点发生故障,则
etcd成员和控制平面实例都将丢失, 并且冗余会受到影响。你可以通过添加更多控制平面节点来降低此风险。
堆叠(Stacked)etcd 拓扑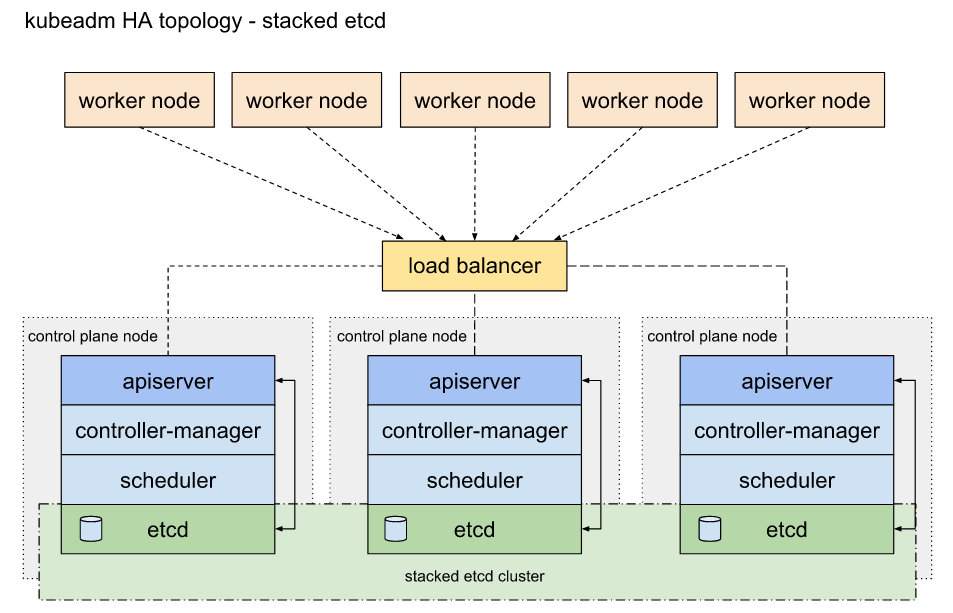
为 kube-apiserver 创建负载均衡器,该负载均衡器将流量分配给目标列表中所有运行状况良好的控制平面节点。 API 服务器的健康检查是在 kube-apiserver 的监听端口(默认值 :6443) 上进行的一个 TCP 检查。 [2]
此处假设 kube-apiserver 的负载均衡地址为 kube-apiserver.my.com:6443。
初始化控制平面:
kubeadm init --pod-network-cidr=10.244.0.0/16 --cri-socket=unix:///var/run/cri-dockerd.sock \
--control-plane-endpoint "kube-apiserver.my.com:6443" \
--upload-certs--upload-certs标志用来将在所有控制平面实例之间的共享证书上传到集群。如果不使用此选项,需要手动拷贝证书到其他节点 [12]根据
kubeadm init输出提示,配置kubectl需要的环境变量,root 用户执行以下命令export KUBECONFIG=/etc/kubernetes/admin.conf
为永久生效,可将其添加到
~/.bash_profile-
在进行下一步之前,必须选择并部署合适的网络插件。 否则集群不会正常运行。
输入以下内容,并查看控制平面组件的 Pod 启动:
kubectl get pod -n kube-system -w
其余控制平面节点上的操作
执行先前由第一个节点上的
kubeadm init输出提供给你的join命令。 在 CRI 是cri-dockerd的场景下,要添加--cri-socket=unix:///var/run/cri-dockerd.sock。它看起来应该像这样:kubeadm join 192.168.0.200:6443 --token 9vr73a.a8uxyaju799qwdjv \
--discovery-token-ca-cert-hash sha256:7c2e69131a36ae2a042a339b33381c6d0d43887e2de83720eff5359e26aec866 \
--control-plane \
--certificate-key f8902e114ef118304e561c3ecd4d0b543adc226b7a07f675f56564185ffe0c07 \
--cri-socket=unix:///var/run/cri-dockerd.sock工作节点上的操作
在工作节点上执行以下命令,添加工作节点到集群中。在 CRI 是
cri-dockerd的场景下,要添加--cri-socket=unix:///var/run/cri-dockerd.sock。它看起来应该像这样:kubeadm join kube-apiserver.uat.148962587001:6443 \
--token 0nf24o.fb98ll5qkhpcxd70 \
--discovery-token-ca-cert-hash sha256:a5d589a3476777df757e38334b035a93811d94e75131e3d9cc1d7efad22fc793 \
--cri-socket=unix:///var/run/cri-dockerd.sock
安装 kube-flannel
Kubernetes 安装时已经安装了网络相关驱动,位于 /opt/cni/bin/flannel,此时只需要根据相关配置文件生成 kube-flannel 的 pod 即可
请在 master 节点上(kubernetes1)运行以下命令创建 kube-flannel 相关 POD
kubectl apply -f https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml |
使用默认的 kube-flannel.yml,默认的 Network 为 10.244.0.0/16,要变更默认网段,更改 kube-flannel.yml 中的以下内容即可:
net-conf.json: | |
此处的网段配置需要和 初始化集群时定义的 pod 网段 保持一致
创建完成 kube-flannel 后,再次查看集群中的 pod 信息,可以看到 coredns 已经处于运行状态
kubectl get pods -A |
安装 dashboard
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.6.1/aio/deploy/recommended.yaml |
修改 recommended.yaml 以下内容
kind: Service |
以上修改主要是新加以下 2 行,配置对外的端口,可用范围为 30000-32767:
type: NodePort |
以下 2 处新增配置 nodeName: kubernetes1,其中 kubernetes1 为 master 节点名称,可以通过 kubectl get nodes 查看
spec: |
以上 2 处修改主要是配置 kubernetes-dashboard 运行在 master 节点上,否则可能运行在其他节点上,会因为网络问题导致 kubernetes-dashboard 无法正常启动,查看日志会报以下错误:
kubectl logs -n kubernetes-dashboard kubernetes-dashboard-66c887f759-5rbbb |
关键日志 : panic: Get "https://10.96.0.1:443/api/v1/namespaces/kubernetes-dashboard/secrets/kubernetes-dashboard-csrf": dial tcp 10.96.0.1:443: connect: no route to host
以上报错也有可能是因为防火墙未放通各个 service 的 CLUSTER-IP 网段导致,可以在防火墙中放通相应网段
kubectl get services -A |
iptables 中放通对应网段
iptables -I INPUT 6 -s 10.0.0.0/8 -j ACCEPT |
使用修改后的配置文件 recommended.yaml 启动 kubernetes-dashboard pod
kubectl apply -f recommended.yaml |
查看 pod
kubectl get pods -A |
kubernetes-dashboard 运行正常后,在防火墙放通 kubernetes-dashboard 对外的端口(30443)
iptables -I INPUT 6 -p tcp --dport 30443 -j ACCEPT |
浏览器通过访问 master 节点的公网 ip 地址和端口(https://ip:30443) ,可以打开 kubernetes-dashboard web 界面
此时要验证 Token。需要首先创建管理员用户,创建以下配置文件,文件命名为 kubernetes-dashboard-adminuser.yaml,参考文档
apiVersion: v1 |
以上配置创建了一个 admin 用户(用户名字随便起),赋予 ClusterRoleBinding 角色权限,关联到 clusert-admin(名称是固定的不能修改)。
根据此配置创建账号
kubectl apply -f kubernetes-dashboard-adminuser.yaml |
获取 Bearer Token
kubectl -n kubernetes-dashboard create token admin |
将生成的 Token 输入浏览器进行验证,验证成功后可以登入 Dashboard
默认的 token 有效期很短,要修改 token 的有限时间,可以在登陆 Dashboard 后,编辑 kubernetes-dashboard 的 Deployment
在 spec:template:spec:containers:args 下新增 - '--token-ttl=2592000'
Kubernetes Dashboard v1.32 部署
当前版本的 Kubernetes Dashboard 只支持使用 Helm 方式部署。参考以下命令安装
Add kubernetes-dashboard repository |
为了从外部登陆 Kubernetes-Dashboard,参考以下内容为其部署 Ingress
apiVersion: networking.k8s.io/v1 |
添加 Annotations:
nginx.ingress.kubernetes.io/backend-protocol: "HTTPS"让 Ingress Nginx Controller 使用 HTTPS 协议请求kubernetes-dashboard-kong-proxy,否则默认以 HTTP 方式请求会失败,因为 Dashboard 未监听 HTTP 端口,会报错:400 The plain HTTP request was sent to HTTPS port
从 WEB 访问需要 Token 认证,可以参考以下步骤创建 Token
查看已有的 ServiceAccount
kubectl -n kubernetes-dashboard get serviceaccount
NAME SECRETS AGE
default 0 5d23h
kubernetes-dashboard-api 0 5d23h
kubernetes-dashboard-kong 0 5d23h
kubernetes-dashboard-metrics-scraper 0 5d23h
kubernetes-dashboard-web 0 5d23h创建名为
admin的 ServiceAccountkubectl -n kubernetes-dashboard create serviceaccount admin
serviceaccount/admin created
kubectl -n kubernetes-dashboard get serviceaccount
NAME SECRETS AGE
admin 0 4s
default 0 5d23h
kubernetes-dashboard-api 0 5d23h
kubernetes-dashboard-kong 0 5d23h
kubernetes-dashboard-metrics-scraper 0 5d23h
kubernetes-dashboard-web 0 5d23h给 ServiceAccount 赋予权限 。默认情况下,ServiceAccount 可能没有足够权限访问 Kubernetes 资源。如果需要管理员权限,可以绑定
cluster-admin角色:kubectl create clusterrolebinding kubernetes-dashboard-admin-binding --clusterrole=cluster-admin --serviceaccount=kubernetes-dashboard:admin
clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard-admin-binding created根据 ServiceAccount 生成 Token 。默认 Token 有效期为 1H,可以使用参数
--duration=8760h创建有效期更长的 Tokenkubectl -n kubernetes-dashboard create token admin --duration=8760h
eyJhbGciOiJSUzI1NiIsImtpZCI6IjhFRkdaazdfN3MtcElJSTVPcEFPS2VsdHBZdmdIcXh0QmlwLUo1T...
安装 Kubernetes Metrics Server
安装 Kubernetes Metrics Server 可以支持使用 kubectl top 命令来查看集群使用的资源情况。 [5]
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml |
部署后为了解决证书问题,可以临时配置不使用安全证书进行通信,修改 metrics-server 的 Deployment,在 metrics-server 启动时添加参数 --kubelet-insecure-tls
spec: |
常见错误
Found multiple CRI endpoints on the host
错误场景 : 执行以下命令将节点加入集群时报错
kubeadm join 172.31.10.19:6443 --token 8ca35s.butdpihinkdczvqb --discovery-token-ca-cert-hash sha256:b2793f9a6bea44a64640f99042 |
报错原因 : 在没有明确指定 Kubernetes 要使用的 CRI 情况下,会自动扫描主机上面安装的 CRI,如果出现多个可用的 CRI,会报错并提示确定使用哪个 CRI。
解决方法 : 使用如下命令,指定要使用的 CRI
kubeadm join 172.31.10.19:6443 --token 8ca35s.butdpihinkdczvqb --discovery-token-ca-cert-hash sha256:b2793f9a6bea44a64640f99042f11c4ff6 \ |
kube-flannel 状态为 CrashLoopBackOff
错误场景 :kube-flannel 一直重启,状态为 CrashLoopBackOff
kubectl get pods --all-namespaces |
排查步骤 :
查看日志
kubectl logs kube-flannel-ds-7q2hp -n kube-flannel |
关键日志: Error registering network: failed to acquire lease: node "kubernetes1" pod cidr not assigned
问题原因 : worker 节点的 flannel 组件无法正常获取 podCIDR 的定义
解决方法 : 编辑控制节点上的配置文件 /etc/kubernetes/manifests/kube-controller-manager.yaml,在 - command 下添加以下内容:
- --allocate-node-cidrs=true |
如果内容已存在的话,更改 cidr 的网段和 kube-flannel.yml 中的 cidr 一致
更改配置后,重启所有节点的 kubelet 服务
systemctl restart kubelet |
重新查看所有 pod 状态
kubectl get pods -A |
master 节点状态为 NotReady
kubectl get nodes |
查看节点详细信息
kubectl describe node k8s-master |
查看 Pod 状态
kubectl get pods -A |
结果显示 kube-flannel 位于 master 上的 Pod 状态异常。
查看 kubelet 日志
journalctl -f -u kubelet |
查看主机名
hostname status |
根据 kubelet 日志,Kubenetes 节点名称和主机名不一致。修改节点主机名。
集群之外的服务器使用 kubectl 报错
问题场景:
将集群的管理配置文件 (/etc/kubernetes/admin.conf) 拷贝到集群之外的服务器,并命名为指定文件 ~/.kube/config,修改 ~/.kube/config 中 server 的 IP 为 Kubernetes API Server 的实际 IP,使用 kubectl 命令时,报错 Unable to connect to the server: x509: certificate is valid for 10.96.0.1, 10.150.0.21, not 。
问题原因:
报错表示,当使用安全端口 6443 访问 Kubernetes API Server 时,默认证书中的 DNS 包含了 API Server 服务的 CLUSTER-IP 和 服务器的 IP ,如果是云主机,则为云服务器的私有 IP,不包含其公网 IP,如果使用公网 IP 访问 6443 端口,会报此错误
通过以下命令,可以看到默认的 API Server 的 HTTPS 证书中包含的 DNS
cd /etc/kubernetes/pki |
解决方法:
使用
kubectl的命令行选项--insecure-skip-tls-verify可跳过证书验证。kubectl get nodes
Unable to connect to the server: x509: certificate is valid for 10.96.0.1, 10.150.0.21, not 34.150.1.1
kubectl get nodes --insecure-skip-tls-verify
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane,master 6d5h v1.21.2
k8s-work1 Ready <none> 6d5h v1.21.2
k8s-work2 Ready <none> 6d5h v1.21.2修改
~/.kube/config中server地址为证书中包含的 DNS 名称,如k8s-master,并确保域名本地可解析grep server .kube/config
server: https://k8s-master:6443
kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane,master 6d6h v1.21.2
k8s-work1 Ready <none> 6d6h v1.21.2
k8s-work2 Ready <none> 6d6h v1.21.2重新生成 API Server 证书
备份当前证书,并删除
apiserver.crt和apiserver.keycd /etc/kubernetes/pki
mkdir /data/k8s/backup/pki
mv apiserver.* /data/k8s/backup/pki/生成新的 API Server 证书,默认 SAN 包括
[节点名称 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1],如果不在此列表中的域名或者 IP 需要添加。kubeadm init phase certs apiserver \
--apiserver-advertise-address 10.150.0.21 \
--apiserver-cert-extra-sans 34.150.1.1
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [k8s-master kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 10.150.0.21 34.150.1.1]其中:
10.150.0.21- 为云主机的私有(内网) IP 地址,同时也是--apiserver-advertise-address,必须要有10.96.0.1- 为 Kubernetes 集群中 API Server 对应的 Service 的 ClusterIP,必须要有34.150.1.1- 为云主机的公网(弹性) IP,是本次要添加的 IP
如果还有其他 IP 或者域名,可以参照格式
--apiserver-cert-extra-sans 34.150.1.1添加。命令执行成功后,会生成新的证书。
$ ls apiserver*
apiserver.crt apiserver-etcd-client.key apiserver-kubelet-client.crt
apiserver-etcd-client.crt apiserver.key apiserver-kubelet-client.key重启 kubelet 服务
systemctl restart kubelet
验证
在远端服务器执行以下命令验证效果
$ rm -rf .kube/cache/
$ grep server .kube/config
server: https://34.150.1.1:6443
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane,master 6d6h v1.21.2
k8s-work1 Ready <none> 6d6h v1.21.2
k8s-work2 Ready <none> 6d6h v1.21.2
kubelet 启动失败
journalctl -u kubelet |
根据 kubelet 服务日志,导致失败的原因为系统启用了 swap,关闭 swap,重新启动正常
free -h |
集群证书未同步导致集群添加节点失败
环境信息
- kubeadm v1.32.2
使用以下 Configuration 创建的集群
参考文档: https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-config/ , https://kubernetes.io/docs/reference/config-api/kubeadm-config.v1beta4/ |
使用以下 JoinConfiguration 向集群中添加第二个 Master 节点
参考文档: https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-config/ , https://kubernetes.io/docs/reference/config-api/kubeadm-config.v1beta4/ |
执行以下命令将节点加入集群报错
kubeadm join --config ./ops_k8s_join_config.yaml |
根据错误信息可知是因为 集群证书未部署到新节点 ,可通过以下步骤解决:
- 在 Master 节点(初始化集群的节点)生成
certificateKey这个kubeadm certs certificate-key
41529138a1ed7c84af5af73093cece23737ae63fb5362696d77618dcertificateKey是用于 加密并自动分发 Kubernetes 证书 的密钥。 - 重新上传证书 。使用
kubeadm init phase upload-certs命令,将现有集群证书加密并上传:此操作会:kubeadm init phase upload-certs --upload-certs --certificate-key 41529138a1ed7c84af5af73093cece23737ae63fb5362696d77618d
[upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
41529138a1ed7c84af5af73093cece23737ae63fb5362696d77618d- 将
/etc/kubernetes/pki/下的 证书 加密后上传到kube-system命名空间的kubeadm-certsSecret 中 。kubectl get secret -A
NAMESPACE NAME TYPE DATA AGE
kube-system bootstrap-token-3cshhm bootstrap.kubernetes.io/token 4 2m12s
kube-system bootstrap-token-pc0io6 bootstrap.kubernetes.io/token 6 160m
kube-system kubeadm-certs Opaque 8 2m12s
kubernetes-dashboard kubernetes-dashboard-csrf Opaque 1 7d23h
kubernetes-dashboard sh.helm.release.v1.kubernetes-dashboard.v1 helm.sh/release.v1 1 7d23h - 其他 Control Plane 节点在加入时可以自动下载这些证书。
- 将
- 加入新的 Control Plane 节点 或使用以下
kubeadm join apiserver.k8s.ops:6443 --control-plane --token <你的 bootstrap token> \
--discovery-token-ca-cert-hash sha256:<你的 CA 证书哈希> \
--certificate-key 60f49c3fcb2a1c5e3e75e48aeda4dfb7c3a1c7b93baf1f6e3c9e5e45a6c7f4a5JoinConfiguration建议在 创建集群时自动上传证书,方便证书同步到新节点JoinConfiguration ---
apiVersion: kubeadm.k8s.io/v1beta4
kind: JoinConfiguration
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
controlPlane:
localAPIEndpoint:
advertiseAddress: <master node2 公网 IP>
bindPort: 6443
启用证书自动同步
certificateKey: "<你的证书密钥>"
discovery:
bootstrapToken:
apiServerEndpoint: apiserver.k8s.ops:6443
token: pc0io6.d5j7zap89plt467t # bootstrap token 和 CA Hash 使用命令 `kubeadm token create --print-join-command` 生成
caCertHashes:
- sha256:e16ebd4573d496c443c684637c21f3dccc569a71929e48a81515cfe43489c5f5InitConfiguration 参考文档: https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-config/ , https://kubernetes.io/docs/reference/config-api/kubeadm-config.v1beta4/
未明确指定的配置,kubeadm 会使用默认值,默认值可使用命令 `kubeadm config print init-defaults` 输出
apiVersion: kubeadm.k8s.io/v1beta4
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: <修改为 API Server 的监听 IP>
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
imagePullPolicy: IfNotPresent
imagePullSerial: true
name: node
taints: null
启用证书自动上传,证书密钥使用 `kubeadm certs certificate-key` 生成
certificateKey: "<你的证书密钥>"
节点名称不在 kube-apiserver 证书中导致添加节点失败
环境信息
- kubeadm v1.32.2
添加节点到集群报错:
kubeadm join --config ./ops_k8s_config/ops_k8s_join_config.yaml |
根据关键报错信息: error execution phase control-plane-prepare/certs: error creating PKI assets: failed to write or validate certificate "apiserver": certificate apiserver is invalid: x509: certificate is valid for apiserver.k8s.ops, kubernetes, kubernetes.default, kubernetes.default.svc, kubernetes.default.svc.cluster.local, k8s-master-1, not k8s-master-2 可知,错误是因为 新的节点名称 k8s-master-2 不在 kube-apiserver 证书的 SAN 列表中
可以参考以下解决方案更新 kube-apiserver 证书:
在主节点(
kubeadm init节点)上备份证书mkdir -p /opt/kubernetes/backup
cp -r /etc/kubernetes/pki/* /opt/kubernetes/backup/删除现有
apiserver证书rm -f /etc/kubernetes/pki/apiserver.crt /etc/kubernetes/pki/apiserver.key
使用
kubeadm init phase certs重新生成apiserver证书ClusterConfiguration ---
apiVersion: kubeadm.k8s.io/v1beta4
kind: ClusterConfiguration
kubernetesVersion: 1.32.0
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
apiServer:
apiserver 证书中的 SANs 列表
certSANs:
- "apiserver.k8s.ops"
- "kubernetes"
- "kubernetes.default"
- "kubernetes.default.svc"
- "kubernetes.default.svc.cluster.local"
- "<master-1 主机名称>"
- "<master-2 主机名称>" # 这里新增你的节点根据
ClusterConfiguration重新生成apiserver证书kubeadm init phase certs apiserver --config ./ops_k8s_config/k8s_kubeadm_init_config.yaml
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [apiserver.k8s.ops kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local <master-1 主机名称> <master-2 主机名称>] and IPs []重新上传证书
kubeadm certs certificate-key
a688533badf0e0631af433723d576a47297b131d479548d9afc8f97c5f237bb7
kubeadm init phase upload-certs --upload-certs --certificate-key a688533badf0e0631af433723d576a47297b131d479548d9afc8f97c5f237bb7
[upload-certs] Storing the certificates in Secret "kubeadm-certs" in the "kube-system" Namespace
[upload-certs] Using certificate key:
a688533badf0e0631af433723d576a47297b131d479548d9afc8f97c5f237bb7在
节点上更新节点的 JoinConfiguration配置并重新加入集群JoinConfiguration ---
apiVersion: kubeadm.k8s.io/v1beta4
kind: JoinConfiguration
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
controlPlane:
localAPIEndpoint:
advertiseAddress: <修改为 API Server 的监听 IP>
bindPort: 6443
certificateKey: "a688533badf0e0631af433723d576a47297b131d479548d9afc8f97c5f237bb7"
discovery:
bootstrapToken:
apiServerEndpoint: apiserver.k8s.ops:6443
token: pc0io6.d5j7zap89plt467t
caCertHashes:
- sha256:e16ebd4573d496c443c684637c21f3dccc569a71929e48a81515cfe43489c5f5(删除旧的证书)成功加入集群
rm -rf /etc/kubernetes/pki/*
kubeadm join --config ./ops_k8s_config/ops_k8s_join_config.yaml
etcd 使用了 http 协议导致添加节点失败
环境信息
- kubeadm v1.32.2
集群初始化使用以下 Configuration
参考文档: https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-config/ , https://kubernetes.io/docs/reference/config-api/kubeadm-config.v1beta4/ |
使用以下 Configuration 加入新的管理节点到集群
参考文档: https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-config/ , https://kubernetes.io/docs/reference/config-api/kubeadm-config.v1beta4/ |
加入集群报错:
kubeadm join --v=5 --config ./ops_k8s_join_config.yaml |
关键错误信息: etcd endpoints read from pods: https://<master node1 公网 IP>:2379 context deadline exceeded, error syncing endpoints with etcd,可知问题主要出现在 etcd 集群上,接着检查 etcd 集群的状态
在 <master node1> 上检查 etcd 发现 etcd 监听在 http 协议,而不是 https 协议,加入新节点到集群默认使用 HTTPS 协议连接 etcd 集群
kubectl exec -n kube-system -it <master node1> -- sh -c "ETCDCTL_API=3 etcdctl endpoint status --endpoints=http://127.0.0.1:2379" |
检查初始化集群使用的 etcd 配置发现初始化时,etcd 使用了 HTTP 协议监听,而不是 HTTPS
etcd: |
在 Kubernetes 中,要将 etcd 的监听协议由 HTTP 改为 HTTPS,可以参考以下步骤:
确保
etcd所需证书已经存在,如不存在,重新生成相关证书ls -l /etc/kubernetes/pki/etcd/
total 32
-rw-r--r-- 1 root root 1094 Mar 3 16:09 ca.crt
-rw------- 1 root root 1679 Mar 3 16:09 ca.key
-rw-r--r-- 1 root root 1123 Mar 3 16:09 healthcheck-client.crt
-rw------- 1 root root 1675 Mar 3 16:09 healthcheck-client.key
-rw-r--r-- 1 root root 1212 Mar 3 16:09 peer.crt
-rw------- 1 root root 1679 Mar 3 16:09 peer.key
-rw-r--r-- 1 root root 1212 Mar 3 16:09 server.crt
-rw------- 1 root root 1679 Mar 3 16:09 server.key
# 如果不存在证书,使用以下命令生成证书
kubeadm init phase certs etcd-ca
kubeadm init phase certs etcd-server
kubeadm init phase certs etcd-peer
# 然后重新上传
kubeadm init phase upload-certs --upload-certs --certificate-key <你的证书密钥>修改
etcd静态 Pod 配置(vim /etc/kubernetes/manifests/etcd.yaml) ,确保监听协议使用 HTTPS/etc/kubernetes/manifests/etcd.yaml apiVersion: v1
kind: Pod
metadata:
annotations:
kubeadm.kubernetes.io/etcd.advertise-client-urls: https://<公网 IP>:2379
creationTimestamp: null
labels:
component: etcd
tier: control-plane
name: etcd
namespace: kube-system
spec:
containers:
- command:
- etcd
- --advertise-client-urls=https://<公网 IP>:2379
- --cert-file=/etc/kubernetes/pki/etcd/server.crt
- --client-cert-auth=true
- --data-dir=/var/lib/etcd
- --experimental-initial-corrupt-check=true
- --experimental-watch-progress-notify-interval=5s
- --initial-advertise-peer-urls=https://<公网 IP>:2380
- --initial-cluster=qqc-bw-js-ngx=https://<公网 IP>:2380
- --key-file=/etc/kubernetes/pki/etcd/server.key
- --listen-client-urls=https://0.0.0.0:2379
- --listen-metrics-urls=http://127.0.0.1:2381
- --listen-peer-urls=https://0.0.0.0:2380
- --name=qqc-bw-js-ngx
- --peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
- --peer-client-cert-auth=true
- --peer-key-file=/etc/kubernetes/pki/etcd/peer.key
- --peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
- --snapshot-count=10000
- --trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt--listen-metrics-urls=http://127.0.0.1:2381要使用 HTTP 协议,否则会导致etcd容器因健康检查失败一直重启修改
kube-apiserver静态 Pod 配置(/etc/kubernetes/manifests/kube-apiserver.yaml) ,确保kube-apiserver使用 HTTPS 协议连接etcd/etc/kubernetes/manifests/kube-apiserver.yaml - --etcd-servers=https://<公网 IP>:2379
重启
kubelet服务
kube-proxy 失败
环境信息
- CentOS Linux 7 5.15.80-200.el7.x86_64
- kubeadm v1.32.3
- containerd v2.0.0
- runc spec: 1.0.1-dev
将节点作为管理节点加入集群后,新节点上的 Pod kube-proxy 一直处于重启状态,检查 Pod 状态信息如下:
kubectl describe pod -n kube-system kube-proxy-g7vln |
关键错误信息: failed to create containerd task: failed to create shim task: OCI runtime create failed: container_linux.go:349: starting container process caused "unknown capability \"CAP_PERFMON\""
CAP_PERFMON 是一个较新的 Linux 能力,用于性能监控相关的操作。它是在 Linux 内核 5.8 版本中引入的。如果你的节点内核版本低于 5.8,或者容器运行时(如 containerd 或 runc)版本较旧,可能无法识别 CAP_PERFMON ,从而导致容器启动失败。
本节点内核版本 5.15.80-200.el7.x86_64 ,符合要求。 containerd 已是当前最新版本 v2.0.0, runc 版本为 1.0.1-dev ,属于较旧版本,如果版本低于 1.1.11 ,需要升级 。执行以下命令升级 runc
VERSION=$(curl -s https://api.github.com/repos/opencontainers/runc/releases/latest | grep tag_name | cut -d '"' -f 4) |
然后重新启动 containerd
sudo systemctl restart containerd |
升级 runc 到最新版本(1.3.0-rc.1)后,kube-proxy 状态正常。
etcd 节点加入 etcd 集群失败
新的 etcd 节点未正确的加入到 etcd 集群中,检查日志信息如下:
nerdctl logs 979519e94b9c |
关键报错信息: "discovery failed","error":"couldn't find local name \"<新 etcd 节点名称>\" in the initial cluster configuration",表示新的节点名称未加入 etcd 的 initial-cluster 中。检查新节点上的 etcd 静态 Pod 配置(/etc/kubernetes/manifests/etcd.yaml)发现新节点的信息不存在,添加新的节点信息即可
--initial-cluster=k8s-master-1=https://<k8s-master-1 IP>:2380,k8s-master-2=https://<k8s-master-2 IP>:2380,<新 etcd 节点名称>=https://<新 etcd 节点 IP>:2380 |
其他常用配置
新增节点
要为集群新增 worker 节点,参考以下步骤
- 加入前准备工作
参考安装步骤,配置新节点 - 在集群的 master 节点执行以下命令,获取加入集群的命令
kubeadm token create --print-join-command
kubeadm join cluster:6443 --token cuxvrexi24aejb --discovery-token-ca-cert-hash sha256:9e5b71bc392 - 在新节点上执行加入集群的命令
kubeadm join cluster:6443 --token cuxvrexi24aejb --discovery-token-ca-cert-hash sha256:9e5b71bc392
将 CRI 由 containerd 变更为 Docker
编辑 /var/lib/kubelet/kubeadm-flags.env 文件,在该文件中可以添加 kubelet 启动参数,将 --container-runtime-endpoint 标志,设置为 unix:///var/run/cri-dockerd.sock [1]
KUBELET_KUBEADM_ARGS="--container-runtime=remote --container-runtime-endpoint=unix:///var/run/cri-dockerd.sock --pod-infra-container-image=registry.k8s.io/pause:3.8" |
kubeadm 工具将节点上的套接字存储为控制面上 Node 对象的注解。 要为每个被影响的节点更改此套接字:
- 编辑 Node 对象的 YAML 表示:
KUBECONFIG=/path/to/admin.conf kubectl edit no <NODE_NAME>
/path/to/admin.conf:指向kubectl配置文件admin.conf的路径;<NODE_NAME>:你要修改的节点的名称。
- 将
kubeadm.alpha.kubernetes.io/cri-socket标志更改为unix:///var/run/cri-dockerd.sock;
配置完成后,重启 kubelet
systemctl daemon-reload |
查看 node 使用的 CRI
kubectl get nodes -o wide |
修改 kubelet 使用的 CRI 为 containerd
修改之前,kubelet 使用的 CRI 为 cri-docker。修改步骤如下
修改 kubelet 配置及相关节点配置。
编辑相关节点上的 kubelet 配置文件
/var/lib/kubelet/kubeadm-flags.env修改--container-runtime-endpoint为containerd的 socket 地址/var/lib/kubelet/kubeadm-flags.env --container-runtime-endpoint=unix:///run/containerd/containerd.sock
在 Master 节点上,执行以下命令,编辑相关节点配置,修改配置
kubeadm.alpha.kubernetes.io/cri-socket: unix:///run/containerd/containerd.sock[9]kubectl edit node master2
kubeadm.alpha.kubernetes.io/cri-socket: unix:///run/containerd/containerd.sock重启相关服务,无需使用
docker时可停止docker服务systemctl daemon-reload && systemctl restart containerd && systemctl restart kubelet
如果启动
kubelet失败,报错误:Error: failed to run Kubelet: failed to create kubelet: get remote runtime typed version failed: rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService,删除containerd的默认配置文件/etc/containerd/config.toml后,重新启动 [10]rm -rf /etc/containerd/config.toml
修改 Service 可使用的 nodePort 端口范围
默认情况下,Service 中可使用的 nodePort 端口的默认范围为 30000-32767,要修改此配置,参考以下步骤。
Master 节点上编辑 kube-apiserver 的 Pod 配置文件 /etc/kubernetes/manifests/kube-apiserver.yaml,在 .spec.containers.command 下添加以下内容
- --service-node-port-range=1-65535 |
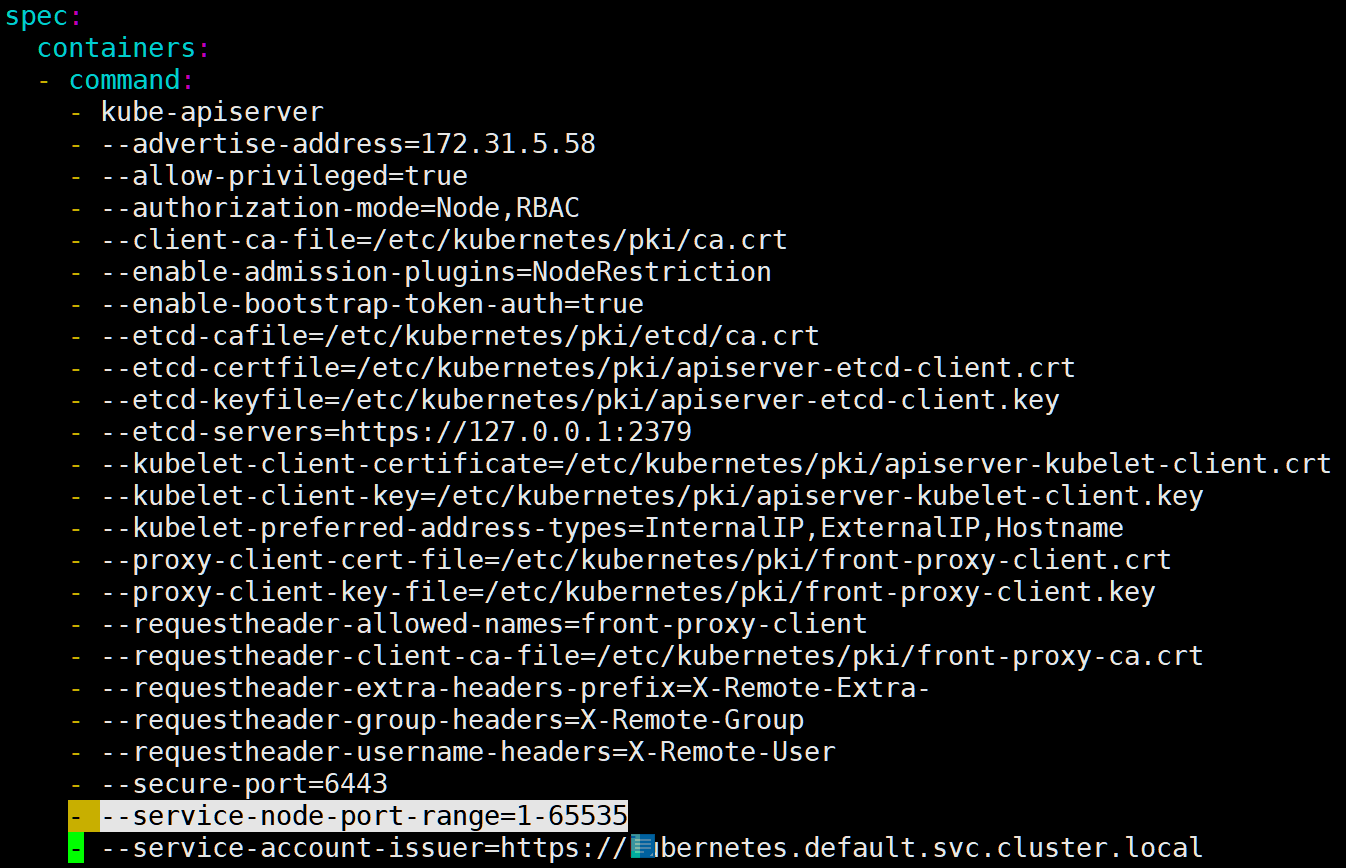
apiserver 是以静态 Pod 的形式运行,/etc/kubernetes/manifests 目录下是所有静态 Pod 文件的定义,kubelet 会监控该目录下文件的变动,只要发生变化,Pod 就会重建,响应相应的改动。所以我们修改 /etc/kubernetes/manifests/kube-apiserver.yaml 文件,添加 nodePort 范围参数后会自动生效,无需进行其他操作
高可用场景下,所有 Master 节点上都要修改,否则可能遇到部分时候依然报错: nodePort: Invalid value: 65500: provided port is not in the valid range. The range of valid ports is 30000-32767
开启 corndns 日志记录
默认的 coredns 配置没有开启日志插件,这导致 kubernetes 集群中一些 dns 解析超时问题难以定位。要打开 coredns 的日志功能,可以通过以下命令开启日志功能
kubectl edit configmap -n kube-system coredns |
添加以下配置: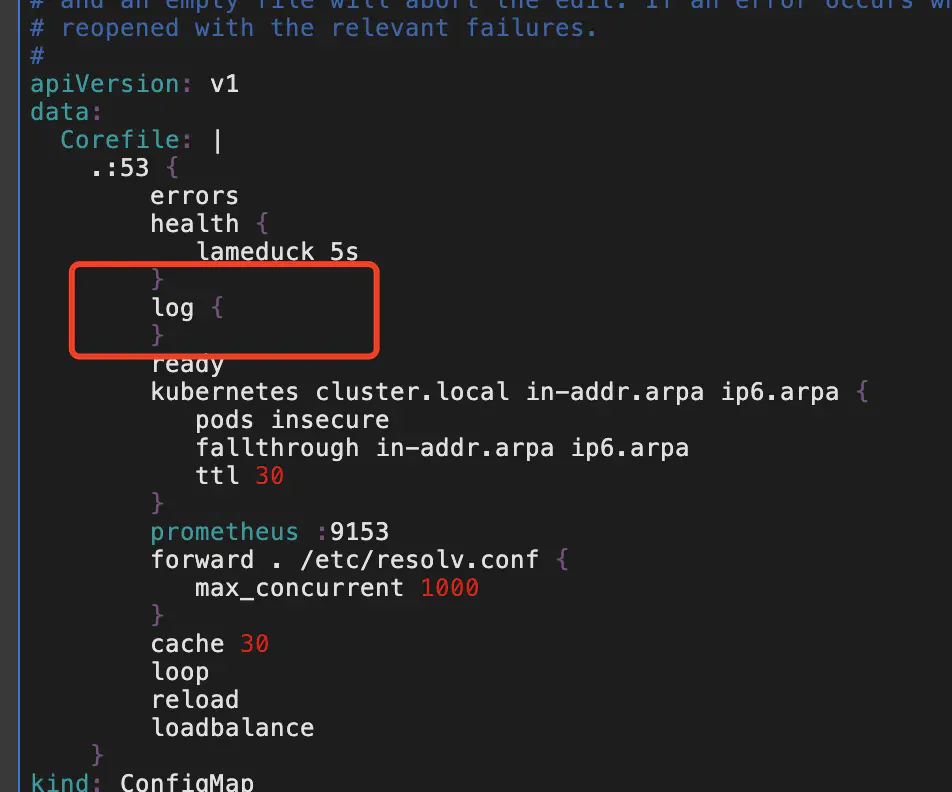
接下来我们再使用命令查看日志,就可以看到 dns 解析的记录,无需重启 coredns
kubectl logs -f -n kube-system coredns-558bd4d5db-z6mst |
升级 cri-dockerd
如果需要升级 cri-dockerd 版本,可以执行以下操作,如果之前的安装目录还在,则直接 git pull 更新代码,否则 clone 代码 [11]
cd cri-dockerd |
添加 Harbor 私有镜像仓库的认证信息
在命令行上提供凭证来创建 Secret [3]
kubectl create secret docker-registry ${secretname} \ |
<your-registry-server>是你的私有 Docker 仓库全限定域名(FQDN)。 DockerHub 使用https://index.docker.io/v1/。<your-name>是你的 Docker 用户名。<your-pword>是你的 Docker 密码。<your-email>是你的 Docker 邮箱。
这样你就成功地将集群中的 Docker 凭证设置为名为 ${secretname} 的 Secret。
Secret 属于 namespace 级别的资源,不能跨 namespace 使用。
检查创建的 Secret
kubectl get secret ${secretname} --output=yaml |
.dockerconfigjson 字段的值是 Docker 凭证的 base64 表示。要了解 dockerconfigjson 字段中的内容,请将 Secret 数据转换为可读格式:
kubectl get secret ${secretname} --output="jsonpath={.data.\.dockerconfigjson}" | base64 --decode |
配置 Pod 拉取镜像的认证信息
kubectl get secret -n frtg |
在 namespace 中配置了镜像仓库的 Secret 后,可以使用以下方法配置 Pod 拉取镜像时的认证信息
在 Pod 的配置中使用
imagePullSecrets指令,此种方式需要在每个 Pod 的配置中添加apiVersion: v1
kind: Pod
metadata:
name: ${NAME}
namespace: ${NAMESPACE}
spec:
restartPolicy: Always
containers:
- name: ${NAME}
image: nginx:1.14.2
ports:
- containerPort: 80
name: http-web
imagePullSecrets:
- name: ${secret_name}通过 ServiceAccount 配置
每个 namespace 都有个默认的 ServiceAccount,namespace 中的所有 Pod 默认情况下都会关联到此 ServiceAccount,ServiceAccount 的配置中包含了
Image pull secrets,在 ServiceAccount 中添加的镜像拉取密钥,会自动添加到所有使用这个 ServiceAccount 的 Pod 中。因此,向 ServiceAccount 中添加镜像拉取密钥可以不必对每个 Pod 都单独进行镜像拉取密钥的配置。 [8]执行命令
kubectl edit serviceaccount default编辑默认的 ServiceAccount,删掉包含resourceVersion主键的行,添加包含imagePullSecrets:的行并保存文件apiVersion: v1
kind: ServiceAccount
metadata:
creationTimestamp: "2022-12-06T09:51:03Z"
name: default
namespace: default
uid: b219bafc-e2f9-48bb-a9e4-6e0bfb4ab536
imagePullSecrets:
- name: harbor1.1dergegh.com
Pod 添加 hosts
有时需要在启动 Pod 时为其 /etc/hosts 中添加解析,以覆盖对主机名的解析,此时可以通过 PodSpec 的 HostAliases 字段来 添加这些自定义条目 [4]
apiVersion: v1 |
配置 Pod 中的时区和时间
通常情况下,我们的环境中,宿主机都是配置为 CST 时间(东八区),而使用的基础镜像中的默认时间都是 UTC 时间,而不是本地时间,通常需要确保系统中所有的时间格式一致,需将容器中的时间也修改为 CST 时间。
为此可使用以下方法中的一种来实现
在 Dockerfile 中添加时区
# Set timezone
RUN ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime \
&& echo "Asia/Shanghai" > /etc/timezone将时区文件挂载到 Pod 中
在定义 Pod 上层控制器的时候,添加一个用于挂载时区的卷,挂载宿主机的时区文件
...
containers:
- name: xxx
...
volumeMounts:
- name: timezone
mountPath: /etc/localtime
volumes:
- name: timezone
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai通过环境变量定义时区
在定义 Pod 上层控制器的时候,添加一个用于指定时区的环境变量
TZ环境变量用于设置时区。它由各种时间函数用于计算相对于全球标准时间 UTC(以前称为格林威治标准时间 GMT)的时间。格式由操作系统指定...
containers:
- name: xxx
...
env:
- name: TZ
value: Asia/Shanghai
配置节点允许启动的最大 Pod 数
在 K8S 集群中,默认每个 Worker 节点最大可创建 110 个 Pod,实际可以根据节点资源情况调整范围。
在 Woker 节点上,可创建的最大的 Pod 数量是作为 Kubelet 的启动参数出现的,因此修改 Kubelet 服务的配置文件增加 --max-pod 参数即可。
修改 kubelet 服务的启动文件 /usr/lib/systemd/system/kubelet.service.d/10-kubeadm.conf,添加以下环境变量
Environment="KUBELET_NODE_MAX_PODS=--max-pods=200" |
将新加的环境变量追加到 /usr/bin/kubelet 中
Note: This dropin only works with kubeadm and kubelet v1.11+ |
重置集群
要重置集群配置,可以参考以下步骤 [7]
kubeadm reset --cri-socket=unix:///var/run/cri-dockerd.sock |
部署 kube-state-metrics 组件
kube-state-metrics 是一个用于导出 Kubernetes 集群的资源状态指标的开源项目,通过监听 API Server 生成有关资源对象(如 Deployment、Node、Pod)的状态指标,需要注意的是 kube-state-metrics 只是简单的提供一个 metrics 数据,并不会存储这些指标数据,所以我们可以使用 Prometheus 来抓取这些数据然后存储,主要关注的是业务相关的一些元数据,比如 Deployment、Pod、RepliSet 的状态等指标。
下载链接 下载对应版本的部署文件
wget https://github.com/kubernetes/kube-state-metrics/archive/refs/tags/v2.6.0.tar.gz |
参考以上步骤部署后,会生成 kube-state-metrics 所需要的资源:ClusterRole、ClusterRoleBinding、ServiceAccount、Deployment、Service
部署成功后,查看生成的 Service,会看到是一个 Headless 的服务
kubectl get services -n kube-system |
登陆一个 Pod,尝试在 Pod 中访问 kube-state-metrics 提供 Metrics 的 url (kube-state-metrics.kube-system.svc.cluster.local:8080/metrics)。对应的 Service 的 FQDN 为 kube-state-metrics.kube-system.svc.cluster.local,查看其解析,根据 Headless Service 的原理,会解析成 kube-state-metrics 的 Pod 的 IP。正常情况下会获取到 kube-state-metrics 监控的指标数据。
ping kube-state-metrics.kube-system.svc.cluster.local |
集群证书过期后的处理步骤
假如集群 TLS 证书过期或者需要更新,可以参考以下步骤更新
确定集群证书状态
kubeadm certs check-expiration
[check-expiration] Reading configuration from the cluster...
[check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[check-expiration] Error reading configuration from the Cluster. Falling back to default configuration
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Sep 26, 2023 01:43 UTC <invalid> no
apiserver Sep 26, 2023 01:43 UTC <invalid> ca no
apiserver-etcd-client Sep 26, 2023 01:43 UTC <invalid> etcd-ca no
apiserver-kubelet-client Sep 26, 2023 01:43 UTC <invalid> ca no
controller-manager.conf Sep 26, 2023 01:43 UTC <invalid> no
etcd-healthcheck-client Sep 26, 2023 01:43 UTC <invalid> etcd-ca no
etcd-peer Sep 26, 2023 01:43 UTC <invalid> etcd-ca no
etcd-server Sep 26, 2023 01:43 UTC <invalid> etcd-ca no
front-proxy-client Sep 26, 2023 01:43 UTC <invalid> front-proxy-ca no
scheduler.conf Sep 26, 2023 01:43 UTC <invalid> no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Sep 23, 2032 01:43 UTC 8y no
etcd-ca Sep 23, 2032 01:43 UTC 8y no
front-proxy-ca Sep 23, 2032 01:43 UTC 8y no备份集群证书。
备份/etc/kubernetes/目录,确保在任何出现问题的情况下都可以恢复sudo cp -r /etc/kubernetes /etc/kubernetes-backup
在每个 Master 节点上更新证书
- 更新单个证书。如果只想更新特定的证书,可以使用
kubeadm alpha certs renew命令。例如,要更新apiserver的证书,可以执行:sudo kubeadm certs renew apiserver
- 更新所有证书
# kubeadm certs renew all
[renew] Reading configuration from the cluster...
[renew] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
[renew] Error reading configuration from the Cluster. Falling back to default configuration
certificate embedded in the kubeconfig file for the admin to use and for kubeadm itself renewed
certificate for serving the Kubernetes API renewed
certificate the apiserver uses to access etcd renewed
certificate for the API server to connect to kubelet renewed
certificate embedded in the kubeconfig file for the controller manager to use renewed
certificate for liveness probes to healthcheck etcd renewed
certificate for etcd nodes to communicate with each other renewed
certificate for serving etcd renewed
certificate for the front proxy client renewed
certificate embedded in the kubeconfig file for the scheduler manager to use renewed
Done renewing certificates. You must restart the kube-apiserver, kube-controller-manager, kube-scheduler and etcd, so that they can use the new certificates.
- 更新单个证书。如果只想更新特定的证书,可以使用
重启所有节点上的
kubelet服务,以及kube-controller-manager,kube-scheduler,kube-apiserver确定集群证书状态
kubeadm certs check-expiration
[check-expiration] Reading configuration from the cluster...
[check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Sep 26, 2024 09:45 UTC 364d no
apiserver Sep 26, 2024 09:45 UTC 364d ca no
apiserver-etcd-client Sep 26, 2024 09:45 UTC 364d etcd-ca no
apiserver-kubelet-client Sep 26, 2024 09:45 UTC 364d ca no
controller-manager.conf Sep 26, 2024 09:45 UTC 364d no
etcd-healthcheck-client Sep 26, 2024 09:45 UTC 364d etcd-ca no
etcd-peer Sep 26, 2024 09:45 UTC 364d etcd-ca no
etcd-server Sep 26, 2024 09:45 UTC 364d etcd-ca no
front-proxy-client Sep 26, 2024 09:45 UTC 364d front-proxy-ca no
scheduler.conf Sep 26, 2024 09:45 UTC 364d no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Sep 23, 2032 01:43 UTC 8y no
etcd-ca Sep 23, 2032 01:43 UTC 8y no
front-proxy-ca Sep 23, 2032 01:43 UTC 8y no如果集群证书更新后,Pod 内需要使用到集群证书,如果需要立即更新证书,需要重启节点上的
kubelet服务,否则如果未重启节点上的kubelet服务,即使重启 Pod,Pod 使用的依旧是未更新的证书
基于公网的 Kubernetes 集群部署注意事项
以下部分列出在部署基于公网 IP( 如基于跨区域云主机,云主机上的网卡只有内网地址,未绑定公网 IP )的集群时所需的注意事项, 使用公网 IP 通信而非内网通信,会产生较高的延迟,可能会导致如 etcd 集群不稳定 ,如非特殊场景,建议使用内网部署集群。
etcd 集群使用公网 IP 通信
要创建基于公网或者指定 IP 的 etcd 集群,可以使用以下配置 初始化 Kubernetes 集群
参考文档: https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-config/ , https://kubernetes.io/docs/reference/config-api/kubeadm-config.v1beta4/ |
关键配置说明 :
advertiseAddress:kube-apiserver向其他节点通告的 IP,apiVersion: kubeadm.k8s.io/v1beta4
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: <修改为 API Server 的公网 IP>
bindPort: 6443etcd配置,指定etcd节点的通告地址为 公网 IPapiVersion: kubeadm.k8s.io/v1beta4
kind: ClusterConfiguration
kubernetesVersion: 1.32.0
如果需要自定义 etcd 监听地址,使用以下参数,如使用公网 IP,具体参数说明请参考 etcd 文档: https://github.com/etcd-io/etcd/blob/main/etcd.conf.yml.sample
新增 Master 节点时,需直接修改 `/etc/kubernetes/manifests/etcd.yaml`
etcd:
local:
extraArgs:
- name: "listen-peer-urls"
value: "https://0.0.0.0:2380"
- name: "listen-client-urls"
value: "https://0.0.0.0:2379"
- name: "advertise-client-urls"
value: "https://<公网 IP>:2379"
- name: "initial-advertise-peer-urls"
value: "https://<公网 IP>:2380"
- name: "initial-cluster"
value: "<master node name>=https://<公网 IP>:2380"
flanneld Tunnel IP 配置
默认情况下,flanneld 使用 kube subnet manager 模式,即使用 Kubernetes API 作为其后端存储,获取节点以及其 Pod Subnet 信息。 Kubernetes 中 flannel 相关配置
flanneld 会从 Node 的 Annotations 中读取节点的 Tunnel IP 信息
kubectl describe node k8s-master-1 |
关键 Annotations(注释信息)包括:
flannel.alpha.coreos.com/backend-type:Flanneld使用的后端(Backend)网络技术类型,默认为vxlanflannel.alpha.coreos.com/kube-subnet-manager: 是否使用 Kubernetes API 作为 Flanneld 的后端存储,默认为True,即使用 kube subnet managerflannel.alpha.coreos.com/public-ip: 默认检测到的节点 出口 IP (如云服务器,即为其内网 IP),默认使用此 IP 作为本 Node 的 Tunnel 端 IPflannel.alpha.coreos.com/public-ip-overwrite: 当 Flanneld 使用的 IP(即 Tunnel 端 IP)没有绑定在本机网卡,典型例子为云主机场景(使用 NAT 实现公私网地址转换),Flanneld 需要使用公网地址通信时,可以使用此 Annotation 强制指定 Flannel Tunnel 的本端 IP 地址flannel.alpha.coreos.com/node-public-ip: 如果节点的 Tunnel IP 已经配置在节点的某个网络接口上(例如节点有多个接口)时使用
在基于公网 IP 的集群中,默认情况下,云主机只绑定了内网 IP, flanneld 将使用节点的内网 IP 作为其 Tunnel 地址和其他节点通信,因内网地址和其他节点的地址不互通,会导致节点上的 Pod 之间无法通信。 为了使跨节点的 Pod 可以正常通信,需要使 flanneld 使用节点的公网 IP 作为 Tunnel 端 IP
在此场景下, 需要修改各个 Node 的配置,强制指定 flanneld 使用公网 IP 作为 Tunnel 端地址
kubectl edit node k8s-master-1 |
kubelet 配置
默认情况下,kubelet 将使用本机绑定的 IP 向集群上报(注册)本节点的信息,在云主机的场景下,其通常为内网 IP 。 kubelet 要求 --node-ip (上报/注册的节点 IP) 必须存在于主机的网络接口中,否则会拒绝启动或更新节点状态。
kubectl get nodes -o wide |
如果使用 kubelet --node-ip 配置公网 IP,而公网 IP 未在本地网卡绑定,kubelet 服务会报错 :
journalctl -u kubelet | grep -i "Node IP" |
在此场景下,如果要在 Master 节点上连接到其他节点上的 Pod 或者查看其日志信息会报错:
kubectl get pods -A -o wide |
此问题原因 :
- 节点注册的 IP 不可达 :
kubelet默认使用内网 IP 注册到 Kubernetes API Server。 kube-apiserver的 IP 选择策略 : 默认优先使用 InternalIP,而非公网 IP(EIP)。
解决方案如下 :
在节点上绑定公网 IP 。因为
kubelet会验证注册的 IP 地址是否绑定在本地网卡上,而云主机场景下的公网 IP 并未绑定到网卡,如果配置kubelet注册的 IP 为公网 IP,kubelet会报错并继续使用内网 IP 注册,参考以下命令将公网 IP 绑定到本地网卡ip addr add 54.219.215.136/32 dev eth0
ip addr add只是临时添加 IP,重启服务器后会丢失。如果想永久生效,需要写入网络配置文件配置 kube-apiserver 优先使用 ExternalIP
修改控制平面节点的
kube-apiserver启动参数,使其优先选择 ExternalIP- 编辑
kube-apiserver的 Manifest 文件(/etc/kubernetes/manifests/kube-apiserver.yaml),添加或修改--kubelet-preferred-address-types参数kube-apiserver 会自动重启(无需手动操作) 。spec:
containers:
- command:
- kube-apiserver
- --kubelet-preferred-address-types=ExternalIP,InternalIP,Hostname # 将 ExternalIP 放在最前
...
- 编辑
检查节点注册信息
kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-master-1 Ready control-plane 3d16h v1.32.3 111.111.112.35 <none> Ubuntu 24.04.2 LTS 6.11.0-19-generic containerd://1.7.25
k8s-master-2 Ready control-plane 5d19h v1.32.2 111.111.112.36 <none> Rocky Linux 8.10 (Green Obsidian) 6.13.5-1.el8.elrepo.x86_64 containerd://1.6.32
k8s-master-3 Ready control-plane 4d21h v1.32.3 111.111.112.37 <none> CentOS Linux 7 (Core) 5.15.80-200.el7.x86_64 containerd://2.0.0如果节点注册的公网 IP 不对,可修改对应节点的
kubelet配置(/var/lib/kubelet/config.yaml),指定注册的公网 IP/var/lib/kubelet/config.yaml nodeIP: 54.219.215.136
参考链接
Kubernetes 官网文档
cri-dockerd 安装链接
Centos7 集群部署k8s 版本v1.17.4及Dashboard
kubernetes-dashboard 配置官网说明
部署和访问 Kubernetes 仪表板(Dashboard)
脚注
- 1.配置 kubelet 使用 cri-dockerd ↩
- 2.为 kube-apiserver 创建负载均衡器 ↩
- 3.在命令行上提供凭证来创建 Secret ↩
- 4.使用 HostAliases 向 Pod /etc/hosts 文件添加条目 ↩
- 5.Kubernetes Metrics Server ↩
- 6.端口和协议 ↩
- 7.清理 ↩
- 8.为服务账号添加 ImagePullSecrets ↩
- 9.配置 kubelet 使用 containerd 作为其容器运行时 ↩
- 10.Kubeadm unknown service runtime.v1alpha2.RuntimeService ↩
- 11.cri-dockerd 安装链接 ↩
- 12.Manual certificate distribution ↩
- 13.About cgroup v2 ↩
- 14.User Namespaces ↩
- 15.Deploy and Access the Kubernetes Dashboard ↩